Announcing Apache Spark™ and SQL on the Onehouse Compute Runtime with Quanton

Introduction
From day one, Onehouse has been committed to a bold, yet pragmatic vision: a Universal Data Lakehouse — one that embraces openness at every layer and offers the flexibility to bring your own engines, catalogs, and tools without vendor lock-in. Over the past year, we’ve steadily delivered on this vision: championing open table format interoperability with Onetable, unlocking multiple catalogs with OneSync™, automating performance tuning across engines with Table Optimizer, delivering a specialized Onehouse Compute Runtime to accelerate core lakehouse workloads, and most recently launching Open Engines™, our initiative to decouple and modularize compute around best-of-breed technologies.

Now, we’re excited to announce the next step in this journey: support for Apache Spark™ and SQL workloads on the Onehouse Compute Runtime (OCR) — powered by our new query execution engine, Quanton. This now makes Onehouse a complete solution for running any workload - ingestion, data transformation, table optimization, query engines and catalog management - with incredible price/performance while remaining truly open, flexible and modular in your data platform choices.

Starting today, Onehouse users can create new Spark and SQL cluster types on top of Onehouse Compute Runtime, which brings benefits like fast lakehouse I/O, best-in-class cluster management and efficient auto-scaling capabilities. Users can then author Spark and SQL pipelines that natively read/write data on popular open file formats and lakehouse table formats (Apache Hudi™, Apache Iceberg™, Delta Lake). Users can also enjoy improved read/write performance, compatibility and interoperability through Hudi pluggable table format support and Apache XTable™ (Incubating).
Target Use Cases
There are already many options for running SQL and Spark jobs. Naturally, we are often asked about the target use cases, where these new Onehouse capabilities can bring night-and-day improvements and add value in speed, simplicity, and costs. Below are just a few of the leading use cases where Onehouse SQL and Spark jobs can help:
Hudi - Spark jobs cost reduction
Challenge: You’re already running Hudi pipelines with AWS EMR or OSS Spark. But your costs are already too high and continue to increase. We have worked with users who spend tens of millions of dollars a year running their pipelines and are looking for a way to reduce these costs.
Value: We guarantee a >50% cost reduction in your Spark infrastructure costs, by simply pointing your existing Hudi/Spark jobs to Onehouse with no code changes. Onehouse also opens up your Hudi data to the entire cloud data ecosystem and uplevels table management.
Data Warehouse - SQL ETL cost reduction
Challenge: More than 50% of cloud data warehouse spend is on ETL pipelines, and less than 50% is on interactive querying. And warehouse costs typically increase every year with growing data volumes and use cases.
Value: We guarantee a >50% cost reduction on the ETL portion of your cloud data warehouse spend. Simply run your existing SQL transformations or dbt models on Onehouse instead of your cloud data warehouse. Onehouse will present the new tables in open table formats such as Iceberg that are compatible with your existing data warehouse. Your warehouse can query the Onehouse tables directly, performing on par with native warehouse tables. And, as an added bonus, your data on Onehouse is now open and can be shared and read with other query engines such as Databricks, Trino, Ray, and many others.
New Iceberg lakehouse
Challenge: You’re implementing an Iceberg-based lakehouse but have trouble operationalizing it for your company or can’t achieve the required performance.
Value: You can run your Spark/Iceberg pipelines on Onehouse to reduce pipeline costs by 50%. Onehouse also offers fully-managed ingestion and continuous table optimization for your tables to ensure high performance and make your journey simpler. You can query these tables with Snowflake, Databricks, Trino, Athena, and more right within Onehouse using Open Engines or any engine of your choice.
Why Spark/SQL on Onehouse?
The growing need to make Spark efficient
Spark remains the most popular engine for ETL and data pipelines on the lakehouse, due to its broad support for data formats, rich APIs for Scala/Python/SQL/Java, an ecosystem of libraries such as MLLib and being battle-tested at scale across thousands of companies. Over the years, the combination of Spark and lakehouse formats such as Hudi, Iceberg, and Delta Lake has defined the “data lakehouse stack”.
