How to Save Apache Iceberg™ from Chilly Meltdown When Dimensions Too Hot to Handle

In a recent post, "When Dimensions Change Too Fast for Iceberg," the author calls out a key issue: Apache Iceberg’s design hits performance challenges when tables need frequent updates and deletes. Rapidly changing dimensions or nonstop streaming data force users to make trade-offs between write and read performance.
Apache Hudi™ takes a different approach. It was built for fast updates, deletes, and streaming writes—perfect for real-time pipelines and evolving dimensions. Struggle with Iceberg's upsert performance but prefer to keep Iceberg tables for reads? Use Hudi for what it excels at—writes—and then leverage Apache XTable™ (incubating) to make that data available as native Iceberg tables. In the following sections, we'll first delve into the core designs that make Hudi excel at processing mutable workloads, then show how XTable provides seamless interoperability—letting you keep your existing Iceberg-compatible query engines without missing a beat.
5 Designs that Make Hudi Better for Mutable Writes
Hudi was engineered for mutable writes from day one, with many design considerations for handling intensive updates and deletes. Let’s dive into the five core designs that make Hudi a powerhouse for mutable workloads:
- Record-Level Indexing: Delivers blazing-fast lookups by directly mapping record keys to their file locations.
- Merge-on-Read (MOR) Tables: Absorbs high-frequency changes into log files, minimizing write amplification.
- Async Compaction: Keeps MOR tables optimized in the background without blocking ongoing writes.
- Non-Blocking Concurrency Control: Unlocks high-throughput multi-writer support, allowing concurrent jobs to succeed without livelocking and retries that waste compute dollars.
- File Size Control: Maintains well-sized files through file sizing mechanisms for consistently performant writes and reads.
By exploring these key designs, you'll understand the architectural decisions that give Hudi its edge in handling mutable workloads.
Record-level Indexing
You can't have fast updates without a fast writer-side index. Hudi pioneered record-level indexing in lakehouses by maintaining a direct mapping between record keys and their file locations within the metadata table (see diagram below). The record index stores mapping entries in HFile, an indexed SSTable file format designed for high-speed lookups. Real-world benchmarks show that an HFile containing 1 million record index mappings can look up a batch of 100k records in just 600 ms.
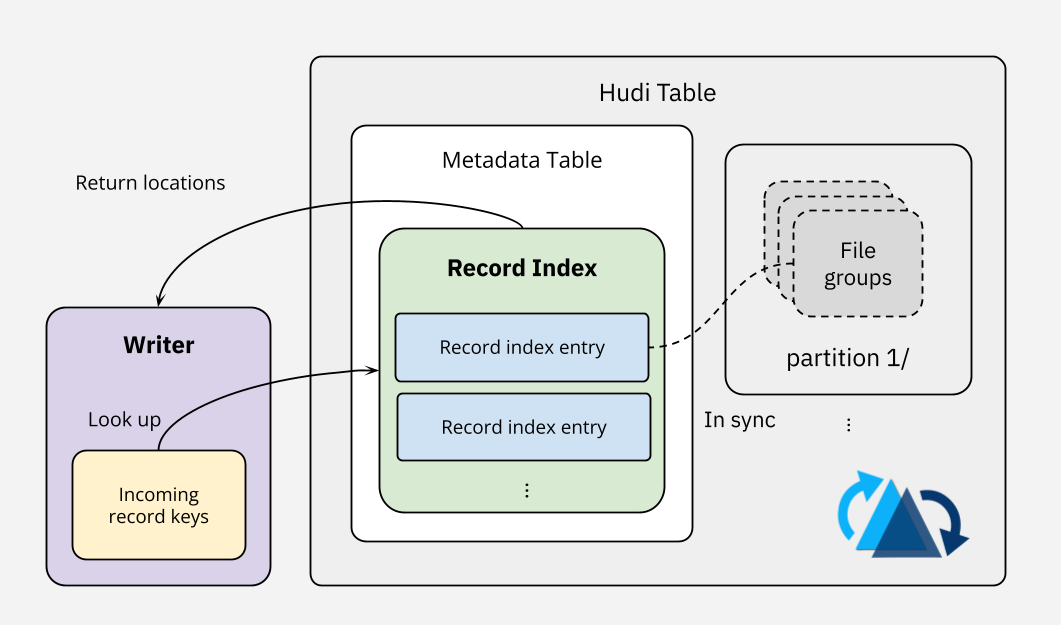
When a batch of data arrives, Hudi performs a bulk lookup against the record index using the incoming record keys. For incoming updates and deletes, the lookup returns which files to change. For new inserts, the lookup result will be empty, telling the writer to create a new record. Based on the lookup results, Hudi writers can then route records properly for writing to storage—indexing efficiency, especially at large scale, is key to delivering the overall mutable write performance.
