Apache Iceberg™ vs Delta Lake vs Apache Hudi™ - Feature Comparison Deep Dive

Introduction
With the growing popularity of the data lakehouse there has been a rising interest in the analysis and comparison of the three open source projects which are at the core of this data architecture: Apache Hudi™, Delta Lake, and Apache Iceberg™. As all projects continue growing, we updated this comparison article in October 2025 to include consideration of new features across the latest releases.
Most comparison articles currently published seem to evaluate these projects merely as table/file formats for traditional append-only workloads, overlooking some qualities and features that are critical for modern data lake platforms that need to support update-heavy workloads with continuous table management. (For more on the difference between a file/table format and a full data lakehouse implementation, please see our related blog post, Open Table Formats and the Open Data Lakehouse, In Perspective.) This article will dive into greater depth as to the feature comparisons and also comprehensively cover benchmarks and community statistics.
If, when analyzing the comparisons, you find it hard to choose which format you want to use, take a look at our new project: Apache XTable™ (Incubating). XTable offers seamless interoperability between Hudi, Delta, and Iceberg. You no longer have to choose between formats or be locked into just one format. XTable (initially called Onetable) was co-launched into open source by Microsoft, Google, and Onehouse, with VentureBeat covering the story. XTable has been donated to the Apache Software Foundation.
Feature Comparisons
First let's look at an overall feature comparison. As you read, notice how the Hudi community has invested heavily into comprehensive platform services on top of the lake storage format. While formats are critical for standardization and interoperability, table/platform services give you a powerful toolkit to easily develop and manage your data lake deployments.
 As of v1.0.2
|
 As of v4.0.0
|
 As of v1.10.0
|
|
|
Write features |
|||
|
ACID transactions
(Can I version and rewrite columnar files?) |

|
|
|
|
Copy-On-Write
(Can I version and rewrite columnar files?) |
Writes
|
Writes
|
Writes
|
|
Merge-On-Read
(Can I efficiently amortize updates without rewriting the whole file?) |
Full fledged Merge-On-Read
|
 Deletion Vectors experimental with limited MOR functionality Cannot balance merge perf for queries.
Requires 2 step maintenance of Reorg and Vacuum
Deletion Vectors experimental with limited MOR functionality Cannot balance merge perf for queries.
Requires 2 step maintenance of Reorg and Vacuum
|
Deletion Vectors
with limited MOR functionality.
Cannot balance merge perf for queries. Requires manual compaction maintenance. Only one DV allowed per file
|
|
Efficient bulk load
(Can I efficiently layout the initial load into the table? ) |
Bulk_Insert
|
|
|
|
Efficient merge with indices
(Can I avoid merging all base files against all incoming update/delete records?) |
More than 8 types of
indexing
|
|
|
|
Partial updates
(Can I rewrite only updated columns instead of full change records?) |
Partial Updates
|
|
|
|
Bootstrap
(Can I upgrade data in-place into the system without rewriting the data?) |
Bootstrap
|
Convert to Delta
|
Table migration
|
|
Managed ingestion
(can I ingest data streams from popular sources, with no/low code?) |
Hudi DeltaStreamer
|
|
|
|
Concurrency Control
(if I run different writers and table services against the table at the same time how are competing commits handled?) |
OCC,
MVCC,
NBCC
and
Early Conflict Detection
|
OCC only
|
OCC only
|
|
Non-Blocking Concurrency
( Can I run different writers against the same table and not have them fail on each other?) |
NBCC
Non-blocking concurrency control where competing commits don’t fail or retry
|
|
|
|
Lock managers for multi-writers
(How can I configure multiple writers to write to the same table simultaneously?) |
Non-blocking concurrency control for multi-writers
Or can still use
external file system, DynamoDB, Hive, or Zookeeper lock provider
|
Requires external DynamoDB lock provider.
Locks managed at Spark JVM for single-writer and table level with external Dynamo
|
Catalog used as locking mechanism with CAS operation
. Or can use
external lock providers like DynamoDB
|
|
Data deduplication
(Can I insert data without introducing duplicates?) |
Merge,
Unique record keys,
Precombine utility,
Drop dupes from inserts
|
No primary keys,
Merge Into, Insert Overwrite, Update cmds
|
No primary keys,
Merge Into, Insert Overwrite, Update cmds
|
| Catalog dependency |
Catalog not required
|
Catalog not required
|
|
|
As of v1.0.2
|
As of v4.0.0
|
As of v1.10.0
|
|
|
Table metadata |
|||
|
Scalable metadata
management
(Can the table metadata scale with my data sizes) |
LSM tree timeline with Hudi
MoR based metadata table w/
HFile formats for 100x faster lookups, self managed like any Hudi Table
|
Parquet txn log checkpoints
significantly slower lookups
|
Avro manifest files significantly slower and
need maintenance as you scale
|
|
Index management
(Can I build new indices on the table?) |
Async multi-modal indexing subsystem
Simple, Bloom, Global, HBase, In-Memory, Bucket, Hash, and Record Level Indexes Expression Index Secondary Index and BYO pluggable index for custom indexes useful for AI vector embeddings |
|
|
|
Schema evolution
(Can I adjust the schema of my table) |
Schema evolution for add, reorder, drop, rename, update
|
Schema evolution
for add, reorder, drop, rename, update
|
Schema evolution
for add, reorder, drop, rename, update
|
|
Partition evolution
(Can I keep changing the partition structure of the table as we go?) |
Hudi encourages coarse grained partitions and fine-grained
clustering and also offers expression indexes which achieves the same goal.