But aren’t there plenty of Spark runtimes or warehouses in the market? So, why do we need one more? Maybe these are some questions that pop into your head as you are reading this. We believe the existing Spark runtimes or SQL warehouses don’t fully utilize or integrate deeply enough with lakehouse storage for the newer demands modern data pipelines have - from achieving near real-time data freshness in your Spark pipelines or executing SQL ETLs for modelling a star-schema while minimizing I/O. It’s important to understand that most of them were built before the rise of data lakehouse storage and open table formats. They merely treat the open tables as simply reading/writing tables in a “different” format than, say, Apache Parquet or Apache ORC. We are filling this gap today.
ETL/ELT costs on warehouses remain largely untamed
According to Databricks, these ETL/ELT workloads amount to more than 50% of cloud warehousing costs, often responsible for the lion’s share of your cloud data costs. Yet many data teams remain unfocused on ETLs as a cost-optimization area and instead focus squarely on interactive query performance due to it being more end-user-facing. Offloading ETL pipelines from proprietary data warehouses to an open lakehouse architecture has saved organizations millions of dollars annually in cloud compute and storage costs. This shift is driven not only by the high price points, closed storage and tightly-coupled compute models of warehouses, but also by the increasingly powerful capabilities in open data lakehouse formats. With features such as incremental data processing, record-level updates and deletes, incremental clustering, and asynchronous compaction, users can significantly lower I/O costs, reduce job runtimes, and tightly control data freshness — all while keeping data in affordable object storage in open formats. These capabilities allow organizations to run high-throughput ETL jobs at a fraction of the cost, without compromising SLAs or flexibility.
Strengthening the Open Data Lakehouse
Centralizing Spark and SQL ETL pipelines within Onehouse enables organizations to embrace a genuinely open and modular data architecture that decouples compute logic from being tightly tied to any single data warehouse or proprietary runtime. By leveraging Onehouse’s support for open table formats and interoperable catalogs via OneSync™, companies can leverage the same transformation output across multiple engines — from Spark to Trino to Snowflake to Ray — without rewriting pipelines or duplicating infrastructure. This consolidation not only simplifies orchestration and governance (e.g., GDPR deletes performed once), but also breaks the cycle of vendor lock-in by ensuring your data and logic remain portable and engine-agnostic.
Onehouse is the most open cloud data platform in the market today, with support for open table formats, open/closed data catalogs and open/closed compute engines. Combined with using 100% open-source compatible Spark/SQL interfaces on top of Quanton, your ETL logic remains portable outside of Onehouse and avoids lock-ins even to Onehouse itself. The interoperability also allows users to selectively move their more expensive ETLs off data warehouses to Quanton, while leaving the rest of the ETLs and queries unchanged.
The Difference: Quanton Query Execution Engine
Now that you understand the motivation for Spark and SQL inside Onehouse, let’s also discuss how our radical new approach also comes with 2-3x price-performance advantages.
Most query engines in the market are generic and stateless, in the sense that they have a singular focus on optimizing compute for query execution using standard techniques such as vectorized query execution to unlock hardware acceleration, better query planning/optimization based on statistics or rules, and intelligent selection of join algorithms. We incorporate these standard techniques as well, but these approaches still lack a deeper integration into lakehouse storage to understand how data is evolving as writes happen. This results in the engine performing work proportional to the size of the tables involved, regardless of the actual differential work necessary for the relational operator being executed. Quanton intelligently exploits a key observation in ETL workload patterns to minimize the quantum of work performed in each ETL run, instead of naively attempting to run as fast as possible.
