Securing Your Data Lakehouse: Best Practices for Data Encryption, Access Control, and Compliance

Data lakehouses have essentially become the backbone of modern analytics. Combining the scalability of data lakes with the performance of data warehouses gives your teams faster, unified access to data. However, with this power comes a serious responsibility: keeping that data secure.
If you're managing a data lakehouse, you're likely storing a mix of structured and unstructured data, such as sensitive customer records, transaction logs, IoT feeds, and even proprietary models. However, the capacity to store both structured and unstructured data introduces potential security risks, including misconfigurations, unauthorized access, compliance issues, or even breaches. This could have huge consequences—both financially and reputationally. You might think everything's running smoothly, but without proper access controls or a way to quickly wipe records after a General Data Protection Regulation (GDPR) request, you're exposed. It's a wake-up call that even well-built systems need thoughtful safeguards.
This guide explains the importance of security for data lakehouses and explores practices to maximize security, focusing on encryption, access control, and compliance. You'll learn some practical strategies you can implement today and see how Onehouse tools simplify these efforts.
Why Security Matters for Data Lakehouses
Lakehouses are inherently flexible, but that flexibility can also be a vulnerability. When you centralize your data (both structured and unstructured) into a single repository, you're increasing the attack surface.
It's not just about external threats either. Insider threats, misconfigured permissions, and lack of visibility can be just as damaging. These risks are compounded by the need to meet evolving regulatory requirements, such as GDPR, Health Insurance Portability and Accountability Act (HIPAA), and California Consumer Privacy Act (CCPA), which demand strict controls around data handling, retention, and deletion.
If you're responsible for handling sensitive information, such as personally identifiable information (PII), financial data, or health records, the regulators won't care if it was just a misconfiguration in the development environment. Compliance violations because of poor data governance can result in multimillion-dollar fines or operational shutdowns. To address these challenges proactively, you need to start with a solid security foundation.
Best Practices for Data Encryption
In this section, you'll learn how to implement strong encryption strategies, leverage secure key management systems, and align with industry standards to ensure your lakehouse stays protected.
Encrypt Data at Rest and Data in Transit
Start with the basics: encryption. Data encryption protects data confidentiality by blocking unauthorized access. Encryption blocks unauthorized access by converting data into a coded format that can be read only with the correct decryption key. Every byte of your data should be encrypted at rest and while in transit:
- Data at rest: Use AES-256, the gold standard for data encryption.
- Data in transit: Enable TLS 1.3 or higher for all data movement—between services, ingestion pipelines, and even API calls.
For example, if you're working in a team managing a lakehouse in Amazon Web Services (AWS), you can enforce server-side encryption (encryption for data at rest) on every Amazon Simple Storage Service (Amazon S3) bucket, coupled with client-side encryption for extra-sensitive datasets. That's your safety net if access control ever fails.
Use Key Management Systems
Never hard-code or manually rotate keys. This is important because hard-coding or manually rotating keys increases the risk of human error and exposure. Integrate your lakehouse with a cloud-native key management system, such as the following:
- AWS Key Management Service (AWS KMS) makes it easy to create and control the keys used for encryption across AWS services, including Amazon S3, AWS Glue, and Amazon Redshift. AWS supports encryption of data at rest and in transit. You can integrate AWS KMS with your lakehouse to automatically encrypt data at rest.
- Azure Key Vault helps you store and control access to secrets, encryption keys, and certificates. When integrated with Azure Data Lake or Azure Synapse Analytics, it ensures your data lakehouse is using properly rotated keys and that key access is audited and logged for compliance.
- Google Cloud Key Management Service (Cloud KMS) offers centralized key management for resources on Google Cloud. You can configure automatic key rotation and use identity and access management (IAM) roles to define who can use or manage keys.
Integrating with a cloud-native KMS ensures secure, automated key management with auditability and policy enforcement. With Apache Hudi™, you can configure encrypted storage layers while still benefiting from fast reads and writes. Apache Hudi, Apache IcebergTM, and Delta Lake all support encrypted file formats, such as Apache Parquet™ and Apache ORC™, but Hudi's incremental processing and record-level indexing architecture provides superior performance when working with encrypted datasets.
Access Control
After implementing encryption, the next essential step in securing your data lakehouse is enforcing robust access control.
Use role-based access control (RBAC) to define clear roles—analyst, data engineer, auditor, and so on. Then, layer in attribute-based access control (ABAC) for more nuanced rules. For example, in AWS Lake Formation, you can use tag-based access control, which is a form of ABAC, to ensure that only users from the finance department can access certain tables. In Apache Ranger, a similar policy could be created by assigning access based on user attributes, such as region, project, or team.