|
|
Partition evolution
lets you change partitions as your data evolves. Old data stays in old partitions, new data gets new partitions, with uneven performance across them.
|
|
Primary keys
(Can I define primary keys like regular database tables?) |
Primary keys
|
|
|
|
Column statistics and data skipping
(Can queries benefit from file pruning based on predicates from any column, without reading data file footers?) |
Col Stats in metadata
Hfile Column Stats Index adds up to 50x perf |
Column Stats in Parquet checkpoint
|
Column Stats in Avro manifest
|
|
As of v1.0.2
|
As of v4.0.0
|
As of v1.10.0
|
|
|
Read features |
|||
|
Time travel
(Can I query the table as of a point-in-time?) |
Time travel
|
Time travel
|
Time travel
|
|
Merge-On-Read query
(Can my query read both the parquet files and merge the change files at query time?) |
Snapshot Query
|
Complex relationship of reader/writer support
between OSS and proprietary Delta Lake
|
All queries will merge deletion vectors
|
|
Incremental query
(Can I obtain the latest values for all records that have changed after a given commit timechange stream for a given time window on the table?) |
Incremental query and CDC query
|
CDF experimental mode
|
|
|
CDC query
( Can I obtain all changes to a table within a given time window?) |
CDC query
Also provides before/after images and change operations of the changed records |
|
|
|
Secondary index
(Can indexes be used to speed up queries with predicate on columns other than record key columns?) |
Secondary index query
(blog)
Efficient point lookup queries |
|
|
|
Data skipping based on built-in functions
(Can queries perform data skipping based on functions defined on column values, in addition to literal column values?) |
Expression indexes
- If a query has a predicate on a function of a column, the expression index speeds up the query
|
Logical predicates on a source or a generated column will prune files during query execution
|
Iceberg can transform table data to partition values and maintain relationships, while also collecting stats on columns
|
|
As of v1.0.2
|
As of v4.0.0
|
As of v1.10.0
|
|
|
Table Services |
|||
|
File sizing
(Can I configure a single standard file size to be enforced across any writes to the table automatically?) |
Automated file size tuning
|
Auto file sizing
|
Manual maintenance
|
|
Compaction
(Merge changelogs with updates/deletes from MoR writes) |
Managed compaction
|
Merging deletion vectors requires 2 step maintenance of Reorg and Vacuum
|
Compaction requires
manual maintenance
|
|
Cleaning
(Do older versions of files get automatically removed from storage?) |
Managed cleaning service
|
VACUUM
is manual operation
|
Expiring snapshots
is manual operation
|
|
Linear clustering
(Can I linearly co-locate certain data close together for performance?) |
Automated clustering that can be evolved for perf tuning,
user defined partitions
|
|
You can force writers to
sort as they write which hinders performance.
|
|
Multidimensional Z-order/Space curve clustering
(Can I sort high cardinality data with space curves for performance?) |
Z-order + Hilbert Curves
with auto async clustering
|
Z-order in OSS, but
auto-optimize still proprietary
|
Z-order
through manual maintenance
|
|
As of v1.0.2
|
As of v4.0.0
|
As of v1.10.0
|
|
|
Platform Support |
|||
|
CLI
(Can I manage my tables with a CLI) |
CLI
|
|
|
|
Data quality validation
(Can I define quality conditions to be checked and enforced?) |
Pre-commit validators
|
Constraints for not null and value check only
|
|
|
Pre-commit transformers
(Can I transform data before commit while I write?) |
Transformers
|
|
|
|
Commit notifications
(Can I get a callback notification on successful commit?) |
Commit notifications
|
|
|
|
Failed commit safeguards
(How am I protected from partial and failed write operations?) |
Automated marker mechanism
|
Manual
configs
|
|
|
Monitoring
(Can I get metrics and monitoring out of the box?) |
MetricsReporter
for automated monitoring
|
|
|
|
Savepoint and restore
(Can I save a snapshot of the data and then restore the table back to this form?) |
Savepoint command to save specific versions.