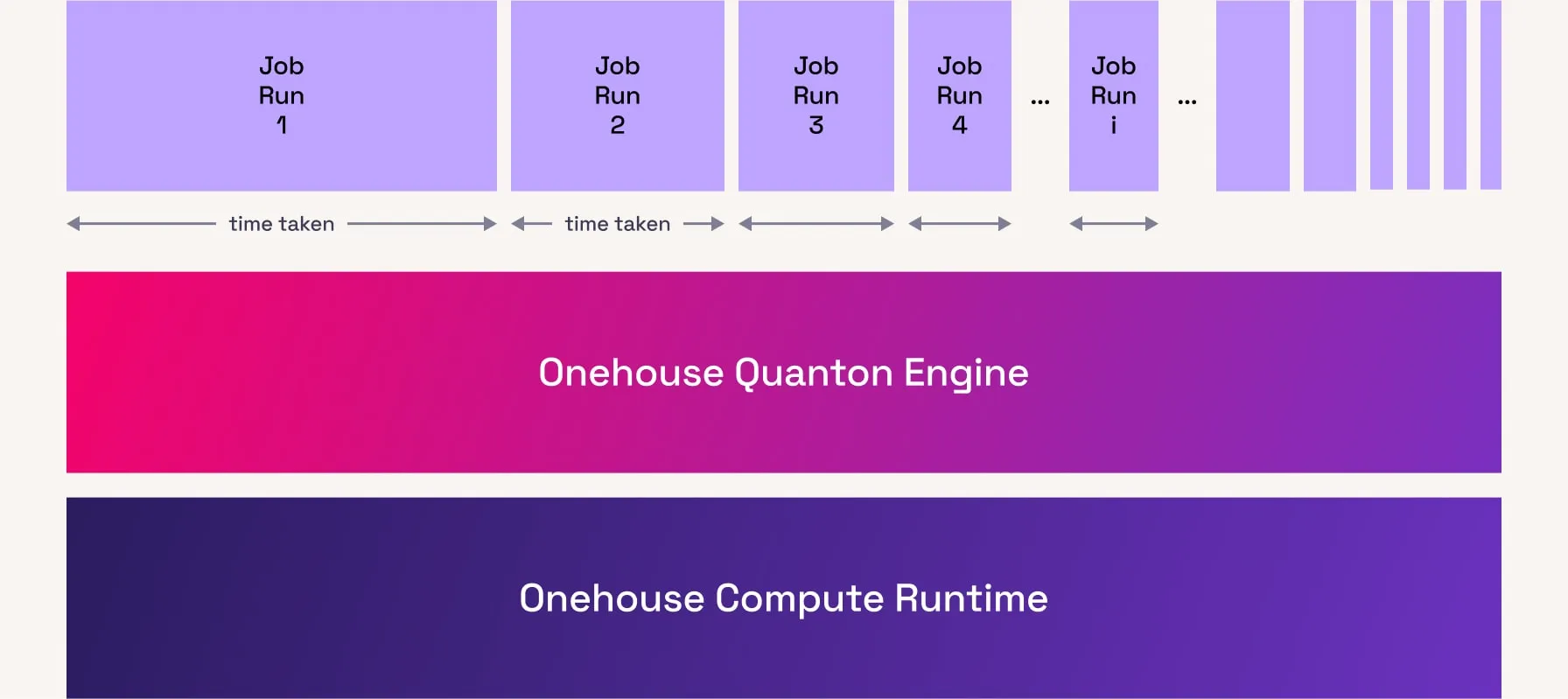
Specifically, we recognize that a lot of ETL computations repetitively run the same SQL query plan over and over on the same set of input tables. The ETL transformation logic does not change much in stable state data pipelines in production (compared to ad hoc queries or exploratory data science analysis, which can change rapidly as data analysts/data scientists explore the data). Most ETL pipelines incorporate schema changes or business logic changes once every few weeks, while repeatedly running the same underlying SQL plan every few hours or minutes depending on needs. This presents us with ample opportunity to amortize compute, network and storage resources across each run of the ETL pipeline. Quanton precisely performs only the minimal necessary work in each run of the ETL pipeline, while still generating the same output into the target table. Based on this principle, Quanton is able to scale costs across scan (Extraction), Transformation and write (Load) stages proportional to the actual relational operation being performed.
Our vision is to be able to accelerate existing batch SQL/Spark workloads in place, using Quanton, without needing specialized streaming systems for lower latency or porting code/SQL over to newer processing models. We are seeing some impressive results (sections below) already with the early versions of Quanton and the engine is under very active development at Onehouse to unlock even greater speed/efficiency. We will be unwrapping more pieces of the Quanton engine in the coming months with technical deep dives and whitepapers on relevant topics, along with our relative progress on compute efficiency and performance.
Spark On Onehouse
Creating Spark Clusters
Launching Spark workloads with Quanton on the Onehouse Compute Runtime (OCR) is straightforward. Simply define a Cluster, with a type of either 'Spark' for general Spark code workloads or 'SQL' for Spark SQL, to instantly provision autoscaling compute resources. That’s it. Quanton does not need special clusters with special pricing, it’s just enabled by default.

