Onehouse 2025 Year in Review
As we get started in 2026, I find myself reflecting on features we shipped, the engineering velocity we cultivated, the customers we unlocked, the partners we developed, and on the deeper shift this year represented for our company at Onehouse. At the beginning of the year, the direction of the data world felt settled. Open table formats had won. The lakehouse emerged as the default architecture the industry agreed on. Decoupled storage and compute were no longer fringe ideas. On paper, the future looked obvious.
In practice, something wasn’t working. Teams believed in open data, yet struggled to run it reliably. Costs exploded without explanation. Performance varied unpredictably. Metadata systems buckled under real workloads. Ingestion decisions made months earlier quietly dictated today’s failures. The promise of openness was real, but the operational burden was still falling squarely on engineers. Open table formats are powerful, but they come with tradeoffs. They require intentional design choices around layout, ingestion, metadata and they behave differently for different workloads. We wrote about the hard parts throughout the year. About clustering and when it helps and when it hurts. About deduplication and the cost of getting it wrong. About metadata growth that sneaks up on teams. About why some defaults fail spectacularly once data becomes continuous instead of batchy.
We made a decision early in 2025 that shaped everything that followed: Onehouse would stop being a platform that merely enables open data, and become a system that takes responsibility for making it work.
From architectural consensus to operational success
Instead of asking what features the market expected, we asked what engineers were actually fighting in production. We spent time where systems break at the seams between storage, compute, metadata, and workload behavior. We looked at how costs balloon over time, not how they look in benchmarks. We examined why “best practices” collapse under continuous ingestion, skewed data, and multi-engine access.
What became clear is that an open data format alone is not enough. If data is going to live outside proprietary silos, then the platform running it must simultaneously absorb complexity and ensure that data remains portable. That belief led us to invest deeply in foundations, not quick wins. As 2025 opened in January we announced our first step by launching the Onehouse Compute Runtime (OCR). OCR is now the fabric for how we run compute across all of our managed services. It is specialized for real world lakehouse workloads, under variable load, across formats and engines, resolving all the messiness this implies. OCR reimagined the core building blocks of the lakehouse with a serverless compute manager inside the customer vpc, offering multi-cluster management, adaptive workload optimization, and a new high-performance lakehouse I/O.
The most meaningful progress of 2025 wasn’t just a single launch, it was the way our improvements began to create compounding leverage for each other. Execution became faster as we refined our engineering practices and as each foundational block provided leverage and force-multiplied. Cost efficiency stopped being a tuning exercise and became a property of the system. At that point, Onehouse stopped being just a lakehouse platform. It started to feel like foundational data infrastructure, teams could actually rely on.
Openness, without illusions
Open Engines was born from a simple realization: openness at the data layer only matters if compute remains equally open and adaptable. As workloads diversified beyond Apache Spark™, teams were forced into brittle compromises—either contorting workloads to fit a single engine or fragmenting their platforms entirely. Open Engines lets Onehouse absorb that complexity, giving teams the freedom to run the right engine for each workload without sacrificing operational coherence.
To this end in April we launched Open Engines, making it possible to seamlessly deploy and match your workload to the compute engine of your choice. Onehouse customers now have 1-click compute infrastructure to effortlessly run open source Trino, Flink, or Ray side-by-side their Spark pipelines.
The next generation platform for Apache Spark™
One of the year’s biggest leaps came soon after in May when we launched SQL + Spark Jobs powered-by our new Quanton execution engine.