Restore command with time travel versions or savepoints |
Restore command with time travel versions
Have to preserve all versions in vacuum retention (eg. If you want to restore to 6mon ago, you have to retain 6mon of versions or DIY) |
|
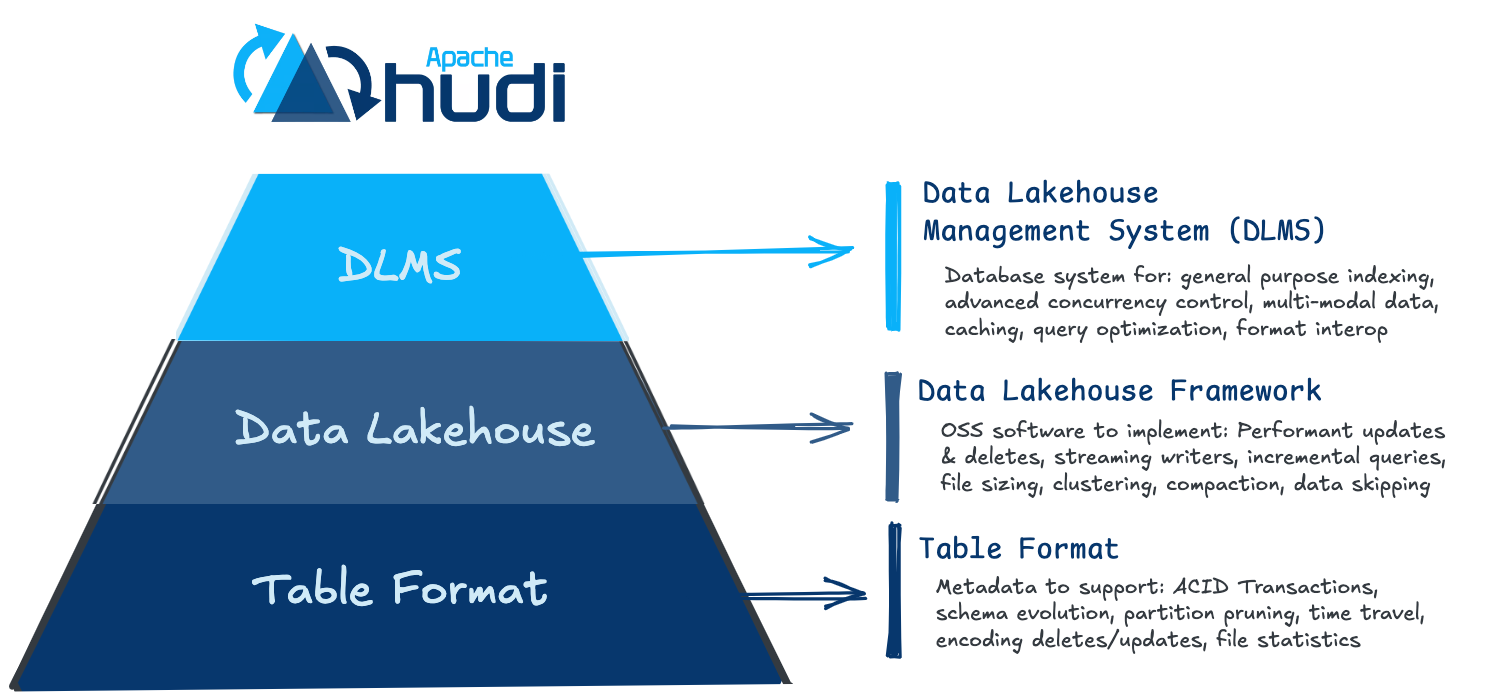
From the comparisons above you may notice a pattern that the inspection of these three projects can be split into multiple layers beyond simply an “Open Table Format”:

While historically each are considered “Table Formats,” Hudi is slightly different in that it also offers “Storage Engine” functionality for a full fledged lakehouse platform or what some might call a DLMS: Data Lakehouse Management System:
Community Momentum
An important aspect of an open source project is the community. The community is essential for the development momentum, ecosystem adoption, or the objectiveness of the platform. Below is a comparison over the last 12 months of Hudi, Delta, Iceberg when it comes to their communities:
|
|
|
|
|
|
Community Momentum |
|||
|
Github Stars
All Time (a vanity metric that represents popularity more than contribution) |
5,893 | 8,179 | 7,435 |
|
Github Watchers
All Time (People interested to track a project) |
1,153 | 216 | 178 |
|
Github Forks
All Time (A closer indication of engagement/usage of the project) |
2,430 | 1,892 | 2,720 |
|
Github Contributors
Last 12 months (Number of people who contributed to the repo in any form) |
1,030 | 1,332 | 2,924 |
|
Github PRs
Last 12 months (Number of PR events on the repo) |
2,893 | 1,978 | 4,180 |
TPC-DS Performance Benchmarks
Performance benchmarks rarely are representative of real life workloads, and we strongly encourage the community to run their own analysis against their own data. Nonetheless these benchmarks can serve as an interesting data point while you start your research into choosing a data lakehouse platform. Below are references to relevant benchmarks:
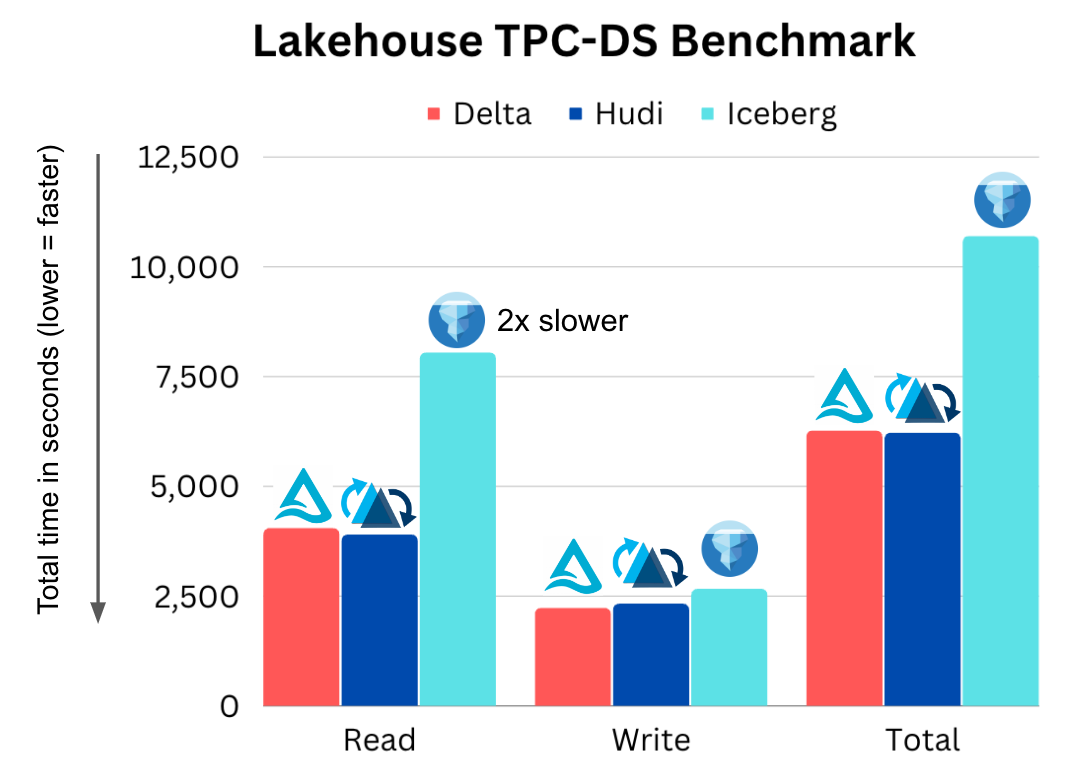
Databeans and Onehouse
Databeans worked with Databricks to publish a benchmark used in their Data+AI Summit Keynote, but they misconfigured an obvious out-of-box setting. Onehouse corrected the benchmark here:
Brooklyn Data and Onehouse
Databricks asked Brooklyn Data to publish a benchmark of Delta vs Iceberg:
https://brooklyndata.co/blog/benchmarking-open-table-formats
Onehouse added Apache Hudi and published the code in the Brooklyn Github repo:
https://github.com/brooklyn-data/delta/pull/2
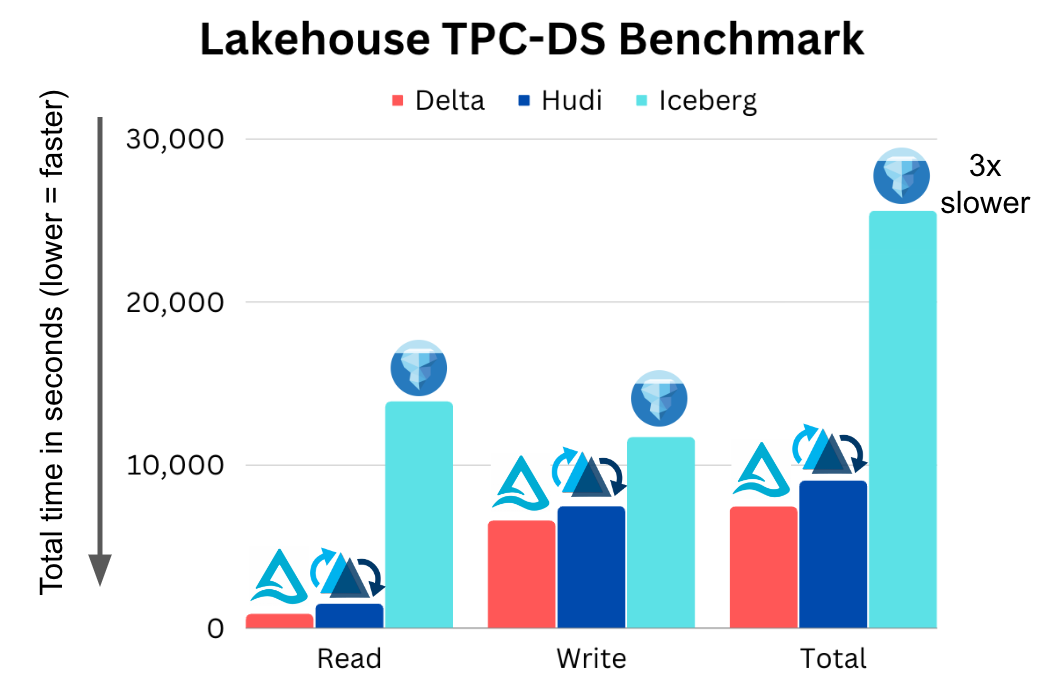
A clear pattern emerges from these benchmarks: Delta and Hudi are comparable, while Apache Iceberg consistently trails behind as the slowest of the projects. Performance isn’t the only factor you should consider, but performance does translate into cost savings that add up throughout your pipelines.
A note on running TPC-DS benchmarks:
One key thing to remember when running TPC-DS benchmarks comparing Hudi, Delta, and Iceberg is that, by default, Delta and Iceberg are optimized for append-only workloads. Hudi default settings, by contrast, are optimized for mutable workloads. By default, Hudi uses an `upsert` write mode which naturally has a write overhead compared to inserts. Without this knowledge you may be comparing apples to oranges. Change this one out-of-the-box configuration to `bulk-insert` for a fair assessment: https://hudi.apache.org/docs/write_operations/
For more details about benchmarks, see our in depth TPC benchmark review research here:
https://www.onehouse.ai/blog/measuring-etl-price-performance-on-cloud-data-platforms
Feature Highlights
Building a data lakehouse platform takes more than just reviewing checkboxes listing feature availability. Let’s pick a few of the differentiating features above and dive into the use cases and real benefits in plain English.