Next, define a Job by referencing your existing JAR or Python files on cloud storage, specifying the same parameters you would use for a spark-submit on any other Apache Spark platform.

Trigger Job Runs easily and gain real-time insights through live monitoring and comprehensive logs available directly in the Onehouse console.

These functionalities are also available through APIs, making the platform extensible for any existing or future tools you’d like to use for your Spark workflows.
Comparison with Legacy Spark Runtimes like AWS EMR
After years of running Apache Spark jobs and supporting users of platforms such as AWS EMR, we developed Onehouse as the Spark platform we always dreamed of: a runtime and engine deeply integrated with data lakehouse storage for optimal performance and a seamless developer experience. We believe that every team running a data lakehouse should experience it on a compute platform explicitly crafted with a deep understanding of these emerging lakehouse workloads.
Scalable, Serverless Compute Across ALL YOUR Clouds
Jobs run on the Onehouse Compute Runtime (OCR) dramatically reduce the manual effort in getting your pipelines running reliably and efficiently. On OCR, your Spark configurations are simplified with optimal defaults that dynamically adapt to your workloads. Clusters automatically scale up and down, leveraging a deep integration between Spark and lakehouse storage/compute for optimal resource utilization. By fully managing these clusters in a serverless fashion, we minimize the ongoing effort typically involved in cluster management and upgrades. Last but not the least, compute runs within your own private networks, allowing you to keep data secure and take advantage of existing discounts such as reserved instances.
Deep storage integration
When it comes to storage, Onehouse keeps your tables running optimally. After a Onehouse job creates a new Hudi, Iceberg, or Delta Lake table, automatic asynchronous table services optimize your data, ultimately reducing query duration and compute bills. A lock provider is built into the platform, removing any need for you to manage external services for coordinating writes to your tables. Jobs marry the compute and storage layers, automatically applying configurations for your lock provider, indexes, and more for the most cohesive developer experience on the data lakehouse.

Simplified Monitoring & Debugging
Jobs on Onehouse are dead-simple to monitor and debug. Onehouse exposes the Job status and driver logs through the UI, and provides access to the Spark UI directly in your browser. Everything you need to know about your Spark jobs is a click away.

E2E Observability & Cost Transparency
Observability is ingrained from the engine layer down through storage, enabling you to easily uncover performance bottlenecks whether they come from sub-optimal Spark configurations or data skew in your tables. Clusters can be tracked from a single pane of glass, allowing you to easily understand the costs per job and quickly get ahead of out-of-control compute or insufficient resources for bursty workloads.

Interoperability and Compatibility
All of these capabilities are packaged into a modern, interoperable platform to maintain ongoing compatibility with all your other tools and engines. When you write to tables with Jobs, Onehouse syncs those changes across all your catalogs with OneSync and orchestrates metadata translations with XTable for compatibility across all formats (Apache Hudi, Apache Iceberg, Delta Lake, and emerging lakehouse formats in the future).
Expert Support
Lastly, and maybe most importantly, Onehouse Jobs is backed by a team that has operated the world’s most demanding data lakehouse workloads at planet-scale (such as Apache Hudi at Uber). We offer expert support to help with everything from choosing the right indexes to modeling data to understanding deep out-of-memory (OOM) errors.
SQL on Onehouse
Creating SQL Endpoints
Onehouse SQL extends the benefits of our compute platform to your SQL workflows, providing familiar Spark SQL interfaces with enhanced performance and ease of use. Simply create a SQL Cluster, then connect via JDBC from your preferred SQL client.

Better yet, leverage Onehouse’s built-in SQL Editor designed for lakehouse workloads. It suggests and highlights lakehouse-specific SQL syntax such as PARTITION BY and CREATE INDEX, streamlining query development and execution directly in the browser.