You can also restrict access to cost center data so that only finance analysts can view it during business hours and limit access to raw PII exclusively to users who belong to the governance group.
To ensure security and compliance at scale, you'll need a thoughtful strategy for managing who can access what, when, and how. In that context, here are some best practices for access control and user authentication:
- Use IAM integrations with federated identity (Okta, Microsoft Entra ID, AWS IAM): Integrating your lakehouse with federated identity providers enables you to manage user access centrally and securely. It enables single sign-on (SSO), enforces multifactor authentication (MFA), and ensures that only authorized users from trusted domains can access your data.
- Leverage AWS Lake Formation or Apache Ranger to define column- and row-level access policies: Tools such as AWS Lake Formation and Apache Ranger let you implement fine-grained access control down to the column or row level. This means you can tailor access based on user roles or data sensitivity; for example, masking salary columns or filtering out regional data not relevant to a user's role.
- Create read-only audit roles for compliance teams: Giving compliance teams dedicated, read-only roles ensures they can monitor and review data access and usage without risking accidental changes or data exposure. These roles help maintain transparency and support audit readiness while keeping your data environment secure.
In multi-tenant lakehouses, especially for enterprise analytics, scaling fine-grained access control, audit logging, and metadata isolation is key. Use AWS Lake Formation with resource tags to enforce fine-grained access across tenants without duplicating infrastructure. Encrypt data at rest and in transit with tenant-specific keys via AWS KMS and log all queries with tools such as AWS CloudTrail for compliance. Though setup takes planning, this layered approach ensures security, privacy, and audit readiness at scale.
Compliance with Data Regulations
The next key step in securing your data lakehouse is making sure it complies with relevant data regulations. It's important that you understand the compliance standards that apply to your organization. Depending on your industry and where your users or customers are located, your organization is likely subject to one or more of the following regulatory standards:
- GDPR (EU): GDPR mandates strict rules on data privacy, user consent, and the right to be forgotten for EU residents.
- CCPA (California): CCPA gives California residents the right to know what personal data is collected and to request its deletion.
- HIPAA (US healthcare): HIPAA governs how healthcare providers handle and protect personal health information (PHI).
- Schrems II is a landmark EU court ruling that restricts the transfer of personal data from the EU to countries without equivalent privacy protections.
These regulations share common requirements: the ability to quickly and precisely update or delete records in large datasets, along with comprehensive auditing and monitoring. Let's first compare table formats for data deletion and record-level operations, and then examine auditing and monitoring capabilities for compliance.
Choosing a Lakehouse Solution that Enables Easy Data Deletion
It's important to choose a lakehouse storage solution that enables efficient and reliable data deletion. Traditional lakehouse setups built on immutable file formats like plain S3 and Parquet force organizations to scan or rewrite entire datasets to modify individual records, making compliance both time-consuming and costly. This is where modern table formats shine by providing surgical precision for record-level operations.
For instance, the GDPR's right to be forgotten means you need to delete user data fast and at a granular level. When completing GDPR "Right to be Forgotten" requests, Hudi’s record-level indexing makes it possible to quickly locate and update or delete specific records by key, without scanning the entire dataset. Its timeline design (what changed and when) and time travel capabilities (ability to query historical states) complement indexing by preserving a history of all changes for efficient audit trails and compliance reporting.
Apache Iceberg and Delta Lake both support deletes but handle them differently. Iceberg uses delete files (position or equality) to mark rows as removed, merging them later during compaction for efficiency. Delta Lake uses tombstones to track removed files and rewrites only those affected; with deletion vectors, it can now mark rows as deleted and defer full rewrites until optimization.
Apache Hudi takes a different approach. Its record-key-based architecture was designed from the ground up for upserts and fine-grained mutations. That makes Hudi especially strong in environments where data changes frequently — think streaming ingestion or CDC pipelines — and where efficient deletes and clear audit trails really matter.
Enhancing Observability and Compliance with Auditing and Monitoring Tools
Most compliance regulations mandate the use of auditing and monitoring tools to log and track data access and ensure accountability. The following tools can enhance observability and compliance:
- Onehouse LakeView for real-time data observability: LakeView provides real-time insights into your data's health and activity. It enables you to track data quality and monitor processing jobs.
- AWS CloudTrail, Datadog, or OpenTelemetry for logging: Logging is vital for both security and compliance. AWS CloudTrail tracks user activity and API usage, while Datadog and OpenTelemetry provide application-level monitoring and logging.
