Apache Iceberg™ on Quanton: 3x Faster Apache Spark™ workloads

TL;DR
At Onehouse, we've spent years pushing the boundaries of performance for open table formats, starting from our roots, building the first data lakehouse and arguably the fastest storage engine for the data lakehouse. Earlier this summer, we announced our new native query execution engine, Quanton, with comprehensive benchmarks that prove industry-leading ETL price-performance. Today, we are excited to extend our novel innovations to Apache Iceberg workloads for Apache Spark.
Since the launch of Quanton, we have collaborated with several customers who rely exclusively on Iceberg, but are struggling on performance with Iceberg’s known limitations and generally slower performance. It became apparent that our Iceberg users could benefit the most from Quanton, which is tailored to accelerate ETL across open formats. We've proven its impact on Apache Hudi, and now Iceberg users can tap into that same speed with no changes to their workflows. If you are a Databricks user wondering about Delta Lake: “Yes. Delta Lake will be up next. But shouldn’t you already be on Iceberg? ;)”.
Let’s dive in …
How Quanton pushes Iceberg Performance to New Heights
Let’s start by discussing what Quanton is and why it is unique. Quanton represents a purposeful evolution in lakehouse execution engines, designed to accelerate ETL workloads across open table formats like Apache Iceberg. Quanton innovates where it matters without disrupting the familiar interfaces that data engineers rely on. The Apache Spark APIs and the familiar SQL syntax remain untouched, preserving the standard entry point for writing jobs and queries, ensuring seamless compatibility with existing workloads. Similarly, at the base, open table formats like Apache Iceberg stay intact (with both its strengths and weaknesses), maintaining the protocol for data read/write operations, schema evolution, and ACID guarantees that define storage semantics. Quanton's breakthroughs target the middle layers of the diagram below, the execution runtime and the storage engine, where traditional Spark often falters in efficiency.
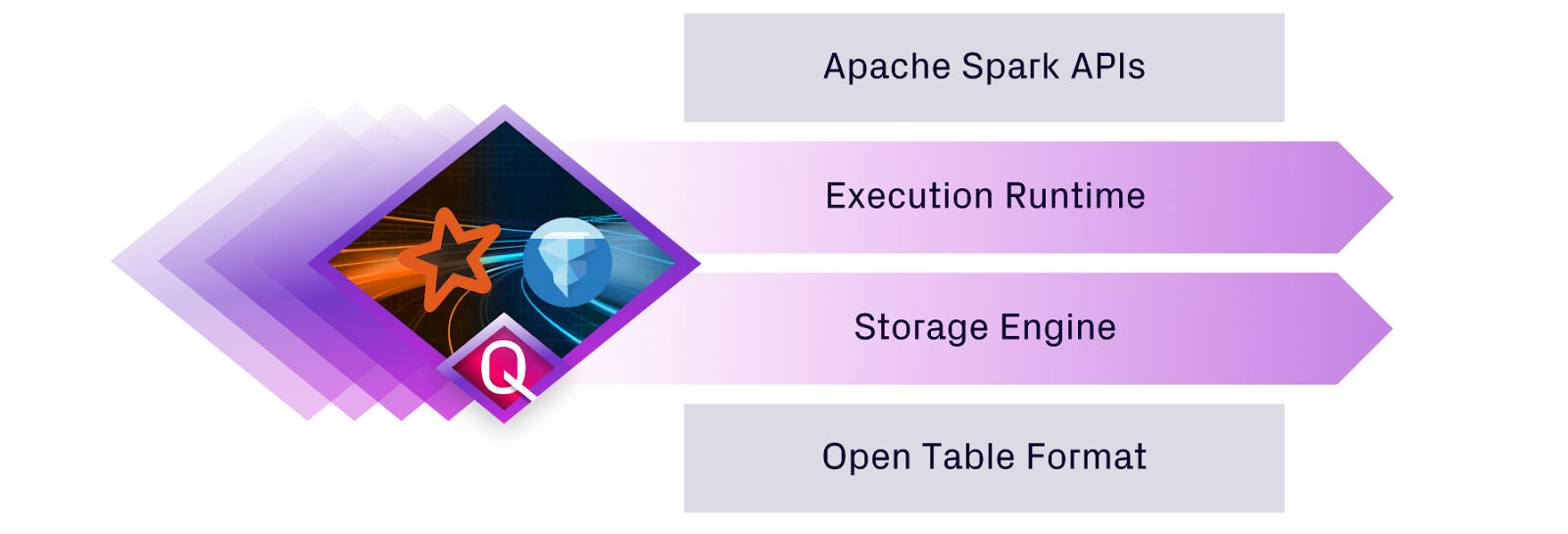
Execution Runtime Accelerations
The most common operations in a data lakehouse include reading an existing object/file from cloud storage, compressing/decompressing, serializing/deserializing, merging changes, indexing lookups and writing it back to cloud storage. We have customized the I/O path for high-throughput data scanning that can prefetch and decode files in parallel, maximizing use of cloud storage bandwidth and minimizing I/O stalls. Quanton applies ETL-specific enhancements, such as reduced shuffle partitions for incremental jobs and adaptive executor scheduling for variable loads.
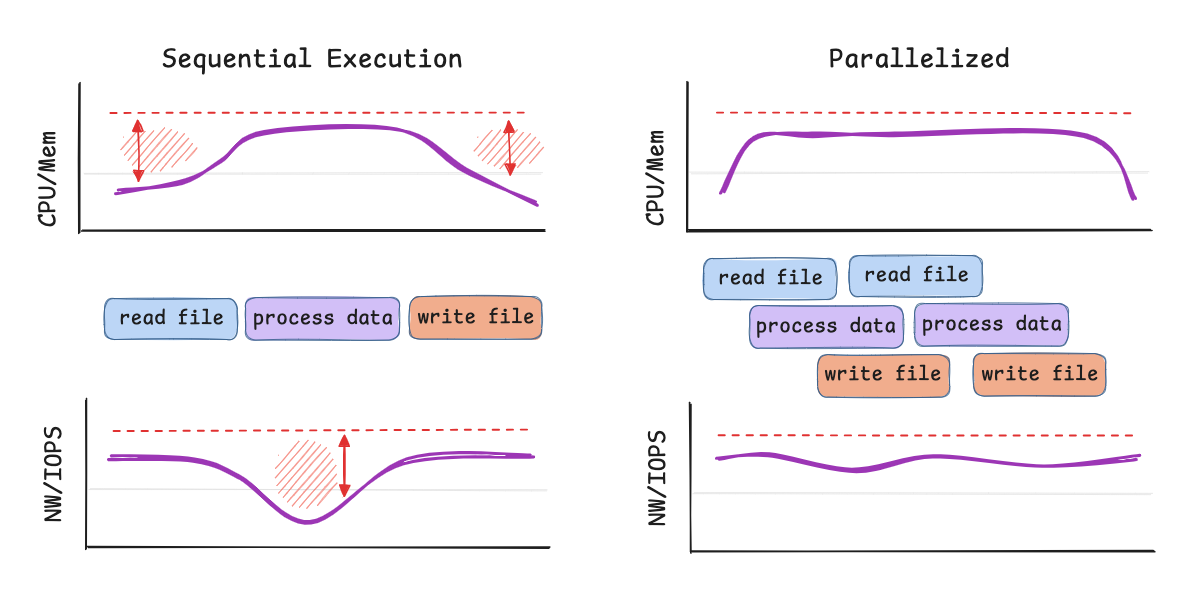
Quanton delivers superior speed through low-level hardware optimizations. One example of the techniques used in the execution runtime leverages SIMD vectorized execution that processes columnar data in batches, transforming filters, aggregations, and projections into parallel operations that exploit modern CPU capabilities. This eliminates the bottlenecks of scalar loops, delivering massive throughput for scan-intensive tasks.