Ecosystem Integrations
Working with the Quanton engine is seamless, thanks to SQL and Spark’s rich ecosystem and the integrations we’ve built into the Onehouse platform. Onehouse provides Spark and SQL compatibility, allowing you to use your data with any tool or library in the ecosystem. Below are some of the most commonly-used integrations:
Use Case: Orchestrate Jobs or SQL with Airflow
With minimal changes to your existing workflows, you can use Onehouse Airflow operators to orchestrate Spark Jobs and Clusters. This means leveraging your existing Airflow knowledge and infrastructure to quickly gain the performance benefits of Quanton and OCR.
from datetime import datetime
from airflow import DAG
from airflow.utils.helpers import chain
from airflow.providers.onehouse.operators.jobs import (
OnehouseCreateJobOperator, OnehouseRunJobOperator, OnehouseDeleteJobOperator
)
from airflow.providers.onehouse.sensors.onehouse import OnehouseJobRunSensor
with DAG(
"quanton_spark_job",
default_args=default_args,
start_date=datetime(2025, 4, 28),
schedule_interval=None,
catchup=False,
tags=["onehouse", "real", "test"],
) as dag:
create, run, wait, delete = (
OnehouseCreateJobOperator(
task_id="create",
job_name=job_name,
job_type="PYTHON",
parameters=[{{ create_job_params }}],
cluster="Apache Spark",
conn_id="onehouse_default",
),
OnehouseRunJobOperator(
task_id="run",
job_name="{{ ti.xcom_pull('create') }}",
conn_id="onehouse_default",
),
OnehouseJobRunSensor(
task_id="wait",
job_name="{{ ti.xcom_pull('create') }}",
job_run_id="{{ ti.xcom_pull('run') }}",
conn_id="onehouse_default",
poke_interval=30,
timeout=3600,
),
OnehouseDeleteJobOperator(
task_id="delete",
job_name="{{ ti.xcom_pull('create') }}",
conn_id="onehouse_default",
),
)
chain(create, run, wait, delete)Use Case: Run dbt Pipelines
