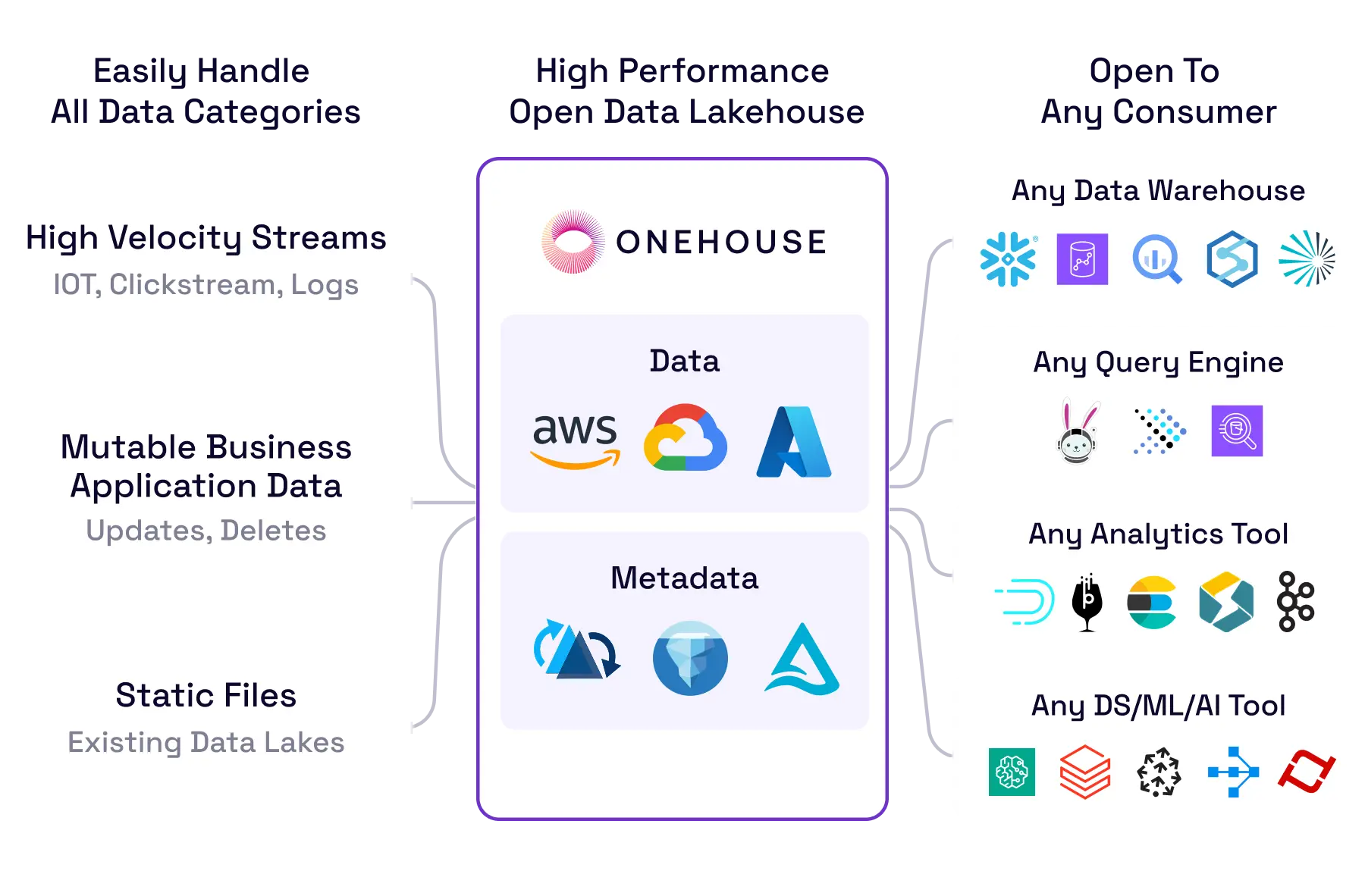
INFRASTRUCTURE Solution
The Fastest Lakehouse for Snowflake
Separate ETL and Storage from Analytics
Slash Costs by >50%
- Reduce Snowflake Costs by 30% to 80%: Transfer expensive ELT to a data lakehouse for efficient data ingestion and merges in open formats.
- Simplify Snowflake Use: Enable fast querying on structured gold tables in Snowflake, and offload expensive ETL/ELT tasks to Onehouse.
- Flexible Scaling: Independently adjust storage and compute in a lakehouse setting using cloud storage in open formats for efficient resource use and cost savings.