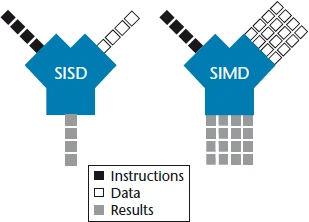
Data engineers familiar with the latest OSS trends might initially wonder if Quanton is just another integration of frameworks like Apache Gluten™, Apache DataFusion™ Comet™, Velox, etc, which is the approach some companies are taking like Microsoft Fabric, DataProc Lightning, IBM Watson and more coming soon. Quanton’s performance is not the result of a simple bolt-on and the benchmarks later in the blog will show you that clear distinction.
Storage Engine Optimizations
Quanton accelerated Iceberg pipelines achieve superior results not just with compute-efficiency optimizations, but Quanton is also specialized for the repetitive, data-intensive nature of ETL in the lakehouse. Deeper storage-aware optimizations integrate closely with Iceberg's metadata, pruning partitions and row groups, reducing the amount of data processed.

This accelerates joins, filters, and updates, reducing unnecessary data movement. Quanton amortizes execution costs by recognizing patterns like stable target table schemas and recurring SQL plans, caching metadata, indexing data and reusing intermediates along with data structures like Bloom filters or min-max indexes across runs. For instance, in pipelines with temporal partitioning or CDC feeds, it automatically rewrites batch queries into incremental operations, slashing full scans to delta merges and cutting data processing by orders of magnitude.
These smarts extend to proactive, background metadata-driven tasks, such as asynchronous indexing on hot columns and compaction, which keep pipelines unblocked while maintaining query performance as tables scale. In practice, this shines for mixed workloads like high-volume appends with sporadic deletes for event tables, skewed updates in facts, and uniform refreshes in dimensions.
These innovations make Quanton not just faster, but fundamentally smarter for real-world lakehouse demands.
Putting Performance to the Test
If you are impatient to get to the numbers. Let's ground these claims in rigorous benchmarks. As data engineers, it is imperative that we rely on data-driven decisions. Thorough benchmarks aren't just academic, they’re essential for validating choices in production environments. We urge you to test your own workloads and if you are unsure where to start, you should read our benchmark deep dive blog which dissects the benefits and limitations for many benchmarks.
Show me the numbers…
If you are like most and you don’t have time to run all the benchmarks yourself, below you will find our results from running TPC-DS, TPCx-BB, TPC-DI, and LakeLoader. Each of the benchmarks use open source Spark as the baseline since this serves as a simple starting point with no other vendor costs. The setup, configurations and results of each benchmark are documented below.

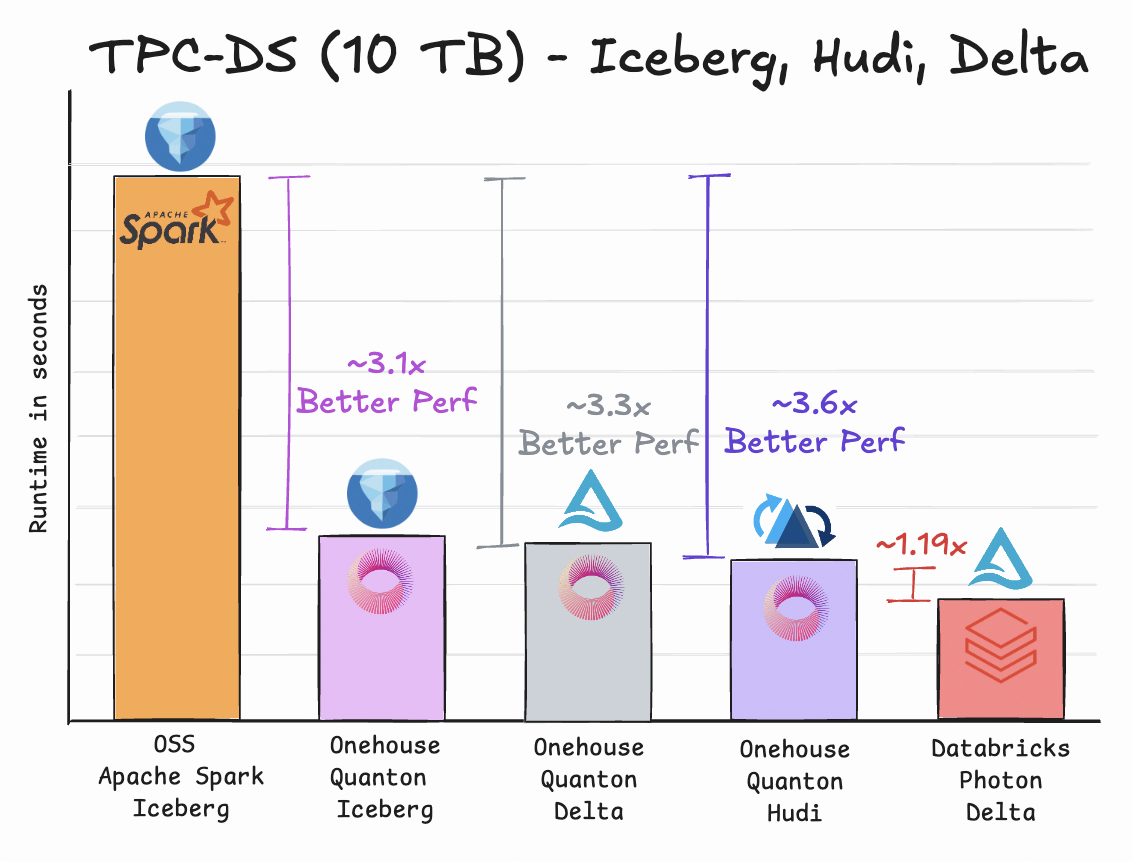
TPC-DS is the primary benchmark in the industry used to measure compute efficiency of warehouses and lake engines. TPC-DS is significantly more complex than its predecessors like TPC-H. TPC-DS has 99 queries that all effectively test how well the engine under test can scan, join and filter large amounts of data. Quanton was able to deliver up to ~3.1x better performance over Spark OSS, with native Iceberg reads on the Spark Datasource V2 interface. With TPC-DS, we also decided to do an extra run with open source Gluten and Spark. While Gluten adds valuable accelerations, this benchmark shows you a clear comparison of how Quanton is differentiated.
But, Spark workloads are not entirely SQL based. They contain python dataframe operations and also some java code in the mix. To expand our testing, we also included TPCx-BB, which has 30 queries spread across SQL, python and Java code. Even with such a mixed workload, Quanton together with our runtime, was able to deliver a solid 2x better performance than OSS Spark.