Point existing DBT workloads to Onehouse as the execution engine by updating your JDBC connection, instantly benefiting from enhanced performance and simplified management.

Putting to the test against the best
Last week, we laid out a thorough benchmarking framework for ETL price-performance, grounded on established industry benchmarks like tpc-ds. We also made it meaningful by incorporating real-world L workload patterns using our open-source tool Lake Loader. We also provided a practical methodology to normalize the performance of each data platform, based on its price point. We strapped Quanton to the same benchmarking apparatus we advocated for and measured the price/performance of running the ETL workloads.
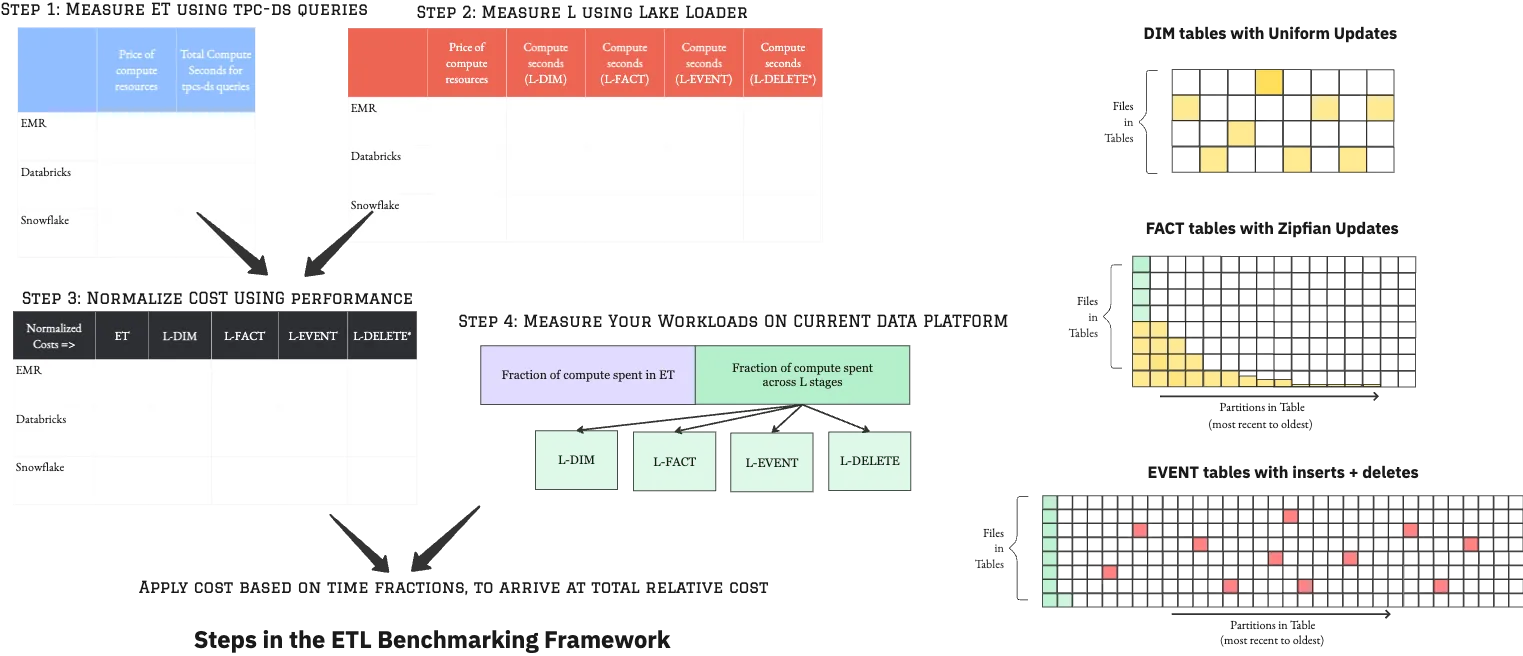
Initially, we were tempted to compare Quanton against OSS Spark, like many other benchmarks out there. However, given that the data platforms in the earlier blog have already clearly established better price/performance compared to OSS Spark, it would be more beneficial for users to compare Quanton against them instead.
We used enterprise versions across Snowflake and Databricks to have comparable functionality. EMR, Databricks and Onehouse use the latest cost-effective Graviton CPU architecture on AWS wherever it's possible for the users to configure. We enabled photon for all Databricks runs. Snowflake Gen 2 clusters are consistently faster than the current generation. However, they are currently priced higher, affecting the total price/performance in our tests. Snowflake and Databricks cluster sizes were “medium” wherever applicable.