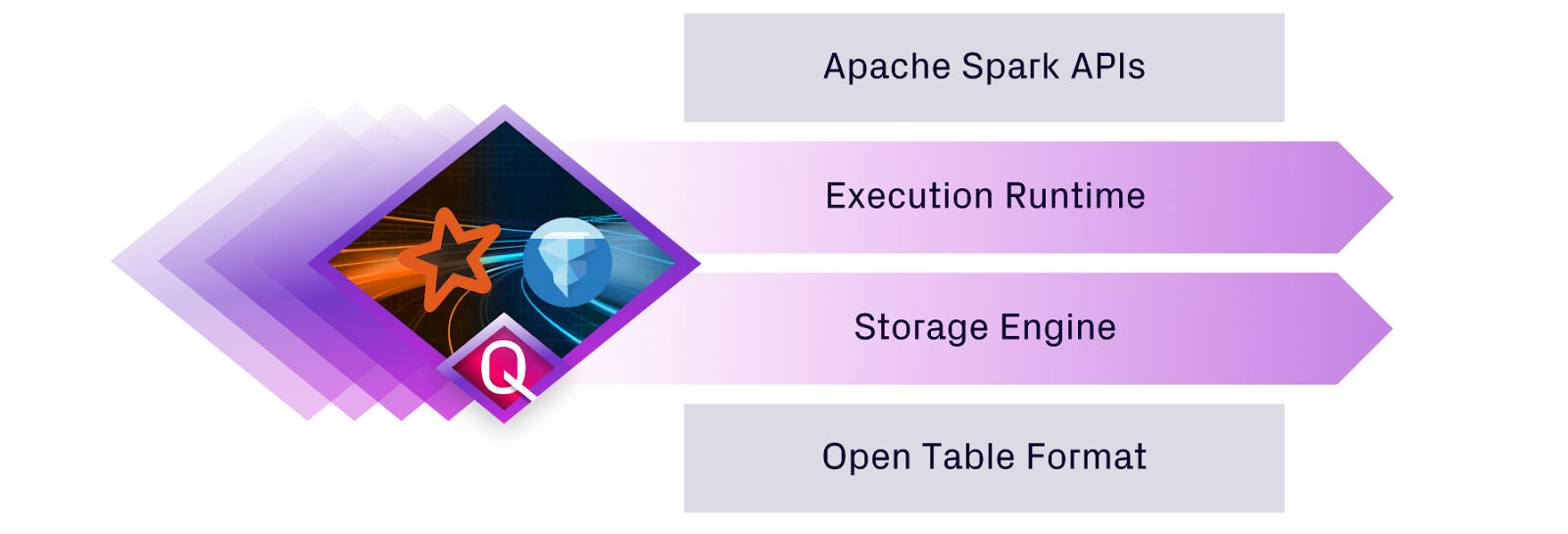
Working with our early design partners we crafted a next generation Spark platform that is competitive on performance, price, and experience with AWS EMR, GCP Dataproc, and also Databricks. We published verbose benchmarks across TPC-DS, TPCx-BB, TPC-DI, LakeLoader showing 2-5x cost performance advantages.
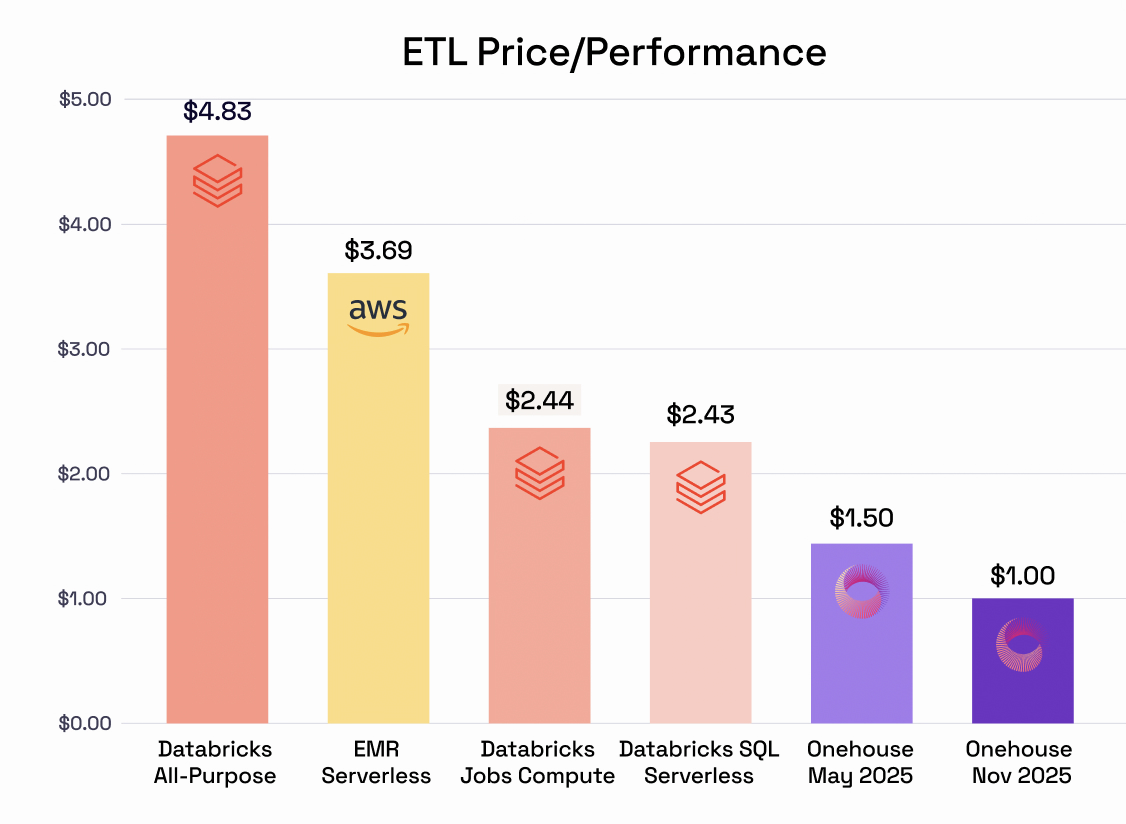
We also published a detailed study of how benchmarking tools and methodologies don’t accurately characterize ETL workloads. In order to address that further, we also published the Cost Analyzer for Apache Spark tool which anyone can point at an existing Spark job. With a simple `pip install spark-analyzer` you get a detailed report explaining exactly how much Quanton is able to save your specific job.
Ingest at the speed of data
The summer conference cycle revealed a new agreed on naming convention for ingestion products like Databricks LakeFlow, Snowflake OpenFlow, and Confluent TableFlow. We joined the party by relaunching our robust and industry leading ingestion platform as OneFlow.
Customers that try OneFlow are blown away by the performance of the platform that can rapidly ingest data as Apache Hudi™, Apache Iceberg™, and Delta Lake tables.
Chill out with the Iceberg
As the year started to cool off, Onehouse wasn’t anywhere near ready for a break and we continued our momentum in November by launching native Apache Iceberg accelerations for Quanton. This comes at the heels of Apache Hudi, having another stellar year of few releases and community momentum. When it comes to open formats, Onehouse firmly believes in more the merrier.

With support for Iceberg on Quanton, Onehouse now became the most cost-effective place to run your Iceberg Spark/SQL pipelines, natively or using Apache XTable (Incubating) as a bridge.
Sparking up your notebooks
