The Onehouse Platform in Your Cloud
Build a fast, cost-effective data lakehouse for analytics and AI with the Onehouse platform. Everything runs in your VPC, on any cloud.
Data pipelines up to 4x faster
and cheaper
Run SQL, Spark jobs, and PySpark Notebooks on the Quanton engine, backed by efficient, autoscaling compute.
Explore Quanton

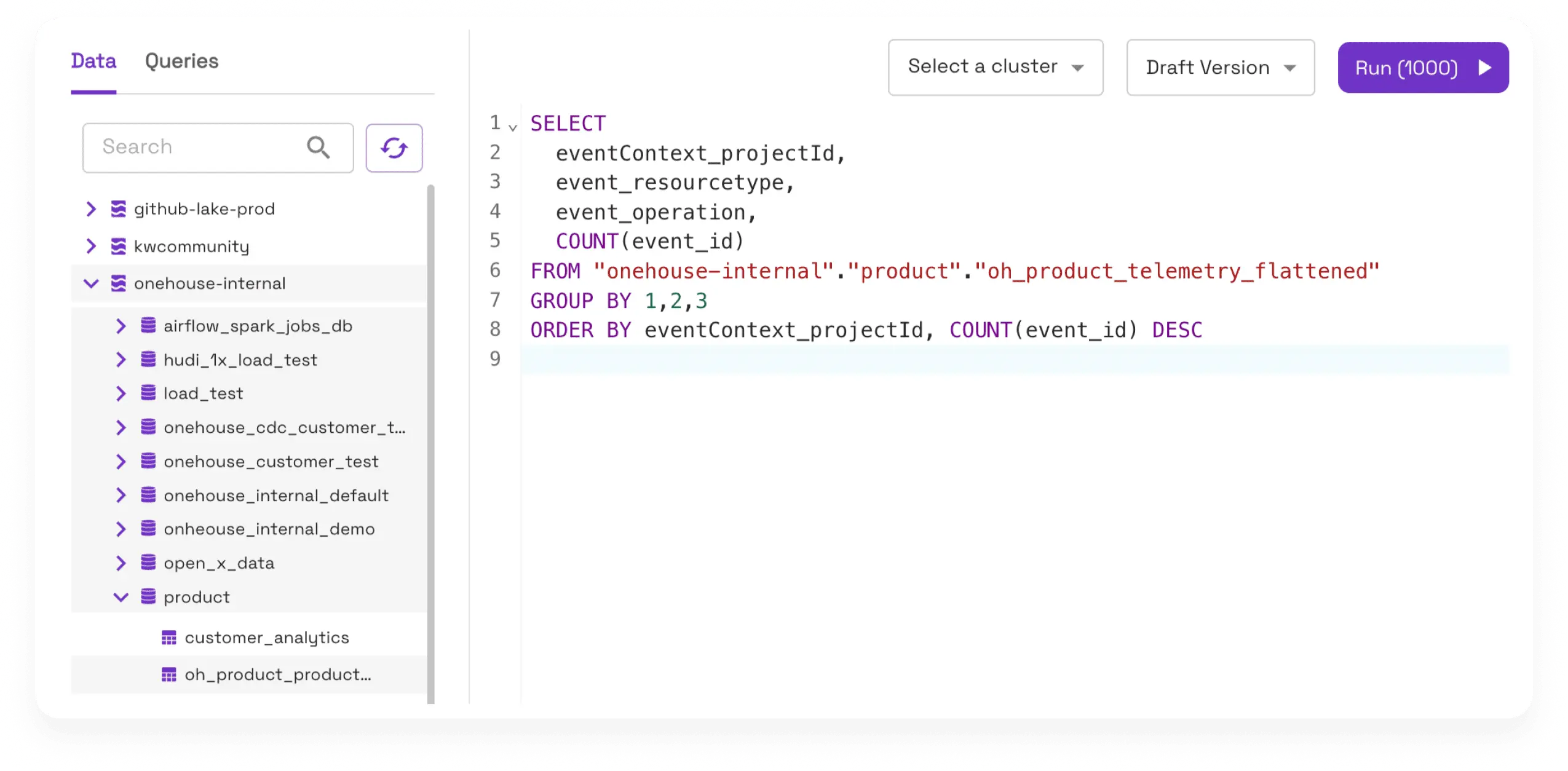
The fastest queries on the lake
The world’s first lakehouse serving layer with database capabilities like indexing and caching. Built for machines, not just humans. Handling high-QPS, low-latency lookups from AI agents as well as heavy analytics.