Incremental Pipelines
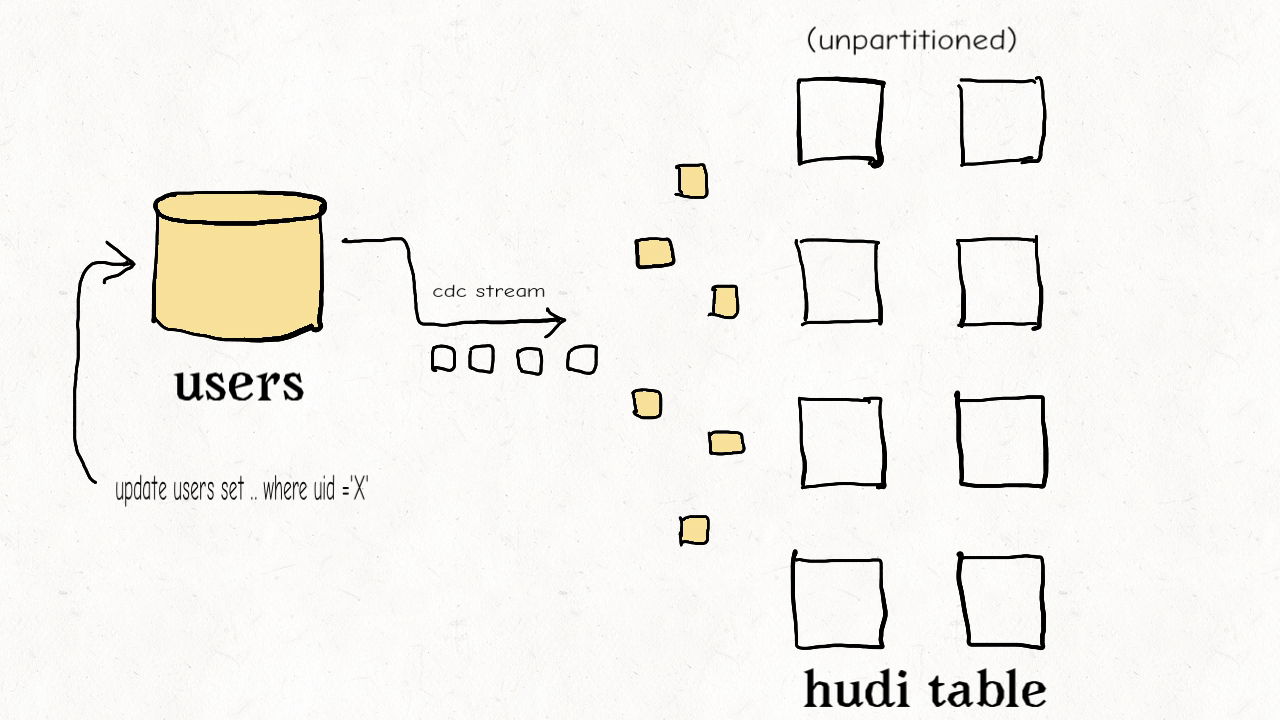
The majority of data engineers today feel like they have to choose between streaming data and old-school batch ETL pipelines. Apache Hudi has pioneered a new paradigm called incremental pipelines. Out of the box, Hudi tracks all changes (appends, updates, deletes) and exposes them as change streams. With record-level indexes you can more efficiently leverage these change streams to avoid recomputing data and just process changes using incremental updates. While other data lake platforms may enable a way to consume changes incrementally, Hudi is designed from the ground up to efficiently enable incremental workflows, which results in cost-efficient ETL pipelines at lower latencies.
Databricks recently developed a similar feature they call change data feed, which they held as proprietary until it was finally released to open source in Delta Lake 2.0. Iceberg has an incremental read, but it only allows you to read incremental appends, not updates and deletes - which are essential for true change data capture (CDC) and transactional data within a data lakehouse.
Concurrency Control
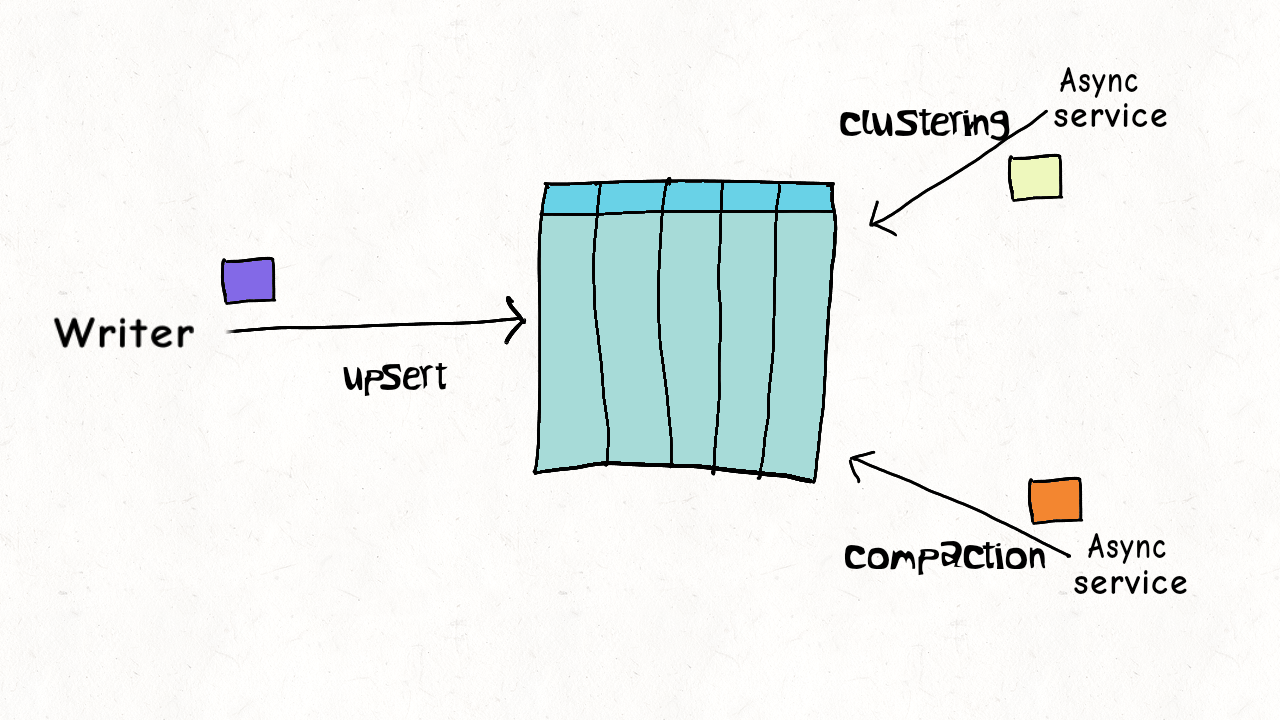
ACID transactions and concurrency control are key characteristics of a data lakehouse, but how do current designs actually stack up compared to real-world workloads? Hudi, Delta, and Iceberg all support optimistic concurrency control (OCC). In optimistic concurrency control, writers check if they have overlapping files; if a conflict exists, they fail the operations and retry. For Delta Lake, as an example, this was just a Java virtual machine (JVM)-level lock held on a single Apache Spark™ driver node - which meant you had no OCC outside of a single cluster, until recently.
While this may work fine for append-only immutable datasets, optimistic concurrency control struggles with real-world scenarios, which introduce the need for frequent updates and deletes - either because of the data loading pattern or due to the need to reorganize the data for better query performance.
Oftentimes, it’s not practical to take writers offline for table management to ensure the table is healthy and performant. Apache Hudi concurrency control is more granular than other data lakehouse platforms (file-level), and with a design optimized for multiple small updates/deletes, the conflict possibility can be largely reduced to negligible in most real-world use cases.
You can read more details in this blog as to how you can operate with asynchronous table services even in multi-writer scenarios, without the need to pause writers. This achieves a level of concurrency very close to the level supported by standard databases.
