From the trenches: Managing Apache Iceberg metadata for near-real-time workloads

Introduction
Over the last few years, Apache Iceberg has gained popularity as an open table format that promises table metadata, schema evolution, time travel, flexibility across multiple query engines and employs optimistic concurrency control (OCC) to handle multiple writers. Its design, geared towards storing large, slow-moving tabular data, has been able to address challenges in managing large datasets and providing a “table abstraction” on top of data lake storage. However, as near-real-time streaming becomes the new normal, who wouldn’t also want data in their lakehouse as quickly and affordably as possible? How does Iceberg’s metadata management perform at moderate to high scale writes? Can it handle the demanding SLAs of near-real-time pipelines?
You may think of Onehouse as the Apache HudiTM company and wonder what the connection is. Onehouse is the “Open Lakehouse Company” – providing the most open and interoperable data lakehouse tables in the industry today, using Apache XTable (Incubating) to translate open table format metadata across reads/writes on the three major formats - Delta Lake, Iceberg and Hudi.
In this blog, we share our production experience in managing Iceberg metadata for large, frequently updated tables of our streaming/CDC ingestion product's users over the past 24 months. We share lessons we learnt and guide scaling pitfalls you may encounter for these Iceberg workloads.
Our Setup at Onehouse
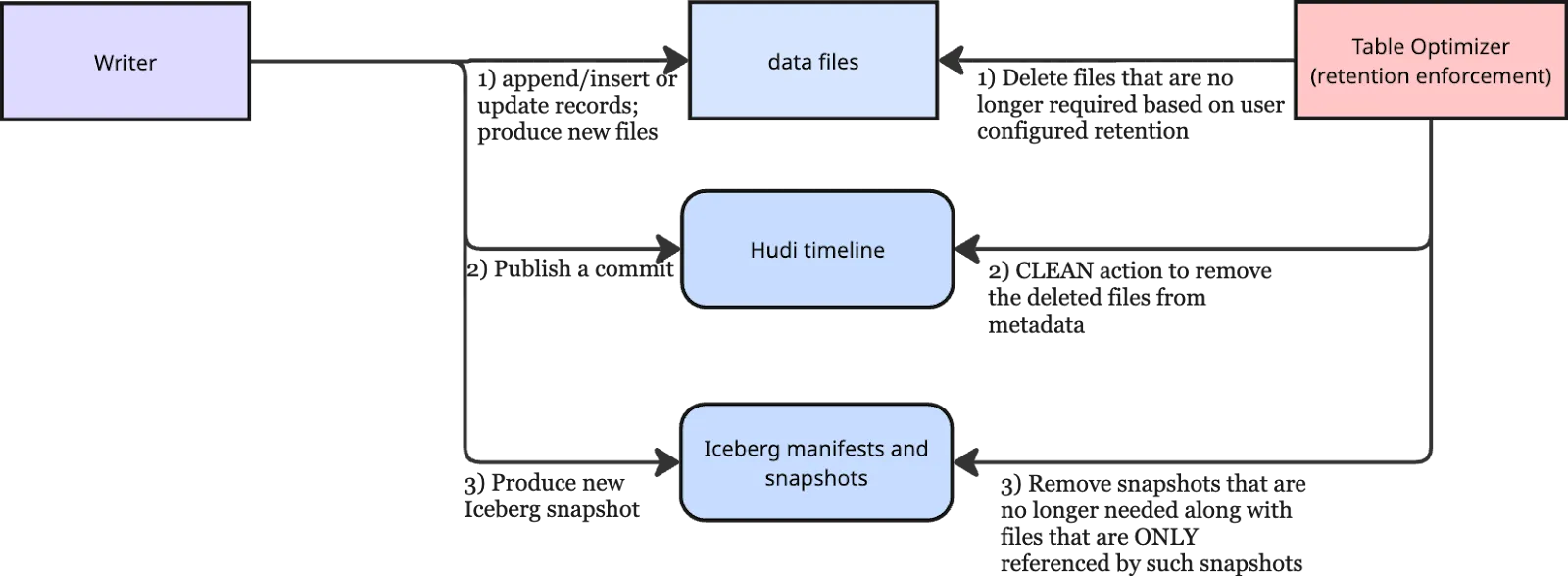
Onehouse runs and manages ingestion streams for large production tables (often tens of TBs and growing), ingesting append-only and mutable data in a streaming fashion every few minutes using Apache Hudi. With the help of the Multi-Catalog Sync feature, users can choose to generate iceberg metadata asynchronously, allowing them to query the data as an iceberg table on platforms like Snowflake and Dremio. This is powered by Apache XTable (Incubating), a rapidly growing open-source project that enables cross-table interoperability between open lakehouse formats through metadata translations.