When it comes to ETL workloads, it’s very important to pay attention to the ‘L’, i.e, the write performance. TPC-DI is one of the only benchmarks in the industry to test write performance by issuing a series of MERGE INTO (mutations) and INSERT statements (append-only writes). We benchmarked Quanton on Iceberg at 1TB scale to discover how it delivered 2x better performance. TPC-DI includes several ET steps as well, including joins. So, when we compare write performance head-to-head using just the MERGE INTO queries, Quanton delivers 3-4x speedups in terms of pure merge/update performance.

We’ve shared our fair criticism of the TPC-DI benchmark before on how it hinges the merge performance on a 5-column table with no control for real-world write patterns. Earlier this year, we open-sourced Lake Loader, a tool that fills these gaps and tests purely L performance, such that using LakeLoader and an established compute benchmark like TPC-DS, users can derive very meaningful and actionable benchmark results.
We tested Quanton using LakeLoader, at 1TB scale on a similar random update workload. Quanton delivered 4.1x better write performance versus OSS Spark.

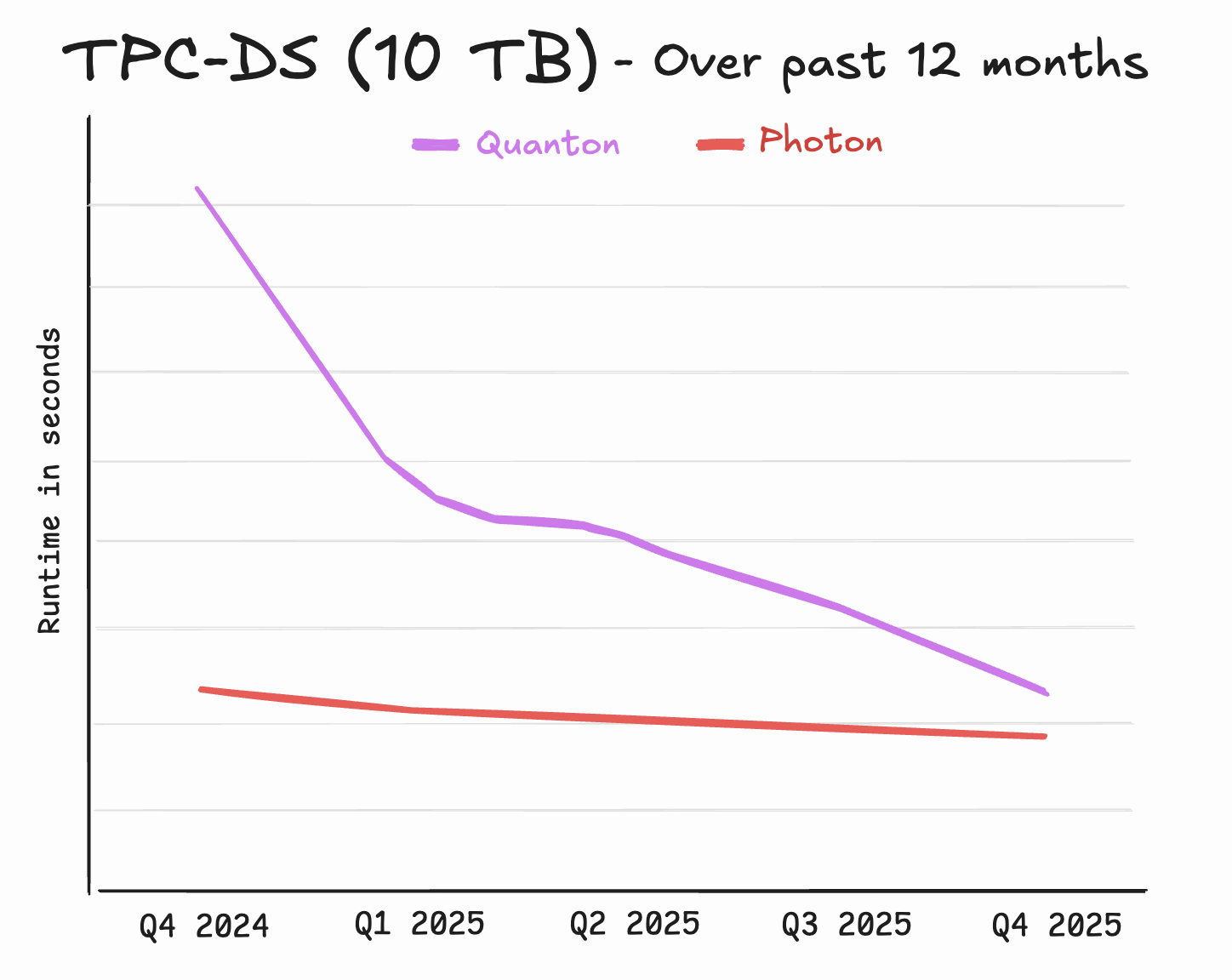
In summary, we expect Quanton to deliver a solid 3-4x gain over OSS Spark for read queries and writes. Is this the fastest we can do? It is, for now. But the answer could be very different in another 3-6 months, as we are innovating at a breakneck pace. Similar to how Databricks had achieved 5x better performance in just three years, we are excited to report that Quanton is currently within 15% performance difference against what’s considered the industry premium Spark engine Photon – just 12 months since we began development!
We have already unlocked higher levels of performance on Apache Hudi/Delta Lake/Apache Parquet, which are making their way to Iceberg as well on top of a Quanton-enabled Spark/SQL cluster near you. Given Photon costs several times more per cluster and Quanton has no additional charges per cluster, Quanton is now hands-down the engine with the best price-performance for Spark workloads. While the numbers presented so far are pure performance comparisons, scroll to the end of the blog to see even more impact in price/performance comparisons.
Beyond Performance: DevX matters
Sure, speed is crucial, but what about the day-to-day experience and the hours of engineering time that are used in configuring, deploying, patching, monitoring, and tuning Spark clusters? Most Spark platforms today are starting to show their age. AWS EMR launched in 2009, and Databricks in 2014, both well before the age of the Lakehouse. As such, most Spark platforms offer Spark as a generic compute platform and they treat lakehouse tables simply as external libraries that know how to read some extra metadata.
To get specific, let’s break it down in this comparison matrix:
Elastic Cluster Scaling
Open-source Apache Spark uses dynamic allocation as its primary autoscaling mechanism. This adjusts the number of executors based on the number of pending tasks in the scheduler queue. However, its effectiveness is limited in lakehouse ETL scenarios, often resulting in overprovisioning or delayed scaling for spiky loads, leading to higher costs and unpredictable performance.