Merge-on-Read (MOR) Tables
Lakehouses should be able to absorb high volumes of mutations without impacting write performance. Hudi’s Merge-on-Read (MOR) table type exemplifies this write-first design. When writing to MOR tables, Hudi writers efficiently append updates and deletes to log files alongside the base files containing the records to be changed—only achievable through high-performance writer indexing like the record index. By deferring record merging to a separate process (e.g., async compaction), the write process incurs minimal write amplification and thus achieves efficiency.
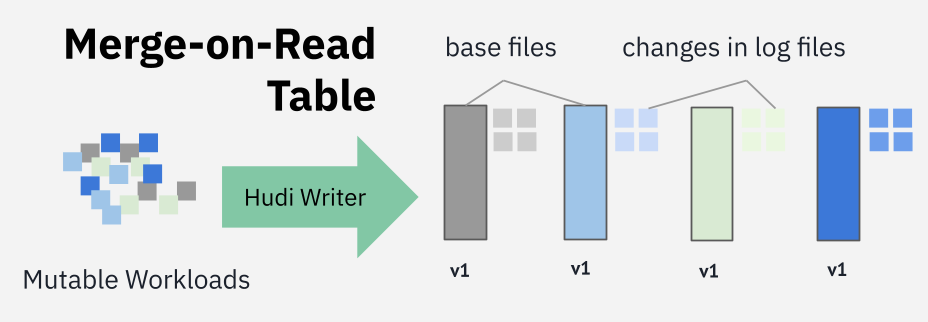
To further improve the write throughput, Hudi supports partial updates, i.e., write only the columns that have changed instead of the full schema of the changed records. For mutable workloads, particularly those involving wide tables, supporting partial updates lets Hudi minimize I/O and maximize throughput—a significant advantage in running update-intensive pipelines.
Async Compaction
Having intensive updates in MOR tables requires maintenance, but you don’t want to stop ongoing writers and affect SLAs. To address this, Hudi employs Multi-Version Concurrency Control (MVCC), which allows table services like compaction to run asynchronously without blocking active writers.

Hudi’s compaction table service is designed to merge records from log files with their corresponding base files, and then to save the merged records in new base files to serve the latest record versions. Thanks to MVCC, by configuring Hudi writers for async compaction, this merging and base file creation process can be carried out without interfering with ongoing writes and reads. Hudi also provides an out-of-the-box utility tool, Hudi Compactor, and the full-fledged ingestion tool, Hudi Streamer, to make configuring and running async compaction easy.
Non-Blocking Concurrency Control
Retries are costly at scale. Optimistic Concurrency Control (OCC) is often over-optimistically adopted in lakehouses to handle multi-writer use cases, with the hope that conflict-then-retry is rarely needed. The reality is often the opposite. A typical multi-writer scenario with one ingestion writer running alongside ad-hoc backfill jobs making random updates may end up with frequent retries using OCC, resulting in higher costs. In a multi-streaming write scenario, retries can also risk breaking SLAs.