For this functionality to work, every commit made in Hudi must be translated into Iceberg metadata and represented as an Iceberg snapshot in a timely manner. Similarly, users can configure a retention policy for their tables in Onehouse, and older versions or snapshots should be removed from both the physical table storage and the Hudi timeline, as well as the Iceberg metadata. Writes can fail midway and leave orphaned files in storage, which should be cleaned up promptly, as this can accumulate quickly in scenarios where the table is updated frequently.
Problem: Expiring Snapshots is too slow, impacting data freshness SLA
With each new commit in Iceberg, new manifest files are created. To manage the number of objects in the table’s base path, Iceberg performs a cleanup of expired snapshots using the expireSnapshots table maintenance operation. As the table size grew to TBs with thousands of partitions, hundreds of thousands of files and writers were committing frequently (on a 1- 5 minute scale), scaling problems started to creep up.
The XTable sync latencies shot up, sometimes up to 50% of the entire write duration, even though the write latencies were meeting SLAs, which we found to be pretty odd. The log below is a table with 7 days of retention configured.
24/06/11 13:57:57 INFO RemoveSnapshots: Expiring snapshots older than: 2024-06-05T14:57:57.059+00:00 (1717599477059)
24/06/11 14:10:36 INFO RemoveSnapshots : Committed snapshot changesThe actual ingestion (writing data using Hudi) completes within 1-2 minutes; however, the delay in generating iceberg metadata impacts the data freshness SLA when users query iceberg tables from Snowflake. Given the frequent commits and fast writes required by near-real-time or incremental workloads, having a table maintenance operation affecting your data freshness SLA was not acceptable.
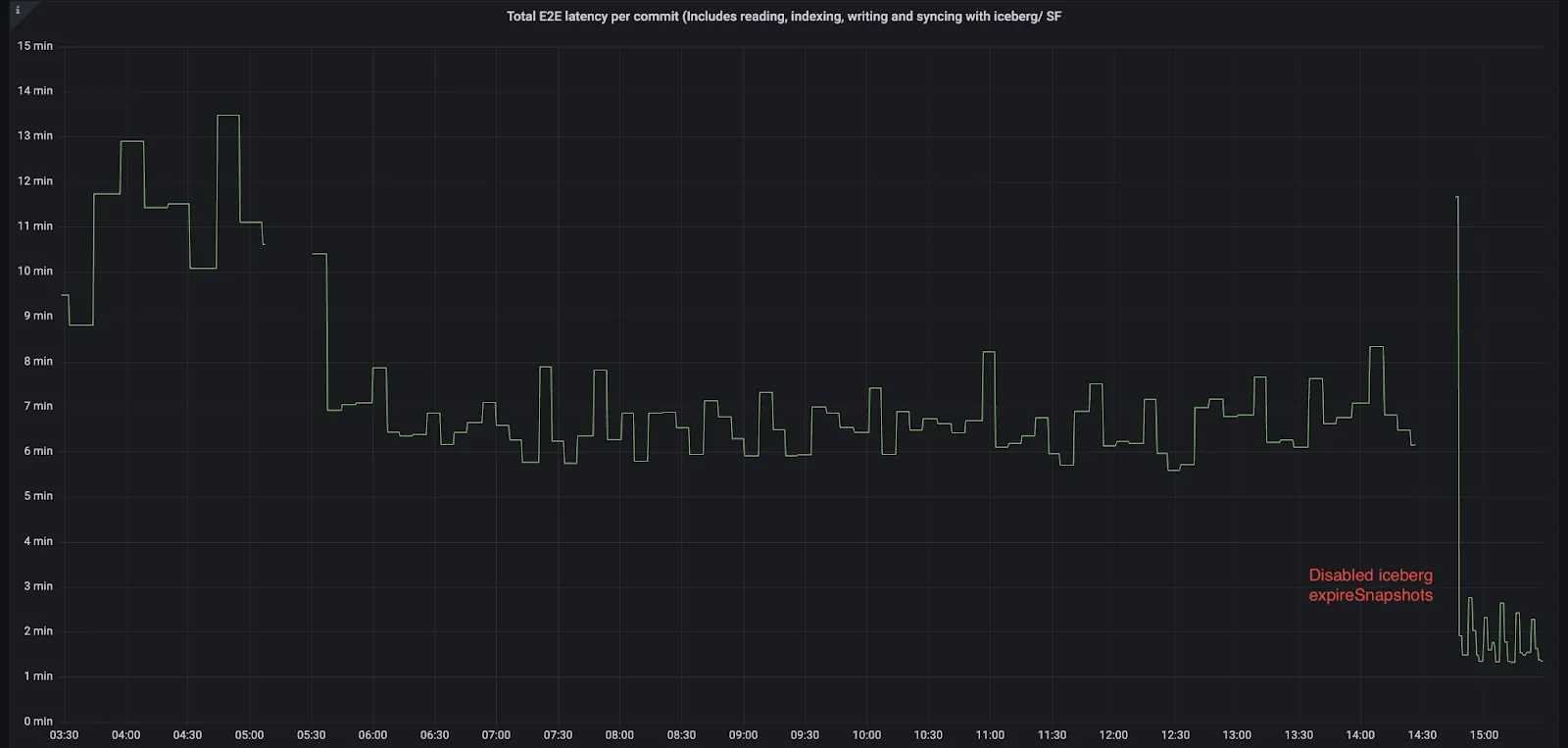