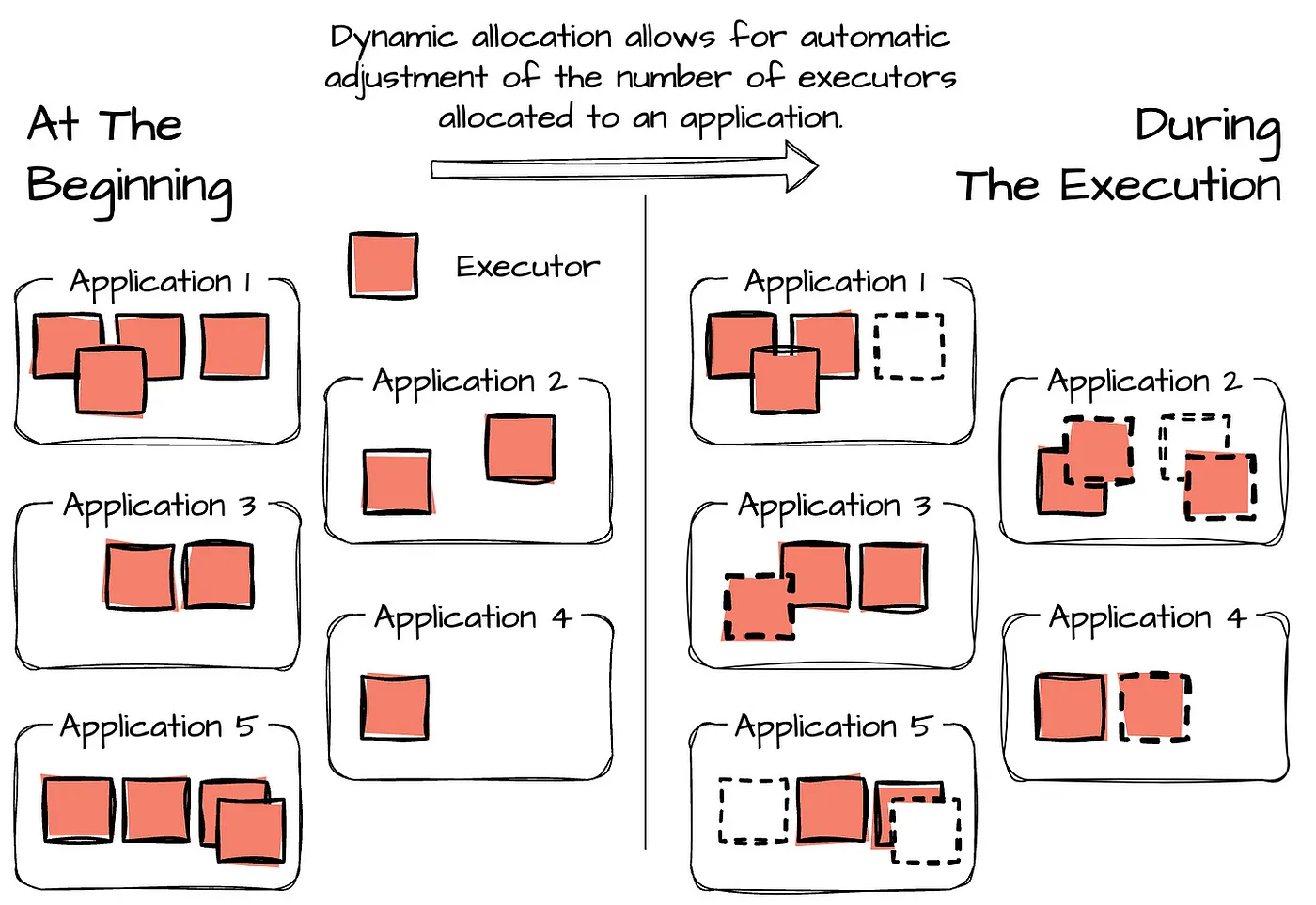
Amazon EMR Spark enhances this with managed scaling policies that resize cluster instances based on additional metrics like memory and vCPU utilization. EMR however still suffers from conservative scaling decisions, overprovisioning during bursts, and manual tuning requirements for optimal thresholds. It can’t adapt well to shuffle pressure, job queue depth, or executor bottlenecks.
Onehouse Quanton, built as a lakehouse-optimized Spark runtime, introduces a more advanced, workload-aware autoscaling approach that leverages the above techniques, but also deeply integrates with table formats and ETL patterns. If you analyze the charts below you can compare the Quanton autoscaler versus OSS Spark. The first graph shows OSS executor count in green and Quanton executor count in yellow. OSS dynamic allocation is slow to respond and even non-responsive at scaling down across the job lifetime. The cost differences between OSS autoscaler and Quanton is significant.
The second graph is the avg % CPU utilization across executors, and the final graph shows the count of tasks per executor.

Even though Spark vendors like Databricks provide enhanced dynamic allocation, their autoscalers still lack full awareness of workload characteristics. For example, an incremental ETL job with strict latency SLAs has very different scale-up and scale-down requirements than a batch ETL job optimized for cost efficiency. Similarly, an autoscaler that bases decisions solely on task backlog for an ETL job streaming data from Kafka into the lake risks unbounded lag as Kafka messages accumulate. In addition, ETL jobs often repeat similar tasks across runs, leveraging this historical information can significantly improve autoscaler performance.
Iceberg Table Management
OSS Spark and legacy platforms like AWS EMR have no Iceberg table support beyond letting you install and use the libraries. Want compaction, delete file handling, or clustering? Get ready to write your own Spark jobs and hope they don’t break.
With Onehouse we automate efficient background table services. When you compact small files or sort data within files, a merge-style operation occurs. To more efficiently handle these operations, we developed a highly optimized partial columnar merge algorithm that can accelerate these Iceberg operations by up to 4x.
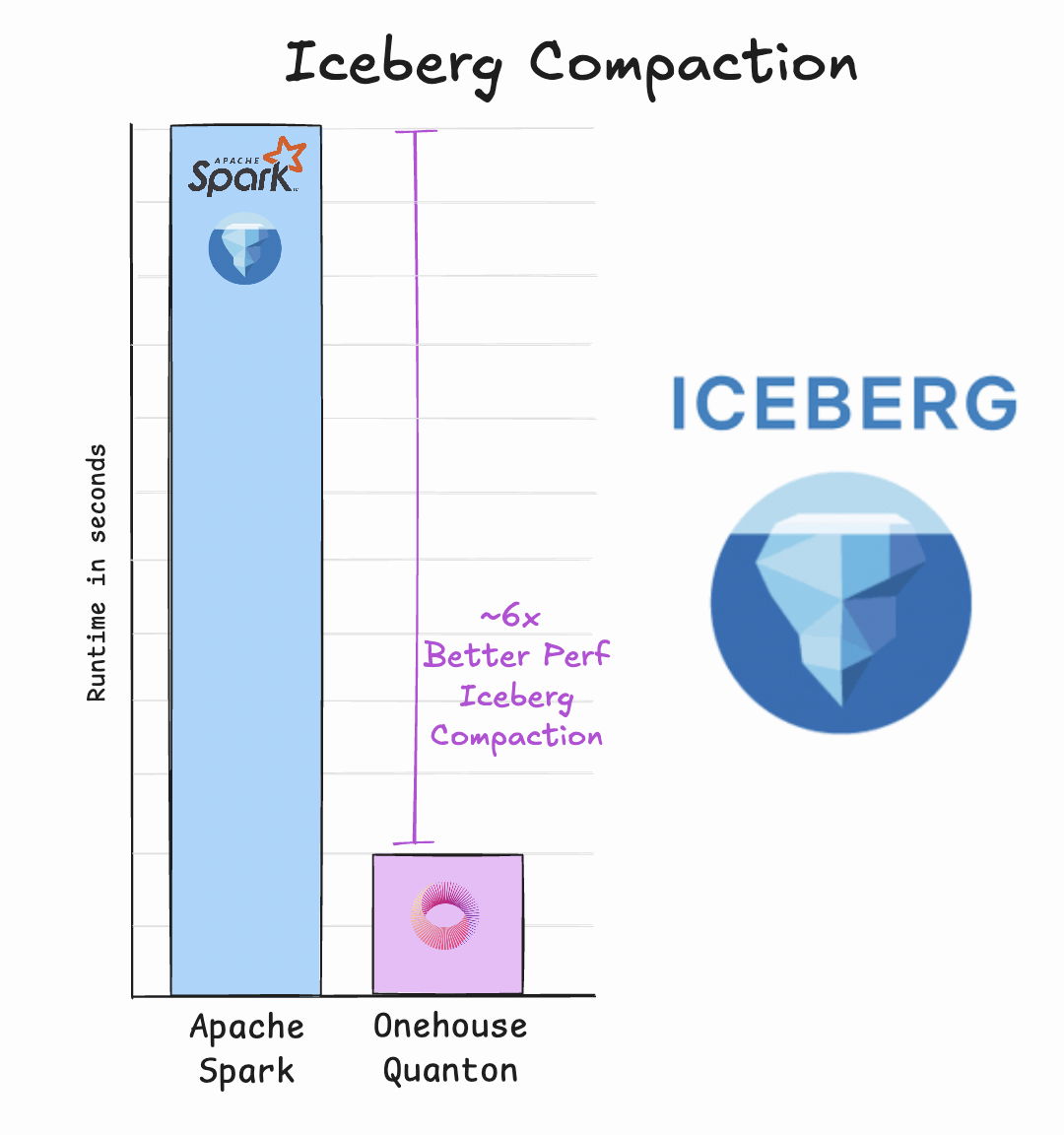
Onehouse handles all of the basic table maintenance like cleaning, clustering, compaction, etc, and we also give you the ability to customize the settings to deepen your performance optimizations.