Merge On Read
Any good database system supports different trade-offs between write performance and query performance. The Hudi community has made some seminal contributions in terms of defining these concepts for data lake storage across the industry. Hudi, Delta, and Iceberg all write and store data in Apache Parquet files. When updates occur, these Parquet files are versioned and rewritten. This write mode pattern is what the industry now calls copy on write (CoW). This model works well for optimizing query performance, but can be limiting for write performance and data freshness.
In addition to CoW, Apache Hudi supports another table storage layout called merge on read (MoR). Merge on read stores data using a combination of columnar Parquet files and row-based Apache Avro log files. Updates can be batched up in log files that can later be compacted into new Parquet files, synchronously or asynchronously, to balance maximum query performance and lower write amplification.

Thus, for a near real-time streaming workload, Hudi could use the more efficient row-oriented formats, and for batch workloads, the Hudi format uses the vectorizable, column-oriented format with seamless merging of the two formats when required. Many users turn to Apache Hudi since it is the only project with this capability, which allows them to achieve unmatched write performance and end-to-end data pipeline latencies.
Partition Evolution
One feature often highlighted for the Apache Iceberg data lakehouse project is hidden partitioning, which unlocks what is called partition evolution. The basic idea is that when your data starts to evolve, or when you just aren’t getting the performance you need out of your current partitioning scheme, partition evolution allows you to update your partitions for new data without the need to rewrite your data.
When you evolve your partitions, old data is left in the old partitioning scheme and only new data is partitioned with your evolution. However, a table partitioned multiple ways pushes complexity to the user and cannot guarantee consistent performance if the user is unaware of, or simply fails to account for, the evolution history.
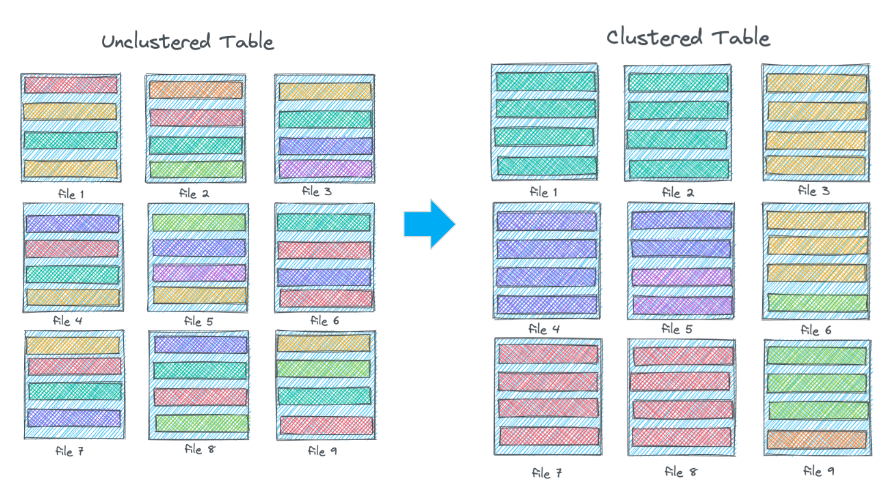
Apache Hudi takes a different approach to address the problem of adjusting data layout as your data evolves with clustering. You can choose a coarse-grained partition strategy or even leave it unpartitioned, and use a more fine-grained clustering strategy within each partition. Clustering can be run synchronously or asynchronously and can be evolved without rewriting any data. This approach is comparable to the micro-partitioning and clustering strategy of Snowflake.