As shown in the screenshot above, we disabled expireSnapshots completely for a brief period to assess its contribution to overall latency. Disabling expireSnapshots improved the overall latency and brought it back within SLAs. However, we cannot do this, and it's not recommended for production workloads, as it would lead to future degradation (for example, each S3 list operation in storage will be throttled), resulting in increased cloud list usage and storage costs.
Understanding How It’s typically solved
We decided to dig in with flame graphs and all the JVM tooling gears. We found the bottleneck was primarily coming from the expireSnapshots code path. We began investigating how users typically run iceberg expireSnapshot and were surprised to find that many vendors supporting managed iceberg don’t recommend running it frequently, instead advising users to do it daily.
Tabular (acquired by Databricks)


Dremio (recommends running it regularly but couldn’t find any definition what regular meant)

Iceberg expireSnapshots in depth
To understand in a deeper context why vendors were recommending running expireSnapshots daily or relatively infrequently (implied), we looked at the iceberg expireSnapshots code to investigate. It performs the following on a high level, without delving into much detail. To explore further, here are the references for IncrementalFileCleanup and ReachableFileCleanup in the Iceberg codebase.
- Find a list of expired snapshots based on the configured retention policy, e.g., all snapshots with a timestamp less than T-X hours/days (X varies based on the retention configuration).
- Read manifests of expiredSnapshots and compute deletionCandidates.
- Read snapshotsAfterExpiration to remove manifests referenced in deletionCandidates and compute manifestsToDelete.
- Read manifestsToDelete, find data files and delete them as well. In the case of XTable, a safeDelete function is also passed to the iceberg transaction to ensure only expired metadata files are deleted.
- Delete any manifests that are no longer used by current snapshots.
- Delete the manifest lists.
Steps 3 and 4, which involve finding the data files to be deleted and then not deleting them (when using XTable), offer a helpful hint at a possible optimization. We will come back to this in a bit.