Monitoring and Debugging
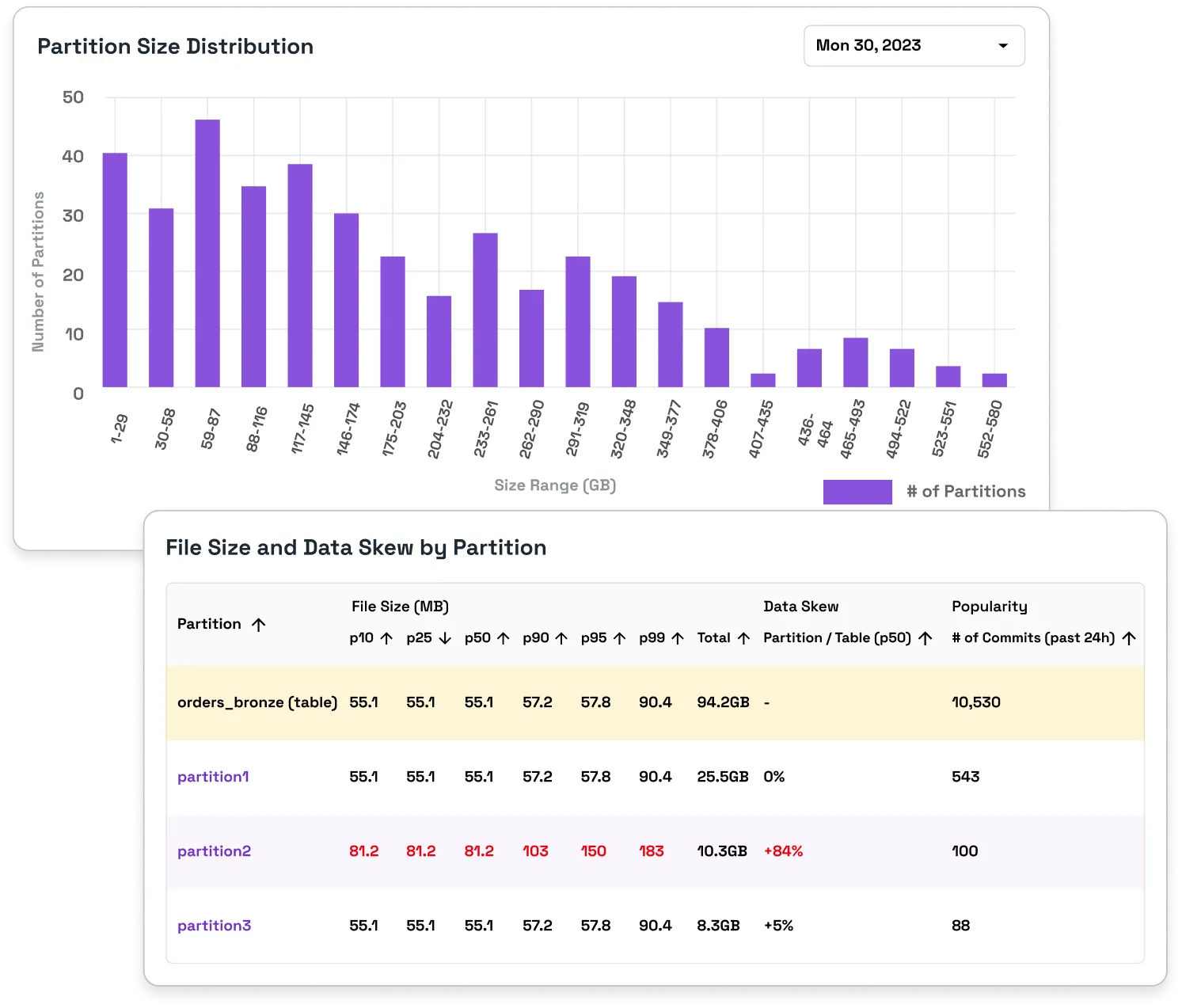
Want to debug a job? I hope you like CloudWatch. Want to see Iceberg compaction stats? Sorry, they don’t exist. OSS Spark and legacy platforms like EMR give you the bare bones basics for generic Spark jobs. Onehouse comes out of the box with rich monitoring and alerting, detailed cost attributions, and lakehouse specific metrics and insights to keep you aware of your table performance and history.
Interoperability
With open source spark at least you can DIY control your own destiny. You can install, configure, or integrate any additional technology you want if you have the time, talent, and determination. Using legacy Spark platforms leaves you beholden to the vendor’s choice of what is supported. That usually means 1 catalog choice and 1 table format choice.
Onehouse supports all table formats, even allowing you to mix and match them with Apache XTable. Onehouse also offers OneSync™ which can take a single copy of data and synchronize the metadata to multiple catalogs simultaneously. This means as soon as your table is created, it can immediately be available for analytics across Snowflake, Databricks, BigQuery, Athena, and any other query engine on the market that supports at least one of the open table formats.