Multi-Modal Indexing

Indexing is an integral capability for databases and data warehouses, yet is largely absent in data lakes. In recent releases, Apache Hudi created a first-of-its-kind high-performance indexing subsystem for the data lakehouse that we call the Hudi multi-modal index. Apache Hudi offers an asynchronous indexing mechanism that allows you to build and change indexes without impacting write latency. This indexing mechanism is extensible and scalable to support any popular index techniques, such as Bloom, hash, bitmap, R-tree, and others.
These indexes are stored in the Hudi metadata table, which is stored in cloud storage next to your data. In this new release the metadata is written in optimized, indexed file formats which results in 10-100x performance improvements for point lookups versus Delta or Iceberg generic file formats. When testing real-world workloads, this new indexing subsystem results in 10-30x overall query performance.
Ingestion Tools
What sets a data platform apart from data formats are the operational services available. A differentiator for Apache Hudi is the powerful data ingestion utility called DeltaStreamer. (“Delta” refers to changes to data, not to a particular data lakehouse project.) DeltaStreamer is battle-tested and used in production to build some of the largest data lakes on the planet today. DeltaStreamer is a standalone utility which allows you to incrementally ingest upstream changes from a wide variety of sources such as DFS, Kafka, database changelogs, S3 events, JDBC, and more.
Iceberg has no solution for a managed ingestion utility, and Delta Autoloader remains a Databricks-proprietary feature that only supports cloud storage sources such as S3.
Use Cases - Examples from the Community
Feature comparisons and benchmarks can help newcomers orient themselves on what technology choices are available, but more important is sizing up your personal use cases and workloads to find the right fit for your data architecture. All three of these technologies, Hudi, Delta, Iceberg have different origin stories and advantages for certain use cases. Hudi, the original data lakehouse project, was born at Uber to power petabyte-scale data lakes in near real-time, with painless table management. Iceberg was born at Netflix and was designed to overcome cloud storage scale problems such as file listings. Delta was born at Databricks and it has deep integrations and accelerations when using the Databricks Spark runtime.
From years of engaging in real-world comparison evaluations in the community, Apache Hudi routinely has a technical advantage when you have mature workloads that grow beyond simple append-only inserts. Once you start processing many updates, start adding real concurrency, or attempt to reduce the end-to-end latency of your pipelines, Apache Hudi stands out as the industry leader in performance and feature set.
Here are a couple examples and stories from the community who independently evaluated and decided to use Apache Hudi:
- Peloton -
“The Data Platform team at Peloton is responsible for building and maintaining the core infrastructure that powers analytics, reporting, and real-time data applications. Peloton's transition to Apache Hudi yielded several measurable improvements:
- Ingestion frequency increased from once daily to every 10 minutes.
- Reduced snapshot job durations from an hour to under 15 minutes.
- Cost savings by eliminating read replicas and optimizing EMR cluster usage.
- Time travel support enabled retrospective analysis and model re-training.
- Improved compliance posture through structured deletes and encrypted PII.”
- Uber -
“At Uber, the Core Services Data Engineering team supports a wide range of use cases across products like Uber Mobility and Uber Eats. One critical use case is computing the collection - the net payable amount - from a trip or an order. To solve this problem at scale, Uber re-architected their pipelines using Apache Hudi to enable low-latency, incremental, and rule-based processing. The improvements were substantial and measurable:
- Runtime reduced from ~20 hours to ~4 hours (~75% improvement)
- Test coverage increased to 95% for transformation logic
- Single run cost reduced by 60%”
This story describes how Amazon Transportation Services (ATS) implemented an Apache Hudi-based data lakehouse to handle massive data ingestion challenges and highly mutable workloads at scale.
“One of the biggest challenges Amazon Transportation Service faced was handling data at petabyte scale with the need for constant inserts, updates, and deletes with minimal time delay, which reflects real business scenarios and package movement to downstream data consumers.”
“In this post, we show how we ingest data in real time in the order of hundreds of GBs per hour and run inserts, updates, and deletes on a petabyte-scale data lake using Apache Hudi tables loaded using AWS Glue Spark jobs and other AWS server-less services including AWS Lambda, Amazon Kinesis Data Firehose, and Amazon DynamoDB”
This ByteDance/TikTok scenario involves even larger datasets and shows Hudi being chosen after careful consideration of all three data lakehouse projects.
“In our scenario, the performance challenges are huge. The maximum data volume of a single table reaches 400PB+, the daily volume increase is PB level, and the total data volume reaches EB level.”
“The throughput is relatively large. The throughput of a single table exceeds 100 GB/s, and the single table needs PB-level storage. The data schema is complex. The data is highly dimensional and sparse. The number of table columns ranges from 1,000 to 10,000+. And there are a lot of complex data types.”
“When making the decision on the engine, we examine three of the most popular data lake engines, Hudi, Iceberg, and DeltaLake. These three have their own advantages and disadvantages in our scenarios. Finally, Hudi is selected as the storage engine based on Hudi's openness to the upstream and downstream ecosystems, support for the global index, and customized development interfaces for certain storage logic.”