For the L part of the benchmarking, we measured the ETL load times after 25 rounds of incremental loads, to get a stable state performance after giving enough time for the table size and overhead to build up. We believe the results above are only a conservative estimate for Quanton’s speedup, given that ETL pipelines are scheduled to run for days and months continuously, as opposed to a few hours of test rounds in this experiment. Specifically, many of the compared data platforms become increasingly slower with table sizes (which only grow if run for days). In contrast, Quanton is specifically designed to scale more closely to the quantum of work, transformation and loading performed in the ETL runs.
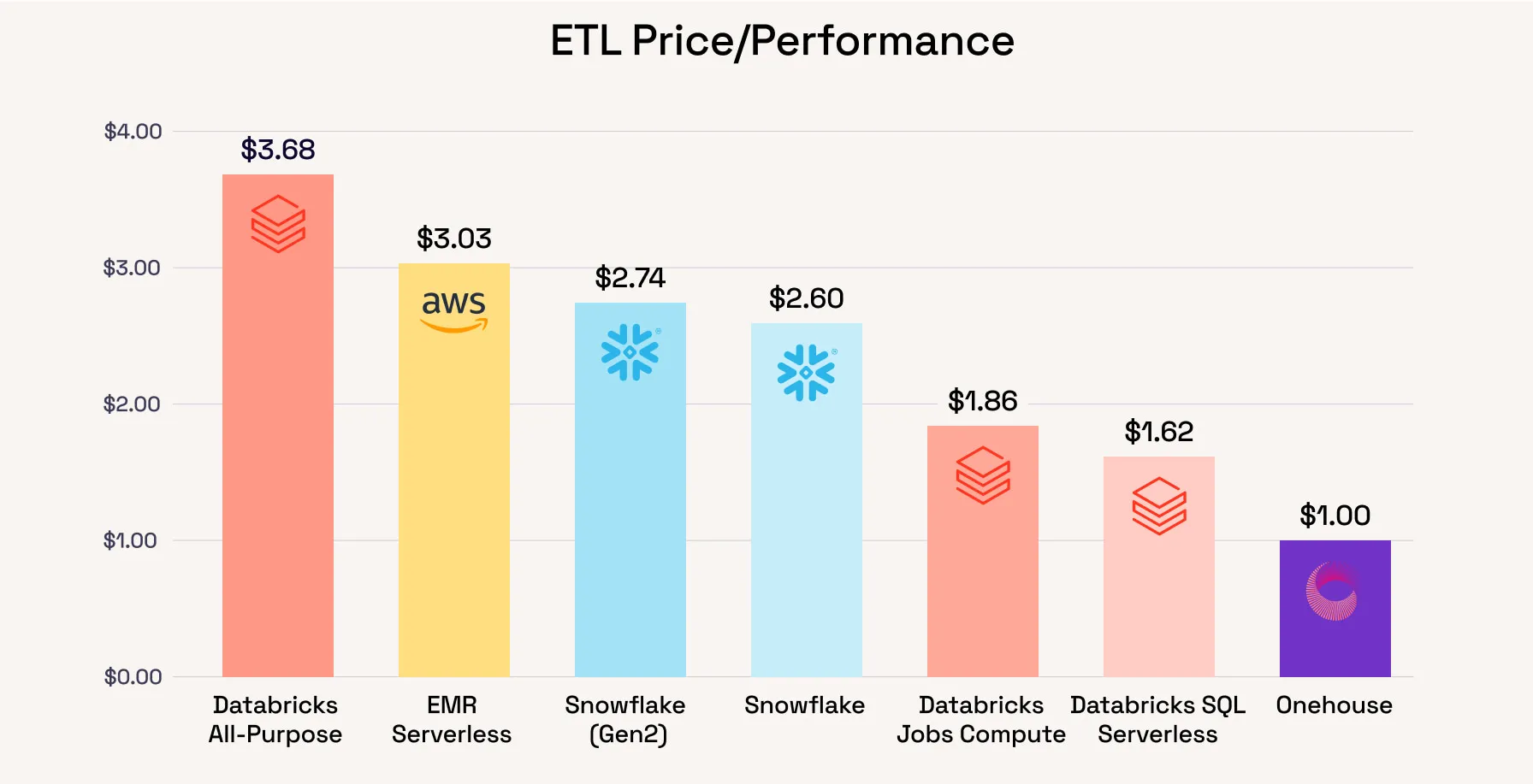
Based on these results, Quanton unlocks a wide range of 62%-268% ETL cost efficiency compared to other data platforms. To put this into a real-world scenario, if you are currently spending $1 million on a data platform, Onehouse can achieve the same performance at costs ranging from $272K-$617K, generating new budgets for your data + AI workloads, freeing up your precious engineering resources or simply putting money back into your pockets.
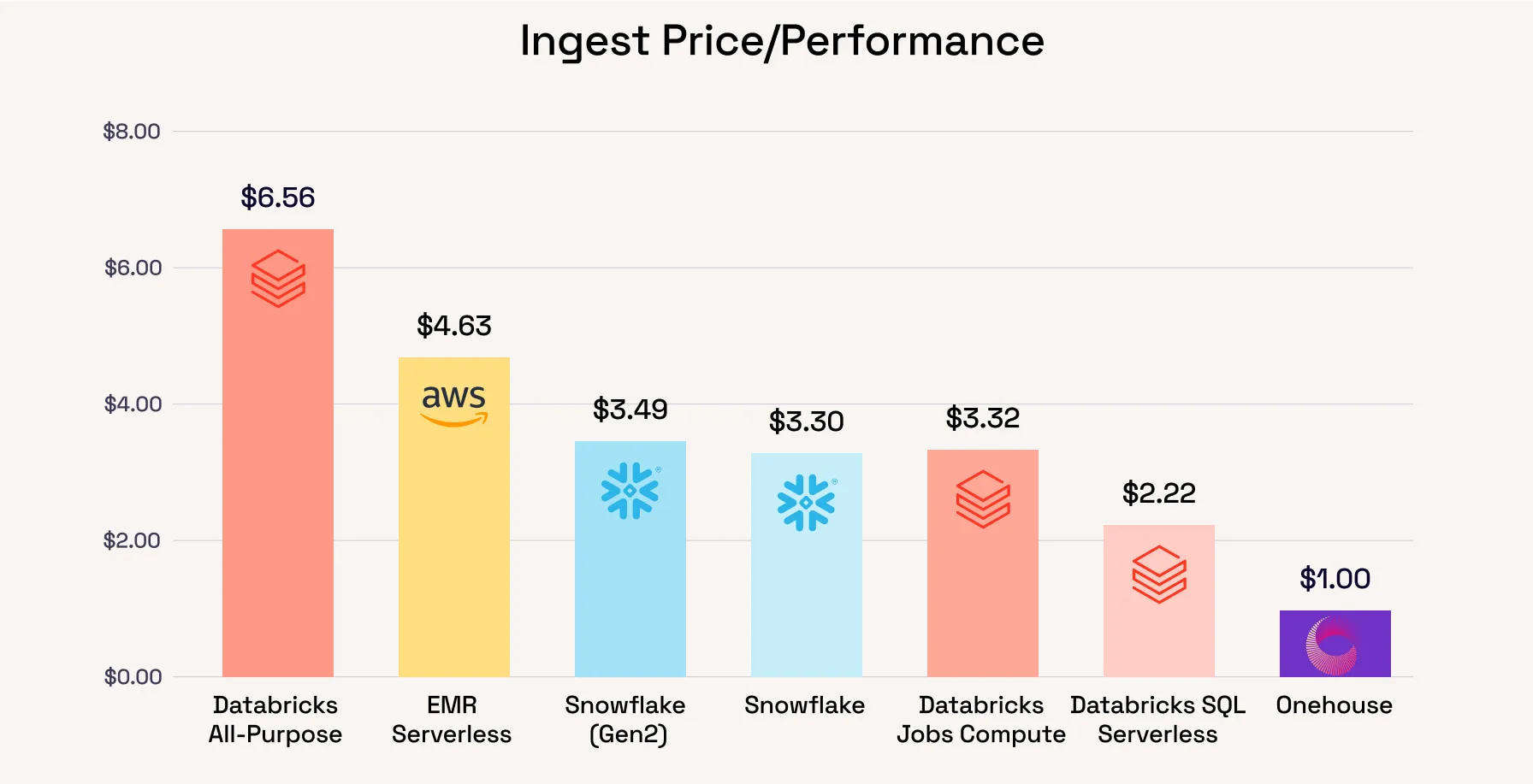
As you know, your mileage will vary based on your actual workloads. The figure above shows the much higher gains Quanton can unlock when running ingestion workloads. Below, we’ve included the calculator we showed in the earlier benchmarking blog, and Onehouse has now been added so users can explore different combinations of workloads easily.
All that being said, we also understand and appreciate that users ultimately care about performance on their own data and workloads. To help with this, we have also developed and open-sourced a Spark cost analysis tool that runs against your existing Spark history server. The tool analyzes the Spark stages and splits them into E/T/L workload phases. Based on this analysis, Onehouse can provide FREE customized impact estimates for your workloads.