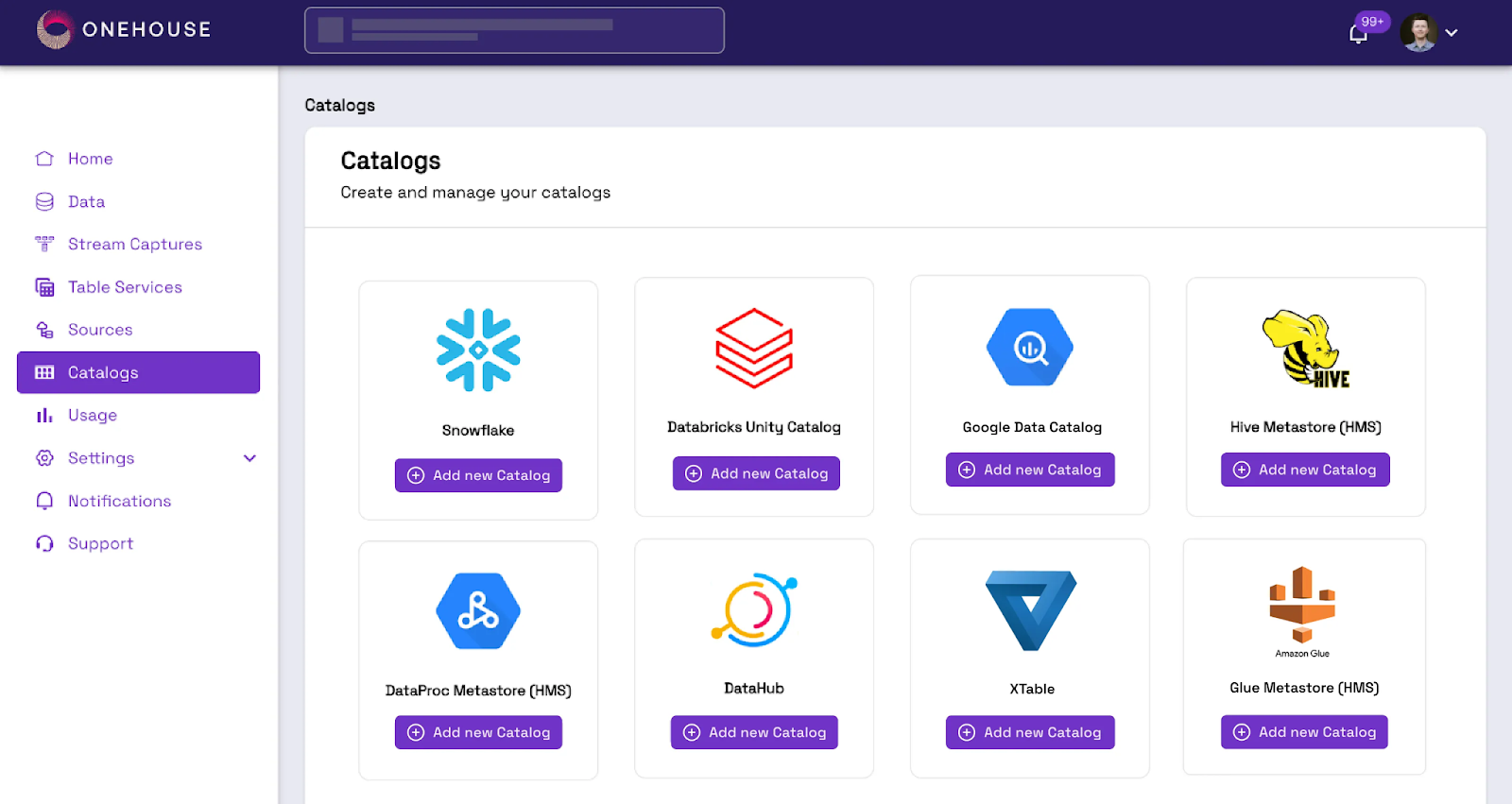
Built-In Iceberg Rest Catalog Integration
In particular, Onehouse makes leveraging an Iceberg REST catalog (IRC) a seamless integration. Spark environments are notoriously difficult with users frequently encountering errors such as:
- "Catalog not found" due to mismatched configurations
- Schema evolution with caching causing write failures after external metadata updates
- Dependency conflicts, like missing HiveCatalog JARs
- In managed environments like AWS EMR, creating Iceberg tables via Spark SQL might register only the table name in Glue without the schema, rendering them unusable in tools like Athena
Iterative troubleshooting of the catalog setup is usually required to avoid production pitfalls.Onehouse streamlines the process, presenting a list of pre-defined catalogs to the user during cluster creation. Catalogs can be switched on demand via simple API calls or UI toggles, allowing teams to adapt to different workloads. By automating catalog discovery, validation, and synchronization, Onehouse delivers a more reliable and efficient lakehouse experience.
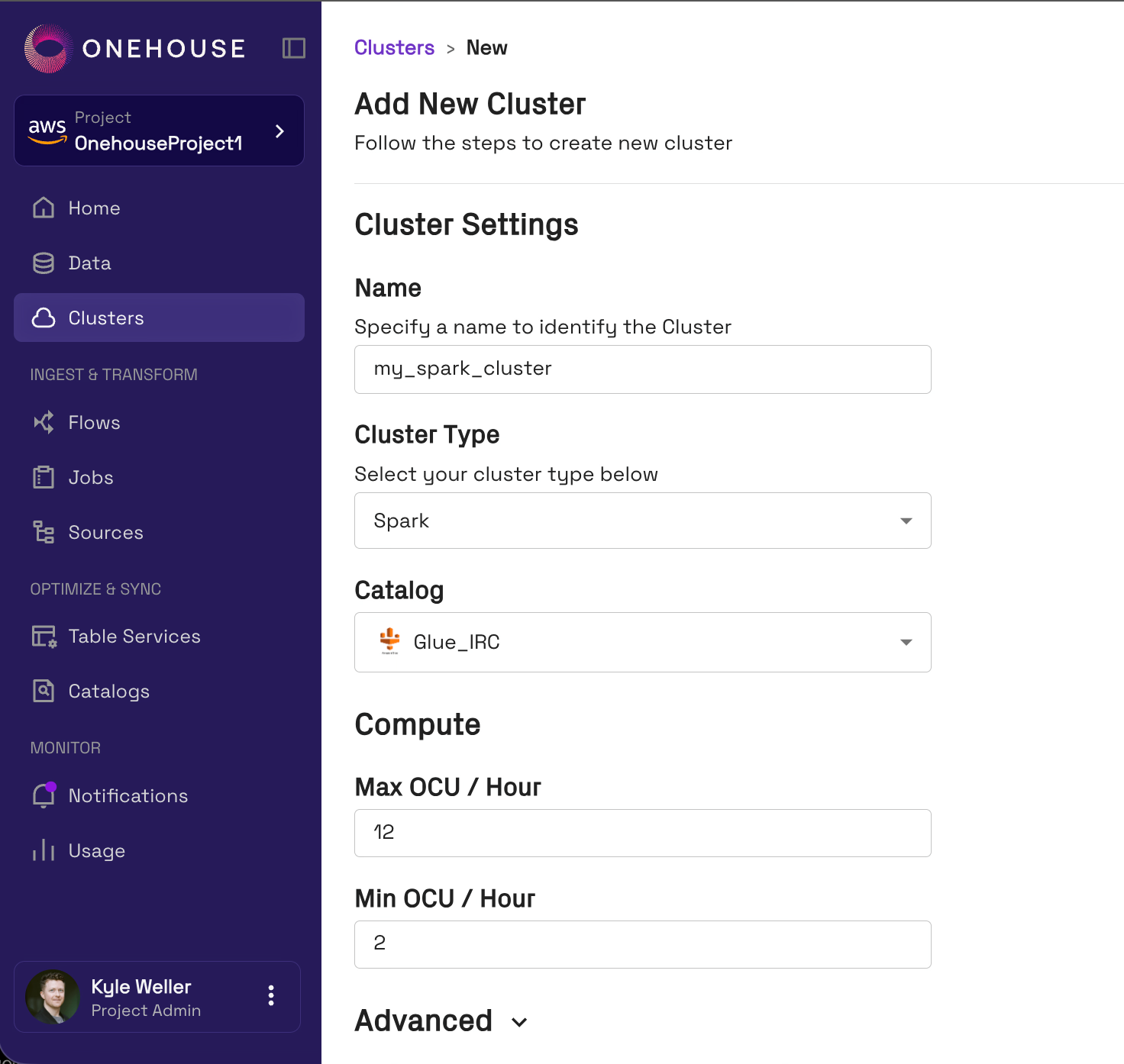
Expert Support For Spark and OTFs
Support for healthy open source projects is available as best effort from fellow peer community members. Specifically, around Spark, you can typically seek out help via GitHub, or community mailing lists. Unlike the open table format projects, Spark does not have a community slack, free of vendor control. The OSS support options work great for non-urgent issues, but when a production impacting pipeline is on the line, you may need better than best-effort, instead of hoping the documentation is up to date while you are on your own. With legacy Spark platforms, at least you have someone you can call. 24x7 support is typical for paid engagements, but the depth of support is usually limited to generic Spark knowledge leaving the lakehouse specific cases to a few community experts only.