Superior Pipeline Flexibility and Efficiency
- Faster Performance: Leverage Hudi™ to rapidly ingest and transform data for Iceberg's open table formats for faster data processing and querying with Snowflake.
- Cost-Effectiveness: Manage Iceberg tables independently in a lakehouse environment for reduced storage and processing costs.
- Enhanced Interoperability: Support a versatile data ecosystem with the capability to read from and write to Iceberg tables across multiple systems.
No Vendor Lock-In & Enhanced Data Accessibility
- Interoperability Across Platforms: Store data in formats like Apache Iceberg™, Delta Lake, and Apache Hudi™, and select the best query engine for each task.
- Future-Proof Data Architecture: Foster innovation by avoiding vendor lock-in to easily adapt to evolving requirements and emerging technologies.
- Easier Snowflake Integration: Efficiently handle large data volumes across all applications, from analytics to AI, without limits from proprietary tech.
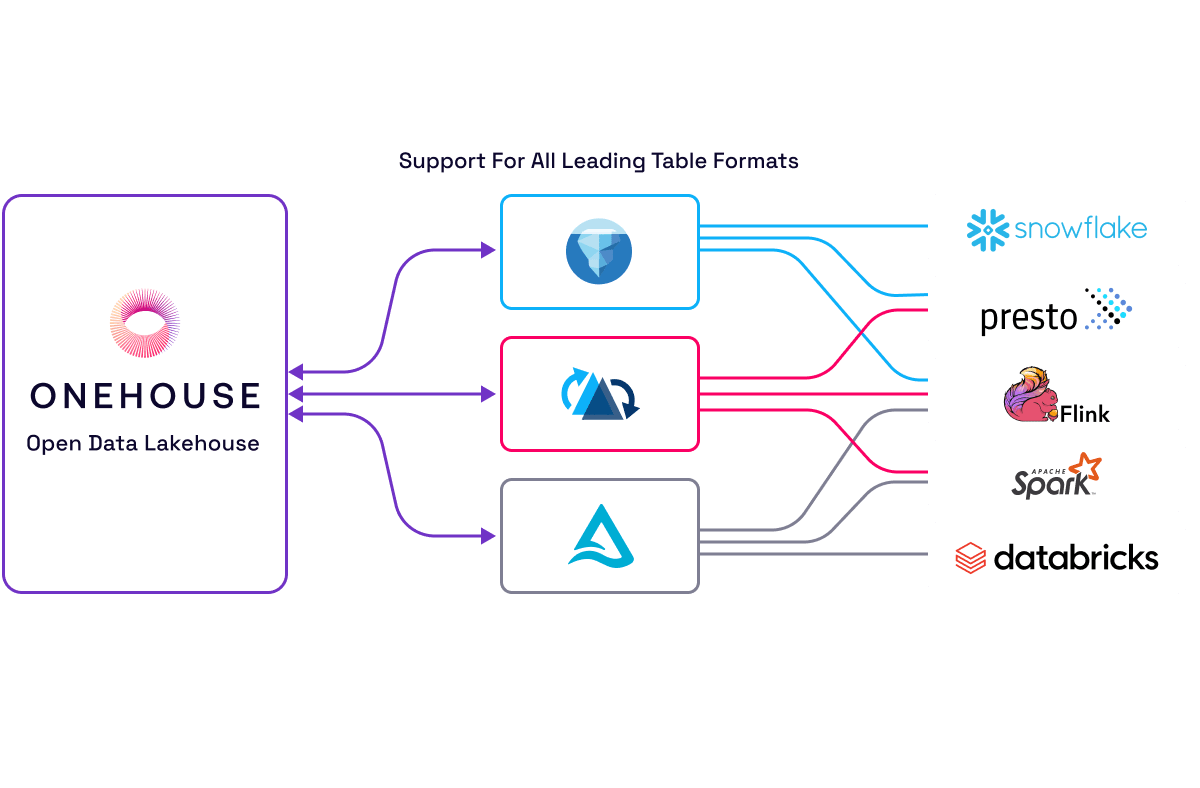
Decoupling ETL and Storage from Compute for Analytics: An Open Architecture Approach

Key Features to Maximize Your Snowflake Environment

Fully Managed Data Lakehouse
Experience the convenience of a managed data lakehouse where ETL workloads are handled by Onehouse while analytical tasks are efficiently executed in Snowflake.

Read-Write Interoperability
Maintain data in open data table formats (Apache Hudi, Apache Iceberg, and Delta Lake), achieve read-write interoperability across all three tables using XTable™, and effortlessly integrate your preferred query engines and data warehouses to support analytics workloads.

Incremental Processing
Built to accommodate high-velocity streaming workloads with ease, Onehouse provides continuous, low-latency ingestion of data from various sources into the data lakehouse and can process changes incrementally to avoid recomputing data aggregations, resulting in massive cost savings and low-latency pipelines.

Automated Iceberg Table Management
When integrating Onehouse with Snowflake, Onehouse automates the creation and continuous management of Iceberg tables, handling schema evolution and other synchronizations to keep tables and data up-to-date in Snowflake.

Streamlined ETL/ELT in the Lakehouse
Onehouse uses metadata files to register Apache Iceberg tables to Snowflake, essentially letting you manage the ingestion and ETL work — including providing you with easier ways to clean, process, and validate your data — inside the lakehouse.

Real-world experiences show that replacing Snowflake's "Merge_Into_Raw" with Apache Hudi's optimized Spark on EKS for high-scale mutable workloads reduced compute costs from $1 million to $300K annually, achieving about 70% in savings.
NOTION’S JOURNEY
Optimize Your Snowflake Environment with Onehouse
No items found.
No items found.
Data sheet
Onehouse Iceberg for Snowflake
Download now
No items found.
No items found.
No items found.
No items found.
No items found.
No items found.
No items found.
Ready to unlock the inevitable warehouse-to-Onehouse switch?
let's talk