- Apache Atlas or Amundsen for data cataloging and lineage: Both Apache Atlas and Amundsen help organize and manage your data by cataloging metadata and providing data lineage. They also support compliance by making it easier to demonstrate where data is coming from, how it's processed, and who has accessed it.
For example, if a compliance team needs to verify how a user's personal information was transformed from raw ingestion to an analytics dashboard, lineage tools can visually map out every step—from the original source in your Apache Hudi table, through transformation jobs in Apache Spark™, all the way to the final BI layer. This makes it easier to respond to regulatory requests and internal reviews.
Regulatory reports are critical for demonstrating compliance with data protection laws and industry standards. Generating these reports often requires accurate and consistent metadata and data across catalogs. These data catalogs serve as the source of truth for what data exists, where it lives, how it is structured, and who has accessed it.
Organizations often use multiple catalogs to cover different needs, such as discoverability, lineage, access control, compliance, documentation, and data quality management. In practice, keeping multiple catalogs in sync is a common challenge; any table property updates, partition list changes, or schema changes in the underlying tables need to be consistently reflected across all catalogs. For example, if schema evolution is not propagated everywhere, it can lead to query failures, inconsistent views, or even compliance gaps.
You can compare different data catalog options to understand which features best fit your compliance requirements. Onehouse's multi-catalog synchronization helps you propagate schema changes automatically across all connected catalogs when schema evolution occurs. This eliminates the need to write custom jobs just to keep metadata aligned after schema changes.
Data Sovereignty: Keeping Data Local
Data sovereignty refers to the concept that data is subject to the laws and regulations of the country or region in which it is stored or processed. This means that organizations must ensure their data stays within specific geographical or operational boundaries to comply with local data protection laws, such as GDPR in the EU or HIPAA in the US.
In the context of a data lakehouse, managing data sovereignty is crucial to ensure that sensitive information remains within legally defined territories and that the processing of such data follows the appropriate legal frameworks. If you're using a traditional software-as-a-service (SaaS) data platform, your data might be moved to external environments for processing, which violates many sovereignty requirements.
To address these challenges, it's important to choose a platform that not only respects data residency requirements but also gives you full control over where and how your data is processed. For example, Onehouse takes a unique approach—privacy-first data architecture. With Onehouse, all computing and data processing occur within your virtual private cloud (VPC), which means the following:
- You retain full control over data location and movement.
- There's no risk of shadow copies sitting in a vendor's cloud.