Onehouse has assembled a team of top Lakehouse talent from across the industry. Onehouse engineers have built and operated some of the largest data lakes on this planet. Being pioneers in the lakehouse industry, Onehouse also has a deep breadth of experience from community engagements. Because Quanton clusters are deployed BYOC style inside of your VPC our experts will now feel like an extension of your own data team.

How easy is it to make the switch?
If you are sold on the performance and devex described above, you now may be wondering how you can get started? One of the first hurdles you likely will face is in gathering evidence or research to propose a change and justify the effort to your team. If blogs, content, or benchmarks are not sufficient, Onehouse also developed a simple python tool, Cost Analyzer for Apache Spark™, which can analyze your unique spark logs and identify bottlenecks or resource wastage in your jobs. Cost Analyzer works across all major Spark platforms, AWS EMR, GCP Dataproc, Microsoft Fabric, Databricks and more. It runs locally on your computer and even gives you tips on how to accelerate your jobs. In ~15minutes you can have a private and detailed report of how much money Quanton can save you. Available on pyPI, you can simply run `pip install spark-analyzer` in your terminal:
After you successfully make your case internally, trying out or onboarding to use Quanton is simple. Quanton is 100% Spark compatible. If you have any scala, pyspark, sparkSQL jobs that you already run on your own OSS clusters or with another vendor, these same jobs can run on the Onehouse platform with no code changes. If you are using an orchestration tool like Airflow, all you need to do is change the endpoint that you were previously pointing to. While this means it is easy to get started with Onehouse, it also means that you are not locked in. If you are not satisfied with Onehouse, you can take all those Spark jobs and point them back to whatever infrastructure you had them running on previously.