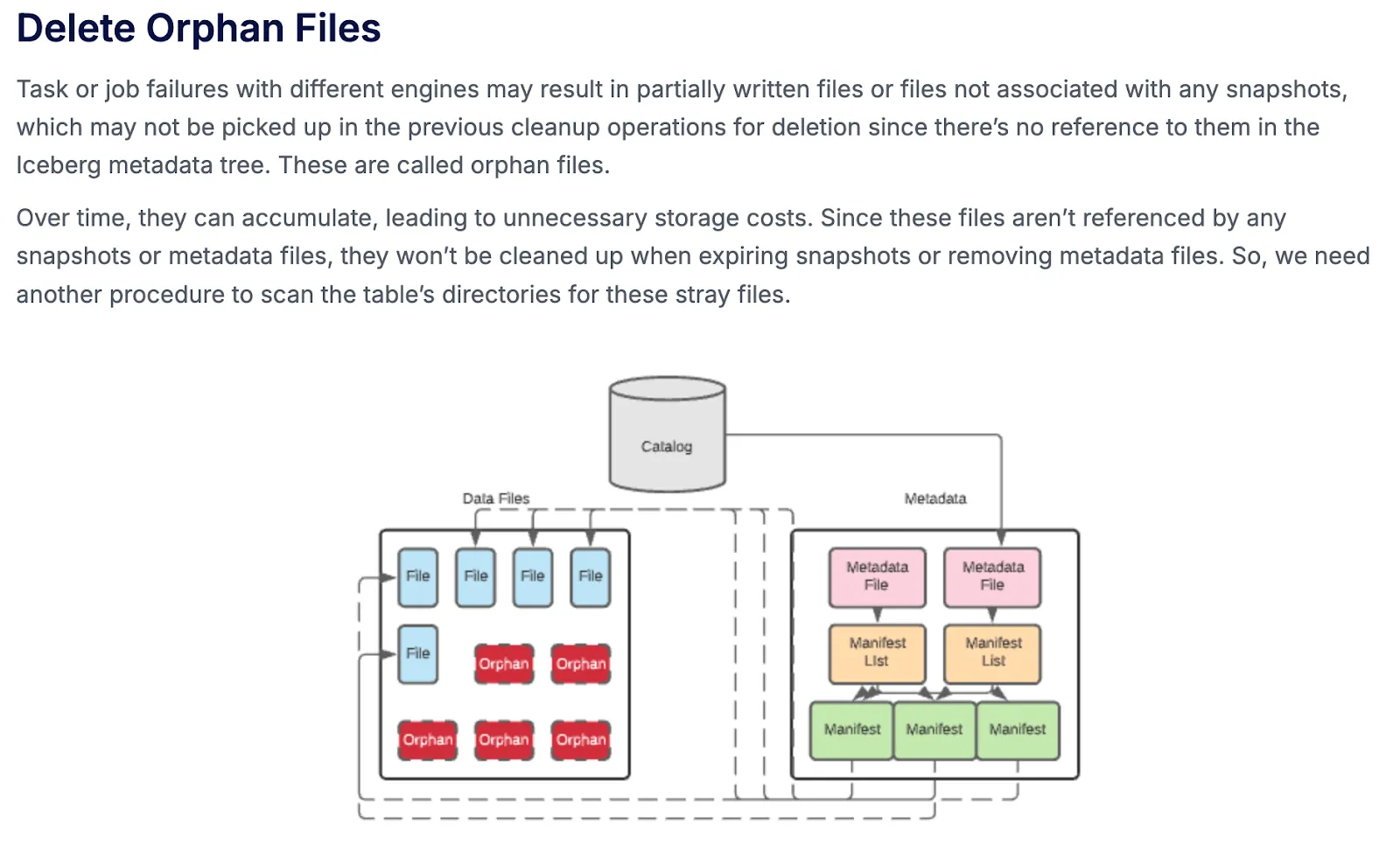
Problem: Deleting Orphan Files…is a full table listing?
Before that, we would like to share another storage reclamation challenge that users might face when writing to an iceberg table natively. While diving deep into the expireSnapshots algorithm, there was an obvious question: what happens to the files written by iceberg writers but not committed? Iceberg snapshots do not reference these files and can only be discovered through a full table listing and join operation with existing files referenced in the active snapshots. It’s a bit ironic that this key Iceberg maintenance operation bottlenecks on a key capability Iceberg was born to solve: scaling table metadata to avoid listing large tables.