In December we finished the year strong by announcing Onehouse Notebooks for interactive PySpark. Because of the foundation we set early in the year, Notebooks run on autoscaling Onehouse clusters deployed within your virtual private cloud, enabling you to control costs and mix-and-match instance types, without the worry of managing your own infrastructure. Since notebooks are integrated with the full Onehouse platform, tables you create are automatically optimized and can be synced to any catalog with OneSync.
The team behind the momentum

What ultimately defines Onehouse isn’t the platform, it’s the people building it. Our team is made up of engineers and builders who are opinionated about systems, who move fast, and take accountability for problems end to end. We value clarity over theatrics, and rigor over shortcuts. Most of the progress you saw this year came from small groups of people taking full ownership of hard problems - metadata at scale, cost predictability, execution efficiency and refusing to hand-wave them away. We debate openly, measure obsessively, and ship when the system is genuinely better, not just different. That DNA, intellectual honesty, speed with accountability, and a willingness to publish what we learn, is what allows Onehouse to move quickly without breaking trust. It’s also what attracts engineers who don’t just want to work on infrastructure, but want to build it the right way.
At Onehouse, we’re only comfortable operating at one speed: fast. The momentum we built in 2025 isn’t an accident or temporary, it’s the baseline for what’s coming next. I really look forward to continuing to push the boundaries of open data platforms in 2026 as well! Thanks for all your support and encouragement!
If you’re passionate about building the future of the data lakehouse and want to do it alongside engineers who move with urgency and purpose, we’re hiring, JOIN THE HOUSE! And if your organization is looking to lower costs, improve performance, or unlock true interoperability across your data platform, reach out to gtm@onehouse.ai to start a free trial.

Read More:





Subscribe to the Blog
Be the first to read new posts