Download the Spark Cost Analysis Tool
Conclusion
In summary, ETL workloads are among the most compute-intensive and expensive in your data stack, representing the single largest line item in your cloud compute bill. With Spark Jobs and SQL now available on Onehouse via Quanton, we aim to help companies perform their core ingest and ETL transformations in the most cost-effective way there is today.
Quanton is uniquely engineered to process only the smallest quantum of data necessary. By deeply integrating innovations such as intelligent lakehouse I/O, efficient serverless cluster management, and a uniquely ETL-aware execution model, Quanton ensures you touch only the minimal data required, delivering at least 2-3x better cost/performance than leading market solutions.
This means you can seamlessly consolidate your existing Spark and SQL workloads onto an optimized, fully interoperable data platform—without worrying about vendor lock-in. Onehouse not only simplifies your operational overhead but also unlocks significant budget savings, allowing your team to reinvest those savings into new initiatives and innovations. For Hudi users, you can simply run your Streamer tool and Spark jobs on Onehouse to realize dead-simple cost savings.
Curious to understand how Onehouse can help you reduce costs in your environment? Check out the resources below to get your own cost evaluation:
- Spark Cost Analyzer: Point this tool at your Spark history server to analyze past jobs and produce a detailed report with quantified optimization opportunities.
- 30 Minutes for 30% Savings: Give us 30 minutes of your time, and we’ll show you how Onehouse can save you at least 30% on your ETL pipeline costs, guaranteed!



Read More:






Subscribe to the Blog
Be the first to read new posts