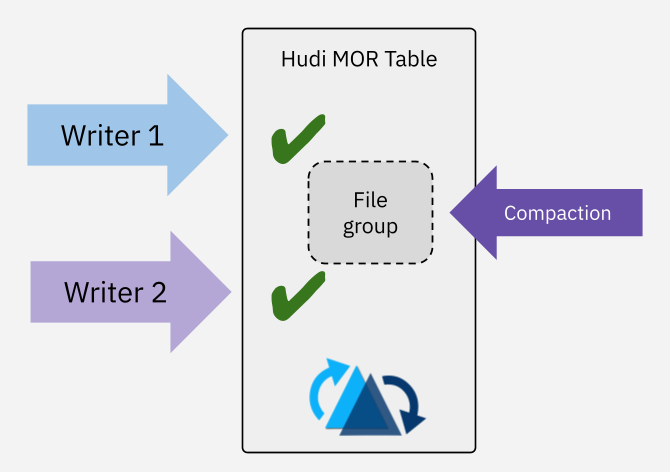
Hudi 1.0 added Non-Blocking Concurrency Control (NBCC) for MOR tables, which allows concurrent writes to succeed without being blocked or retried. Conflict resolution is deferred to a later, asynchronous compaction job that follows the table’s defined record-merging semantics. This seamless integration of NBCC with async table services provides a comprehensive and robust solution for the demanding multi-writer scenarios—a capability no other lakehouse framework can provide.
File Size Control
Small files are the top performance killer for your lakehouse. Fast and frequent writes, especially in streaming use cases, inevitably create a large number of small files, which burden indexing, incur storage overhead, and slow down queries. Hudi attacks this small-file issue with an auto file-sizing mechanism right from the writing stage. By using a bin-packing algorithm, Hudi writers assign incoming records to target file groups based on their existing sizes, ensuring the resulting files stay close to the configured target size.
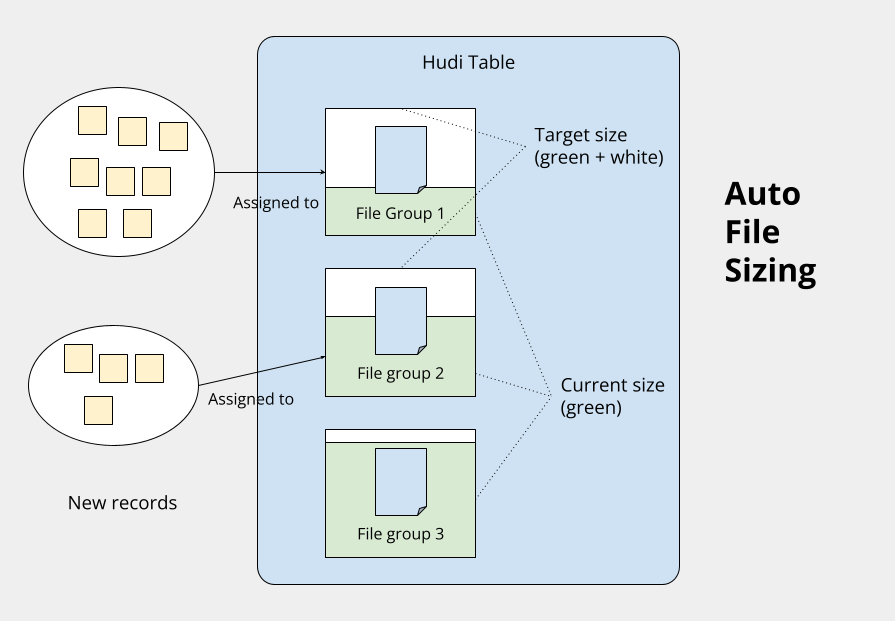
In addition to auto file sizing during writes, Hudi also provides the clustering table service that rewrites existing small files into larger ones, with sorting options on configured fields to improve data locality. Similar to async compaction, you can run clustering jobs asynchronously alongside ongoing writers without interfering with them. By maintaining desirable file sizes, the lakehouse table can deliver consistent and dependable read and write performance.
Hudi + Iceberg: the Best of Both Worlds via XTable
Hudi’s design advantages translate to real-world performance wins. As detailed in a blog by Walmart Global Tech, Hudi stood out as the winner over Iceberg for large-scale, real-world ingestion workloads. And this differentiation has now stood the test of time as well, given the benchmark is a few years old.
You might recognize Hudi's strengths for mutable writes but still face a conundrum: your Iceberg pipelines are struggling with the mutable workloads, yet your query engines prefer to work with Iceberg tables. With XTable, this dilemma is over. You can embrace true interoperability by using Hudi for its write efficiency and making the Hudi tables queryable as native Iceberg tables to maintain compatibility with your existing query engines.