Walmart, with roughly 11,000 stores worldwide, selling more than $1M on average per store each week, deals with data at massive scale and criticality.
From video transcription:
“Okay so what is it that enables us for us and why do we really like the Hudi features that have unlocked this in other use cases? We like the optimistic concurrency or MVCC controls that are available to us. We've done a lot of work around asynchronous compaction. We're in the process of looking at doing asynchronous compaction rather than inline compaction on our merge on read tables.
We also want to reduce latency and so we leverage merge-on-read tables significantly because that enables us to append data much faster. We also love native support for deletion. It's something we had custom frameworks built for things like CCPA and GDPR where somebody would put in a service desk ticket and we'd have to build an automation flow to remove records from HDFS, this comes out of the box for us.
Row versioning is really critical. Obviously a lot of our pipelines have out of order data and we need the latest records to show up and so we provide version keys as part of our framework for all upserts into the Hudi tables.
The fact that customers can pick and choose how many versions of a row to keep to be able to provide snapshot queries and get incremental updates like what's been updated in the last five hours is really powerful for a lot of users”
Investment site Robinhood makes extensive use of change data capture (CDC) with Kafka streaming to maximize data freshness within a data lakehouse.
“Robinhood has a genuine need to keep data freshness low for the data lake. Many of the batch processing pipelines that used to run on daily cadence after or before market hours had to be run at hourly or higher frequency to support evolving use-cases. It was clear we needed a faster ingestion pipeline to replicate online databases to the data lake.”
“We are using Apache Hudi to incrementally ingest changelogs from Kafka to create data lake tables. Apache Hudi is a unified data lake platform for performing both batch and stream processing over data lakes. Apache Hudi comes with a full-featured out-of-the-box Spark based ingestion system called DeltaStreamer, with first-class Kafka integration and exactly-once writes. Unlike immutable data, our CDC data have a fairly significant proportion of updates and deletes. Hudi Deltastreamer takes advantage of its pluggable, record-level indexes to perform fast and efficient upserts on the data lake tables.”
Cloud-based customer service provider Zendesk also uses CDC extensively with their Hudi lakehouse on Amazon.
“The data lake pipelines consolidate the data from Zendesk’s highly distributed databases into a data lake for analysis.
Zendesk uses Amazon Database Migration Service (AWS DMS) for change data capture (CDC) from over 1,800 Amazon Aurora MySQL databases in eight AWS Regions. It detects transaction changes and applies them to the data lake using Amazon EMR and Hudi.
Zendesk ticket data consists of over 10 billion events and petabytes of data. The data lake files in Amazon S3 are transformed and stored in Apache Hudi format and registered on the AWS Glue catalog to be available as data lake tables for analytics querying and consumption via Amazon Athena.”
GE Aviation also uses Apache Hudi to manage CDC pipelines, enabling rapid increases in scale.
“The introduction of a more seamless Apache Hudi experience within AWS has been a big win for our team. We’ve been busy incorporating Hudi into our CDC transaction pipeline and are thrilled with the results. We’re able to spend less time writing code managing the storage of our data, and more time focusing on the reliability of our system. This has been critical in our ability to scale. Our development pipeline has grown beyond 10,000 tables and more than 150 source systems as we approach another major production cutover.”
A Community that Innovates
Finally, given how quickly lakehouse technologies are evolving, it's important to consider where open source innovation in this space has come from. Below are a few foundational ideas and features that originated in Hudi and that are now being adopted into the other projects.
In fact, outside of the table metadata (file listings, column stats) support, the Hudi community has pioneered most of the other critical features that make up today’s lakehouses. The community has supported over 9,500 users with 3,500 user issues and 7,000+ Slack support threads over the last 7 years, and is rapidly growing stronger with an ambitious vision ahead. Users can consider this track record of innovation as a leading indicator for the future.
Conclusion
When choosing the technology for your Lakehouse it is important to perform an evaluation for your own personal use cases. Feature comparison spreadsheets and benchmarks should not be the end-all deciding factor, so we hope that this blog post simply provides a starting point and reference for you in your decision making process. Apache Hudi is innovative, battle-hardened and here to stay. Join us on Hudi Slack where you can ask questions and collaborate with the vibrant community from around the globe.
If you are undecided or perhaps your organization has a mix of multiple formats, you should take a look at Apache XTable which allows you to use multiple formats simultaneously.
If you would like one-to-one consultation to dive deep into your use cases and architecture, feel free to reach out at info@onehouse.ai. At Onehouse we support all 3 table formats and have decades of experience designing, building, and operating some of the largest distributed data systems in the world. We recognize that these technologies are complex and rapidly evolving. Also, it’s possible that we missed a feature or could have read the documentation more closely on some of the above comparisons. Please drop a note to info@onehouse.ai if you see that any of the comparisons above are in need of correction, so we can keep the facts in this article accurate.
Update Notes
8/11/22 - Original publish date
1/11/23 - Refresh feature comparisons, added community stats + benchmarks
1/12/23 - Databricks contributed few minor corrections
10/31/23 - Minor edits
1/31/24 - Minor update about current state of OneTable
10/8/24 - Minor update about current state of XTable (was called OneTable); added the third paragraph to refer to a relevant new blog post
10/02/25 - Refreshed comparisons with latest releases

Read More:






Subscribe to the Blog
Be the first to read new posts