- You're meeting sovereignty and residency laws by design.
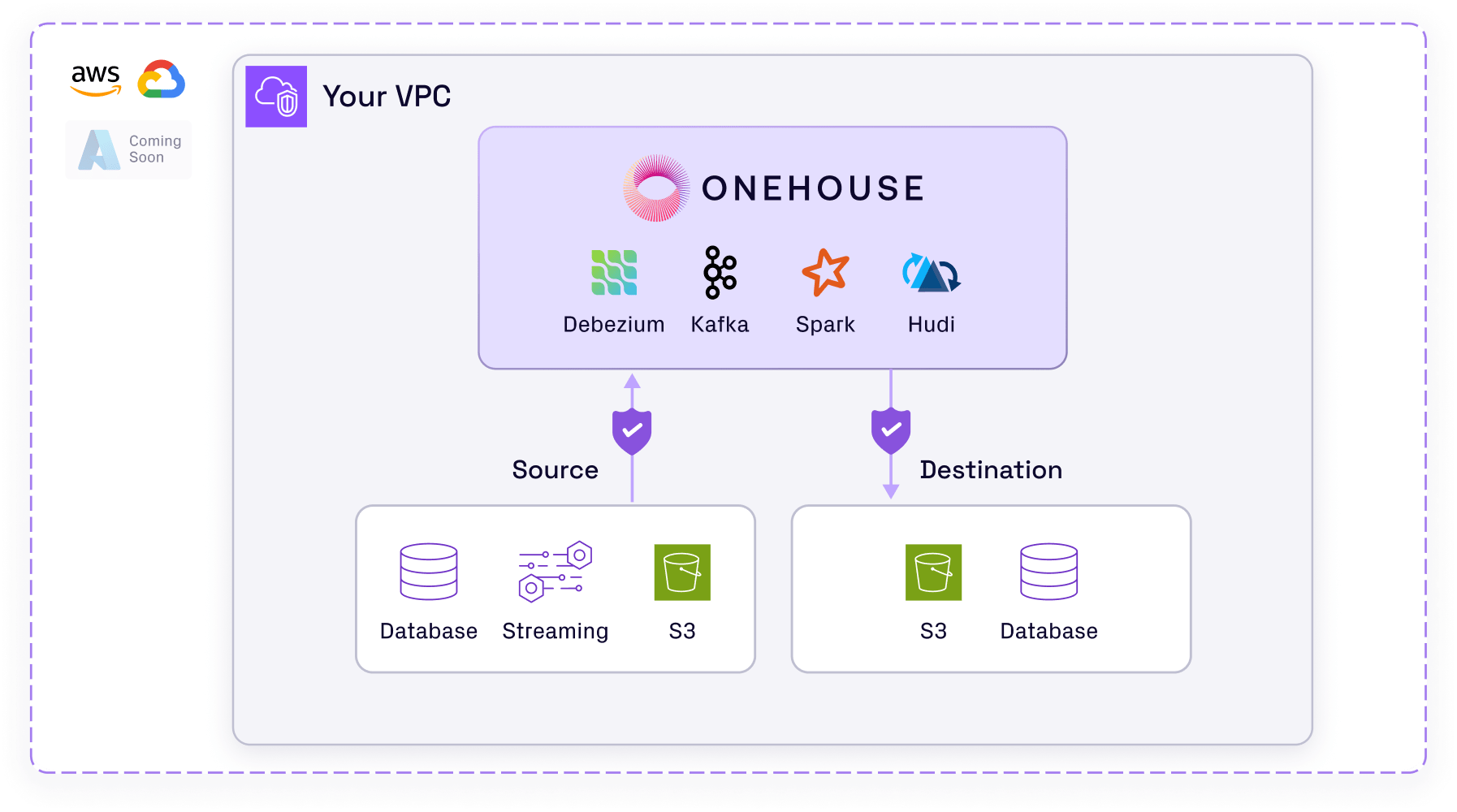
Securing a Lakehouse End-to-End
To see how these security principles come together in practice, let's walk through a practical implementation for securing a lakehouse end-to-end that you can model for your own environment:
- Encryption: All datasets are securely stored in cloud storage buckets with AWS KMS-encrypted keys. This ensures that the data is protected at rest and TLS encryption is enforced for all data in transit.
- Access control: RBAC policies are configured within your data governance platform. These policies are applied to catalog tables and specific columns, with tag-based controls ensuring that only authorized users have access to sensitive data. This setup helps manage granular access at the table and column level.
- Compliance: For compliance with privacy regulations such as GDPR or CCPA, organizations must be able to perform precise, record-level deletes and updates to honor user rights, such as their "Right to be Forgotten." Without this capability, teams often resort to building complex, error-prone pipelines that rewrite entire datasets just to make small changes. Modern table formats simplify this by supporting familiar operations like insert, update, upsert, and delete, and handle the underlying tracking and file management. These operations enable secure, granular data changes without full rewrites.
- Data sovereignty: Deploying the lakehouse entirely within a private cloud environment ensures that data processing and storage comply with data sovereignty requirements and prevent data from being moved to jurisdictions that could cause compliance issues.
The outcome is a highly secure, scalable lakehouse environment that satisfies both security and compliance requirements. It gives peace of mind to both engineering and legal teams, knowing that data is not only protected but also managed in compliance with global regulations.
Conclusion
Securing your data lakehouse is not a one-time task; it’s an ongoing commitment. With the right architecture, tools, and partners, you can ensure your data stays protected, compliant, and performant.
Onehouse makes that easy. Built by the creators of Apache Hudi, Onehouse delivers a fully managed, open data lakehouse platform that runs entirely within your cloud for full data control. Its suite of tools simplifies both security and operations, from the free LakeView for real-time observability, to Table Optimizer for hands-off tuning, to OneSync to sync table metadata to any catalog, to Quanton, the ETL-aware Spark engine that delivers 2-3x better price-performance. With the Cost Analyzer for Apache Spark, you can identify inefficiencies and reclaim wasted spend across your existing Spark pipelines before bringing them into Onehouse for automated optimization.
Whether you are managing Hudi, Iceberg, or Delta tables, Onehouse unifies them in a single, secure environment that is encrypted by default, compliant by design, and optimized for performance. Protect your data, cut costs, and future-proof your lakehouse with Onehouse.
Start your free test drive today and see how Onehouse helps you build a faster, safer, and more efficient data lakehouse


Read More:






Subscribe to the Blog
Be the first to read new posts