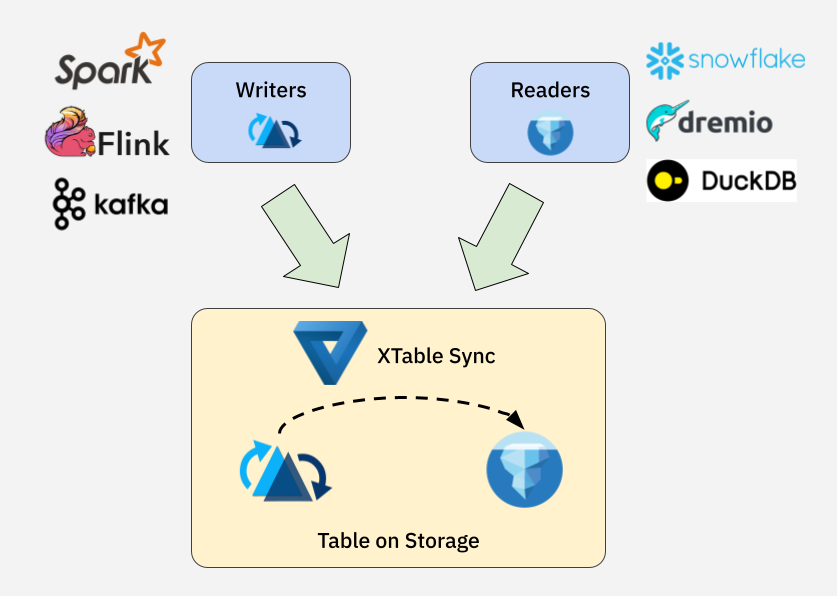
Hudi and Iceberg both define their own metadata component to track data files: Hudi has the .hoodie/ directory and Iceberg has metadata/. Since they can both share the same underlying data files (e.g., Apache Parquet™), a table can conform to any format as long as its metadata component is properly maintained. XTable makes this possible through table format sync: a metadata translation process that maintains co-existing metadata components, allowing a single table to function in multiple formats.
Assuming you have an existing Iceberg table my_table, you can use XTable to perform an initial, one-time sync from Iceberg to Hudi to prepare the table for subsequent Hudi writes. The XTable’s table format sync requires a config file like below:
# an example of XTable's table format sync config `iceberg_to_hudi.yaml`
sourceFormat: ICEBERG
targetFormats:
- HUDI
datasets:
-
tableBasePath: /path/to/my_table
tableName: my_tableThen, execute the table format sync as follows:
# an example of running XTable's table format sync
java -jar xtable-utilities_2.12-0.3.0-SNAPSHOT-bundled.jar --datasetConfig iceberg_to_hudi.yamlNote that you must first build XTable’s utilities bundled jar, following the instructions here.
Once the job succeeds, you can begin writing to the table with Hudi. Based on your business requirements, you can then set up a periodic job to sync from Hudi to Iceberg using the XTable’s utilities bundled jar at your desired cadence. The sync config file passed to --datasetConfig would look like this:
# an example of XTable's table format sync config `hudi_to_iceberg.yaml`
sourceFormat: HUDI
targetFormats:
- ICEBERG
datasets:
-
tableBasePath: /path/to/my_table
tableName: my_tableAlternatively, if you’re running a Hudi Streamer app for your Hudi writes, you can add the XTable Hudi extension jar to the application. With a few additional Hudi configs, the sync to Iceberg will be triggered automatically after each write, eliminating the need to set up a separate periodic job. Check out the docs for more details about using XTable with Hudi Streamer, and more blogs on XTable usage.
Summary
When handling fast-changing dimensions, Iceberg’s design can create performance bottlenecks. Hudi offers a powerful alternative, engineered from the ground up for mutable writes. Its robust designs—such as record-level indexing, MOR tables, async compaction, NBCC, and file size control—comprehensively address the challenges of workloads with fast-changing dimensions. By pairing Hudi’s write-side optimizations with XTable for interoperability, you no longer have to choose between write efficiency and query engine compatibility. Furthermore, with the pluggable table format feature in the upcoming Hudi 1.1 release, you can leverage Hudi’s powerful write capabilities to write to the Iceberg table format, maintaining compatibility with other Iceberg writers. You can finally get the best of both worlds. Open Data Formats FTW!

Read More:






Subscribe to the Blog
Be the first to read new posts