The OSS Apache Iceberg project provides a procedure called deleteOrphanFiles, which by default cleans unreferenced files that are older than 3 days. However, deleting orphaned data files can be both time- and resource-intensive (and hence costly), as it involves scanning the entire table. Few managed iceberg vendors share the same concern and recommend running this process on a weekly basis.
Dremio (depicts the full table scan operation)
Tabular (acquired by Databricks) (recommends running it weekly/monthly)

Fivetran (deletes orphaned files every alternate Saturday)

S3Tables (unclear how often it’s triggered but still needs the expensive list/join)

To explain how expensive this could get in real life for a production table, imagine a lakehouse table where your Spark job writes 1 GB of data every 5 minutes. If we assume you’re creating 64 files per gigabyte (assuming ~16 MB per file), you end up generating about 18,432 files per day (64 files × 288 five-minute intervals). Factor in potential failures, retries, and additional overhead, and the total can easily exceed 20,000 files each day. Over the course of three years, assuming day-based partitioning, you could accumulate around 1,000 partitions. Every time we run deleteOrphanFiles, that’s potentially 20 million files to manage and list in cloud storage. This can be problematic as deleteOrphanFiles will become a table maintenance operation that’s “too big to succeed”.
- Each list request in all the major cloud storage services returns 1000 objects, and the subsequent requests need to pass a continuationToken. If, for any reason, the request times out or the operation fails beyond the retry limit, the entire process must restart from the beginning.
- The latency for cloud storage list operation ranges between 10- 100ms and throttles if the request is made for the same prefix (in our use case, the table’s base path). Even if we decide to introduce some parallelism by making requests per partition, the entire operation could still take hours, including exponential backoff due to throttling.
- If the deleteOrphanFiles process isn’t executed—whether due to monitoring lapses or missed scheduled jobs—the number of orphaned files will continue to grow. Over time, this unchecked accumulation can lead to excessive scanning overhead, which becomes unmanageable and severely impacts system performance and maintenance efforts.
How did we solve both?
As mentioned at the beginning of the blog, we employ Apache Hudi and Apache XTable (Incubating) for the ingestion writer, due to various other features, such as record-level indexing. It generates iceberg metadata with expireSnapshots as one of the actions triggered in IcebergConversionTarget XTable implementation. A safeDelete function is also passed to the iceberg transaction to ensure only metadata files are deleted, completely bypassing expensive deletionCandidates calculation.
To consistently meet data freshness SLAs, we addressed the problem using these complementary approaches:
- Skip scanning data files in iceberg: Implemented a custom FileCleanupStrategy in XTable that skips data files and deletes the expired snapshots and manifests.
- Hudi Cleaner: Hudi’s cleaning table service for deleting expired data files scales well and has proven effective for tables with 1000+ partitions and 10K+ files in each partition, committing changes every few minutes. This is possible because Hudi has a timeline of actions (an event log) where clean is recorded as an independent action, which unlocks the capability of performing incremental cleaning asynchronously.
- Hudi Write Markers: For handling orphaned data files, hudi uses a marker mechanism to track and clean up partial or failed write operations and avoids full table listings. Writers track any file created during a write for each writer, and the Hudi cleaner can also clean these leftover uncommitted files easily upon successful completion of a write or during eventual rollback of a failed write. This is possible because Hudi records both the start (state: REQUESTED) and end (state: COMPLETED) of write operations on the timeline.
- Asynchronous Table Services: If you ensure your core ingestion writer is not blocked at any point in time, you are halfway there. At Onehouse, we run all our table optimizations and maintenance services, including cleaning asynchronously and continuously, without the need for daily, weekly, or monthly expensive operations that block ingestion and impact data freshness.
OSS users can leverage some of these benefits in the upcoming pluggable table format support in Hudi 1.1.
Conclusion
We hope this blog has provided valuable insights into the challenges of managing Iceberg metadata, particularly for fast-changing tables and scenarios needing large amounts of retention. Ensuring data freshness and consistently meeting strict SLAs are critical objectives for data engineering teams across many organizations. At Onehouse, we're dedicated to realizing the vision of a Universal Data Lakehouse, empowering your organization to meet and exceed these data freshness SLAs with confidence.
For more information, please visit www.onehouse.ai.

Read More:






Subscribe to the Blog
Be the first to read new posts