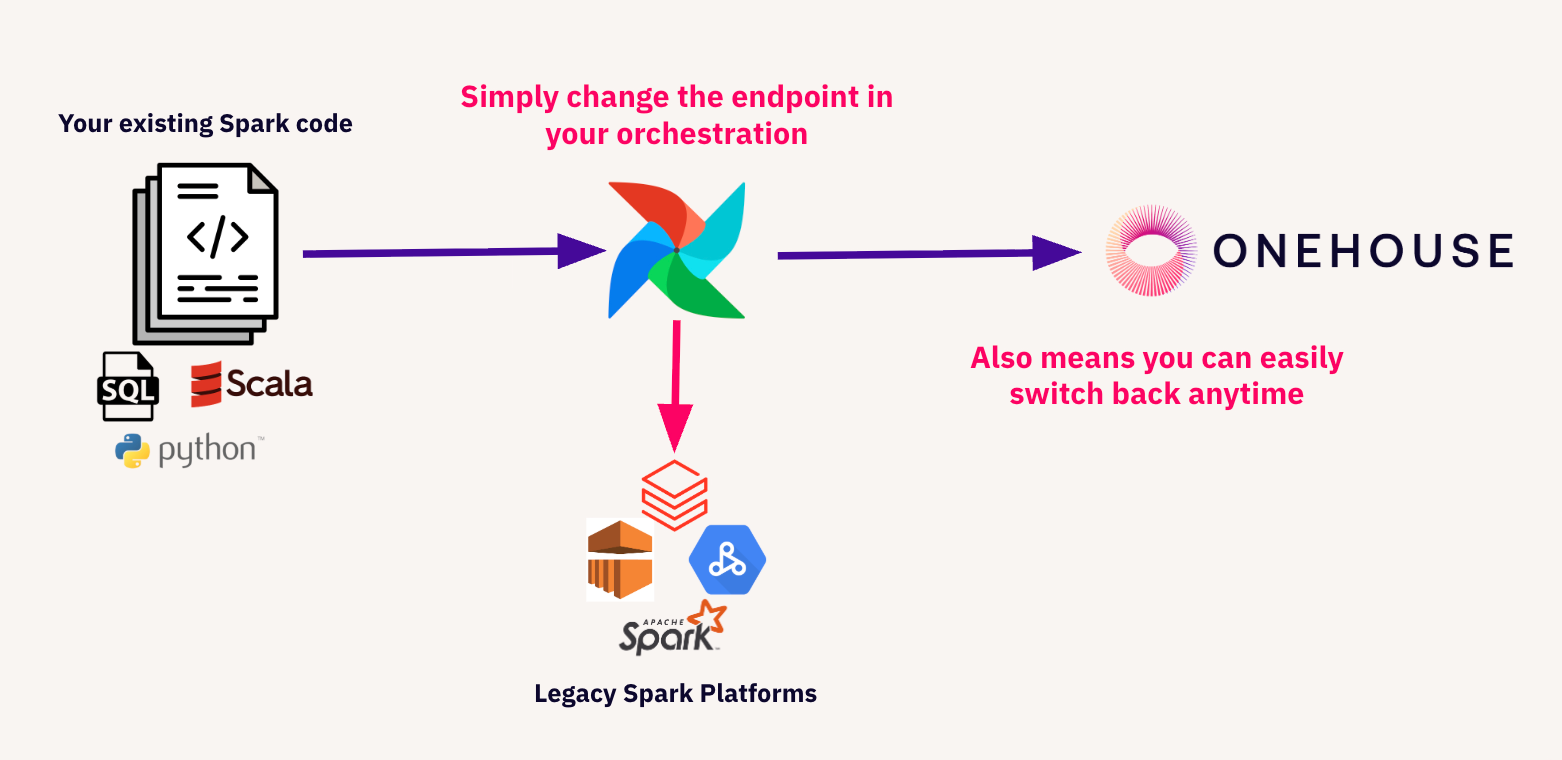
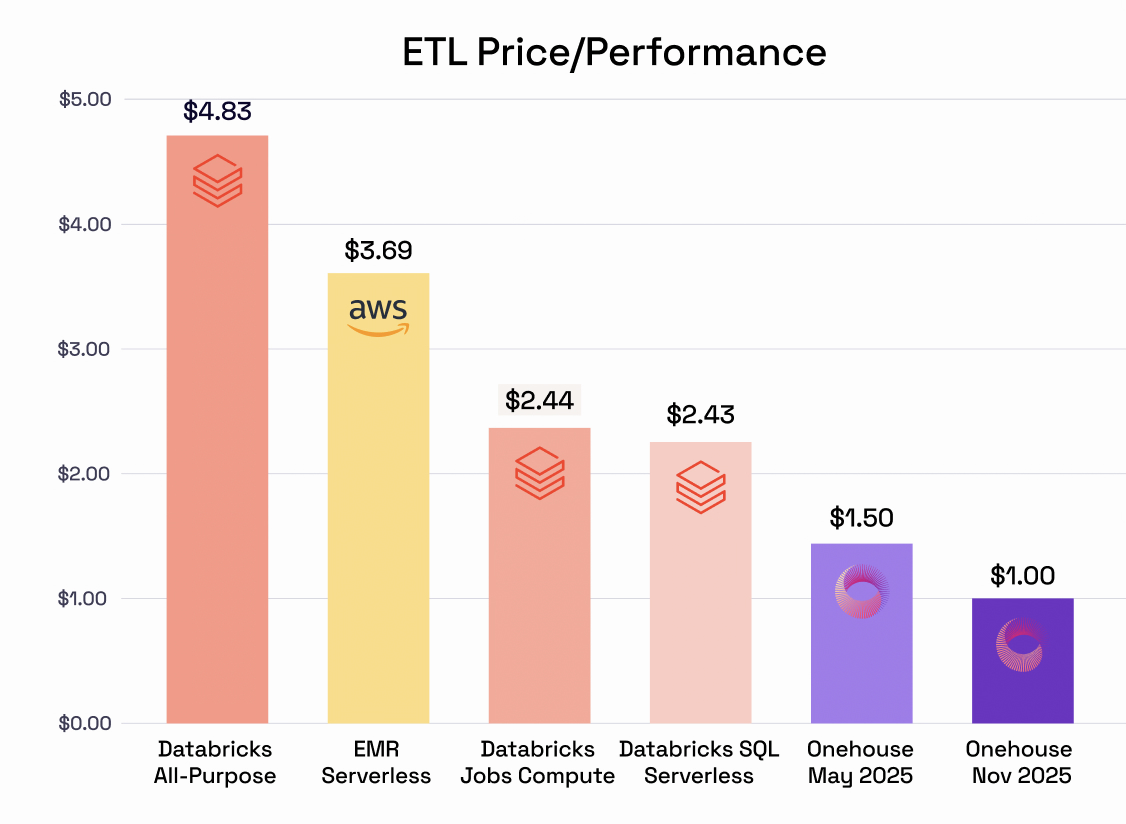
Over the past 6 months, we have been busy helping organizations evaluate EMR and Databricks migrations. Across different use cases, we have observed 40-60% cost savings for large-scale workloads:
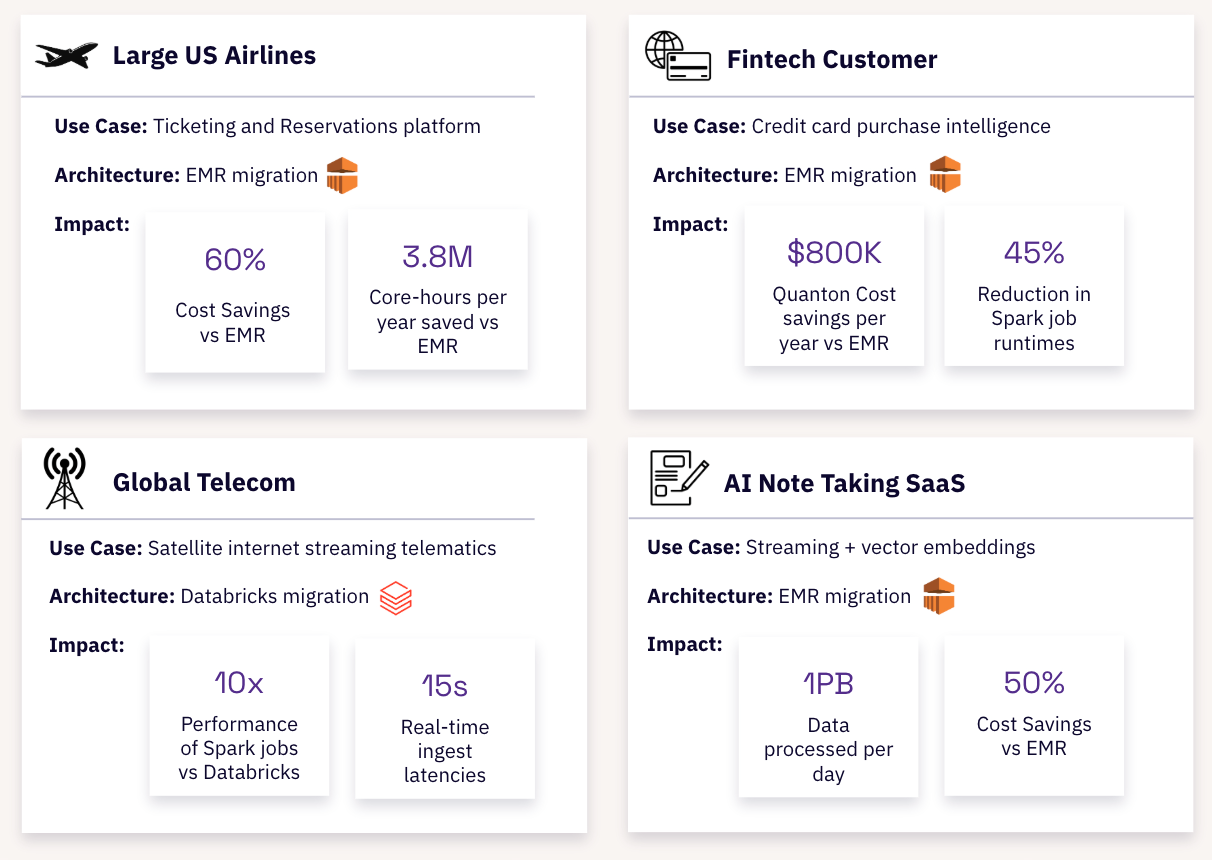
Accelerate Your Iceberg Lakehouse with Quanton
When Iceberg users share their goals with us, right after the performance, the next we hear most often is cost savings. Unlike other premium Spark vendors, Onehouse does not charge a separate premium fee to use Quanton accelerated clusters, all your jobs are accelerated by default.
After launching Quanton 6 months ago we are also constantly improving the performance. Here are how things stack up as of today when you measure price/performance, against other popular Spark platforms on the market. Onehouse delivers 2-4x leading price-performance for Iceberg ETL workloads. We plan to publish a separate blog comparing the same against SQL Cloud warehouses.
If you want to try Quanton accelerated Iceberg pipelines for yourself, You can start with our free Cost Analyzer for Spark or contact us for a free trial cluster today. Together, let's forge a faster future for Iceberg. Visit https://www.onehouse.ai/product/quanton to get started.
If reading this made you lean forward — we’re hiring. At Onehouse, we’re tackling the hardest data infrastructure challenges: accelerating open table formats, reinventing the Spark runtime, and rethinking the data lakehouse around AI.
We’re looking for world-class engineers who live and breathe distributed systems, query engines, and cloud-scale storage to help us push the limits of what’s possible. If building the future of data infrastructure excites you, come join us.


Read More:





Subscribe to the Blog
Be the first to read new posts