Explore LakeBase
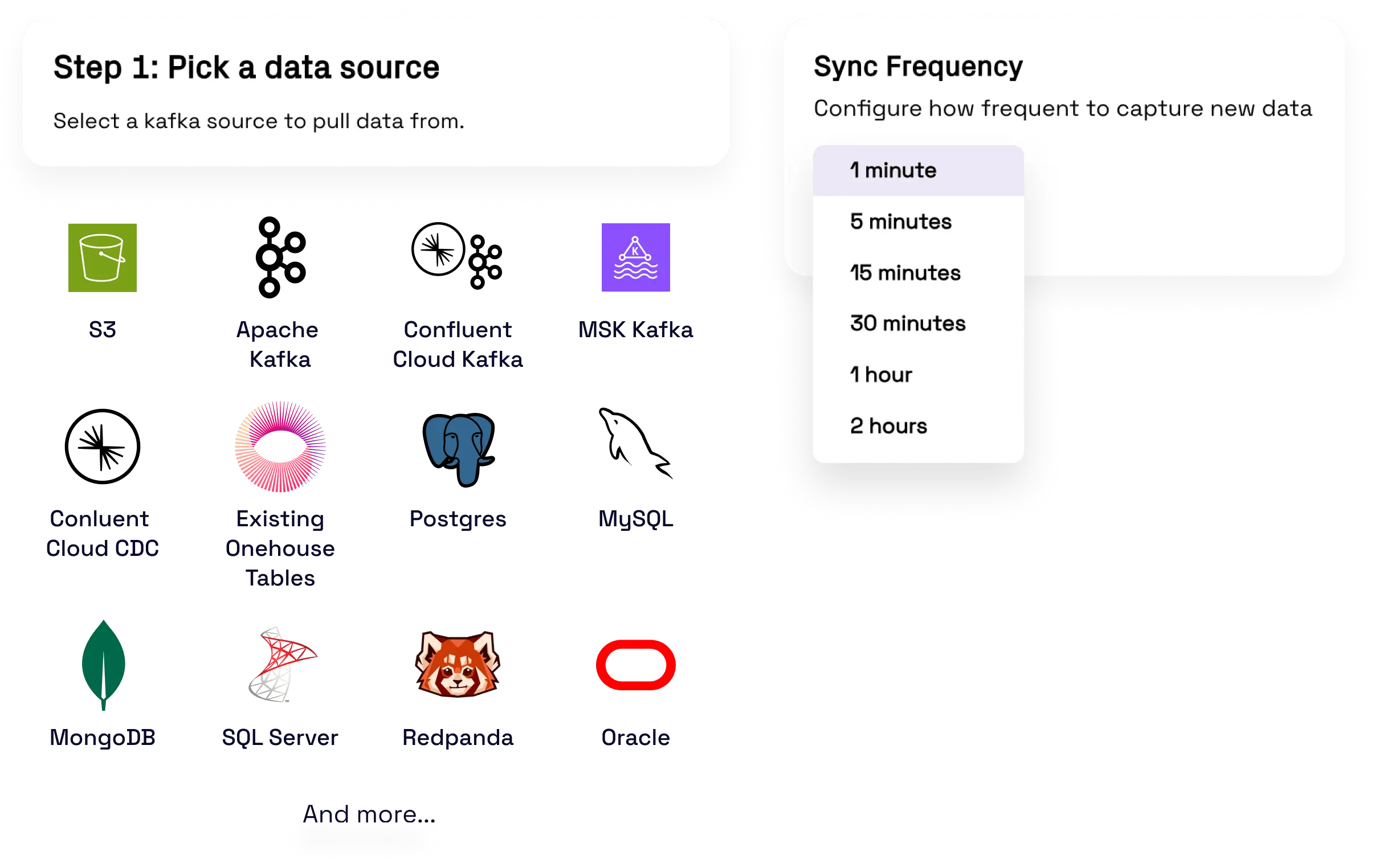
Rapid, reliable data ingestion at lower cost
The fastest ingestion of all your data into Apache Hudi™, Apache Iceberg™, and Delta Lake tables in your cloud storage. OneFlow ingestion delivers industry leading performance at a fraction of the cost thanks to incremental processing.
