Cut AWS EMR Spark Costs by 60%+
No code changes. Faster ETL pipelines, fewer clusters, and zero ops.
Why use Onehouse?
Drop-in compatibility with your existing EMR Spark jobs. Guaranteed cost savings, faster ETL, and hands-free table optimization, while staying open and interoperable in AWS.

Guaranteed Savings
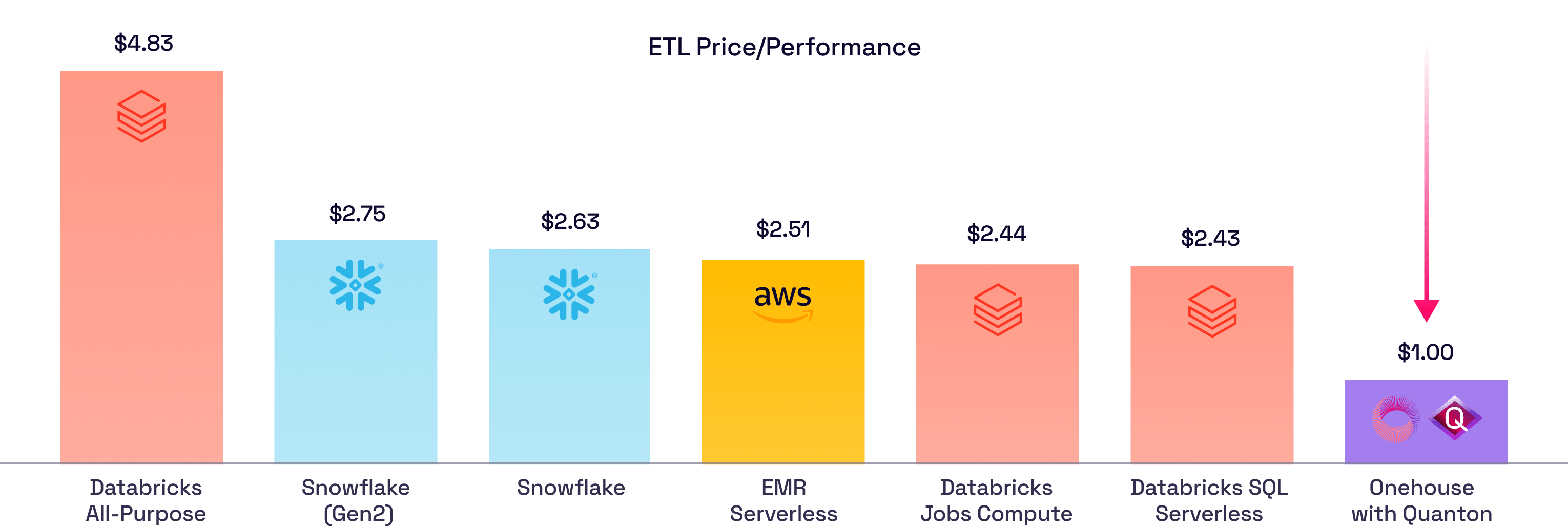
Point EMR Spark jobs to Onehouse Compute Runtime (OCR) with Quanton for 70%+ lower Spark infra cost and optimized performance.

No Code Changes
Keep your existing Spark jobs and configurations. No rewrites, migrations, or refactoring needed.

Faster ETL
Quanton’s ETL-aware execution and autoscaling deliver 3–4x better price/performance and instant scaling for spikes.

Hands-Free Table Optimization
Automatic compaction, clustering, and cleaning for Apache Iceberg™, Delta, and Apache Hudi™, yielding 2–10x faster queries.

Open & Interoperable
Stay in AWS with Glue sync and multi-format support. Query from EMR, Trino/Presto, Snowflake, and more.

Enterprise-Ready Deployment
Run in your VPC with SOC2/PCI compliance. Keep your data secure, open, and under your control.
Find Your Own EMR Spark Savings Opportunities
- Install in minutes (pip install spark-analyzer)
- Point it at your EMR Spark History Server
- Get a detailed Excel report on bottlenecks, idle compute, and savings opportunities

How It Works

Proof in Action
Ready to Cut Your EMR Costs by 60%+?
See exactly how much you could save with Onehouse on EMR Spark.