Explore OneFlow
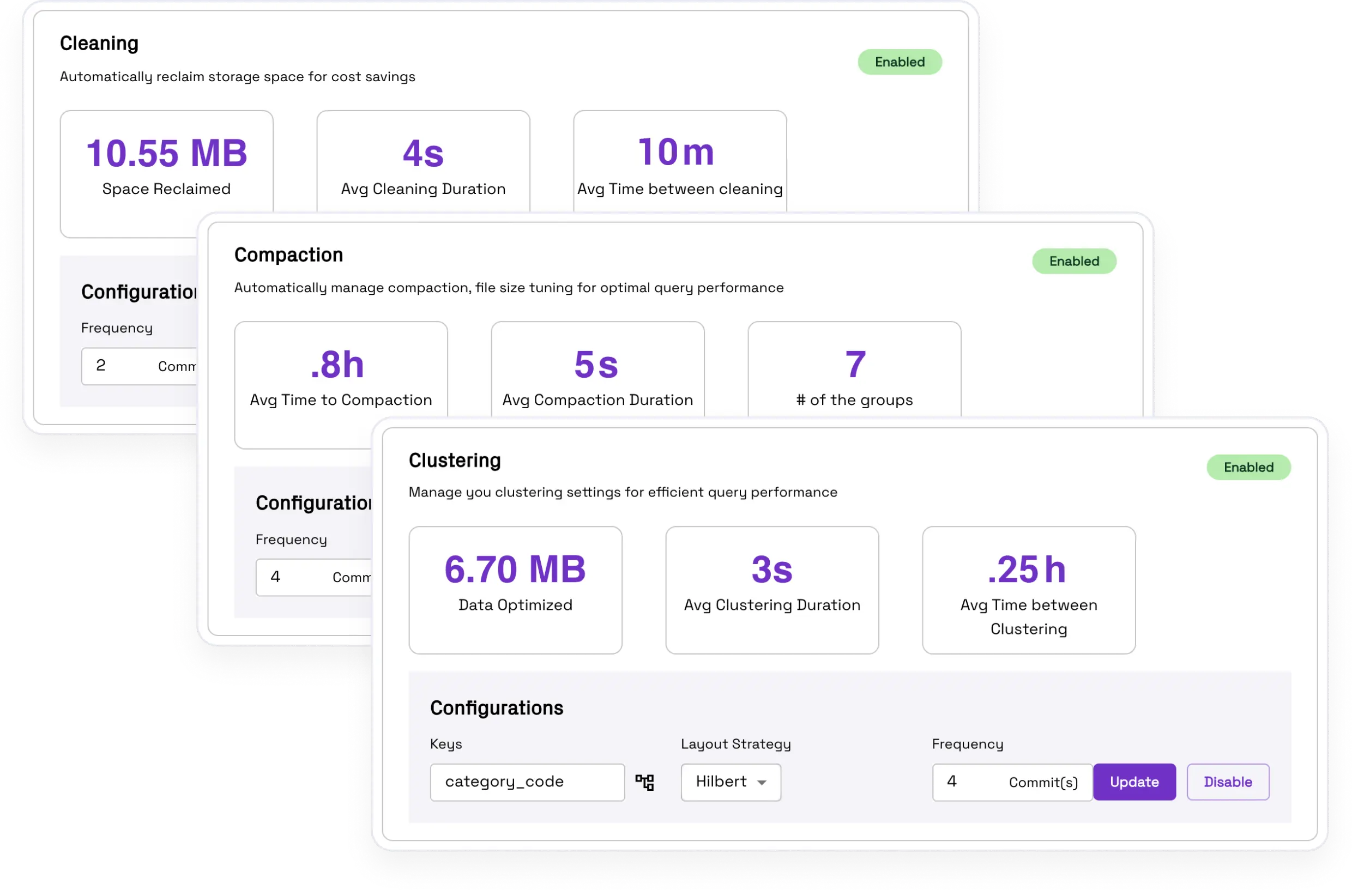
Auto-optimized lakehouse storage
Automate lakehouse table services to keep costs low and get up to 10x faster queries on your tables.
Explore Table Optimizer
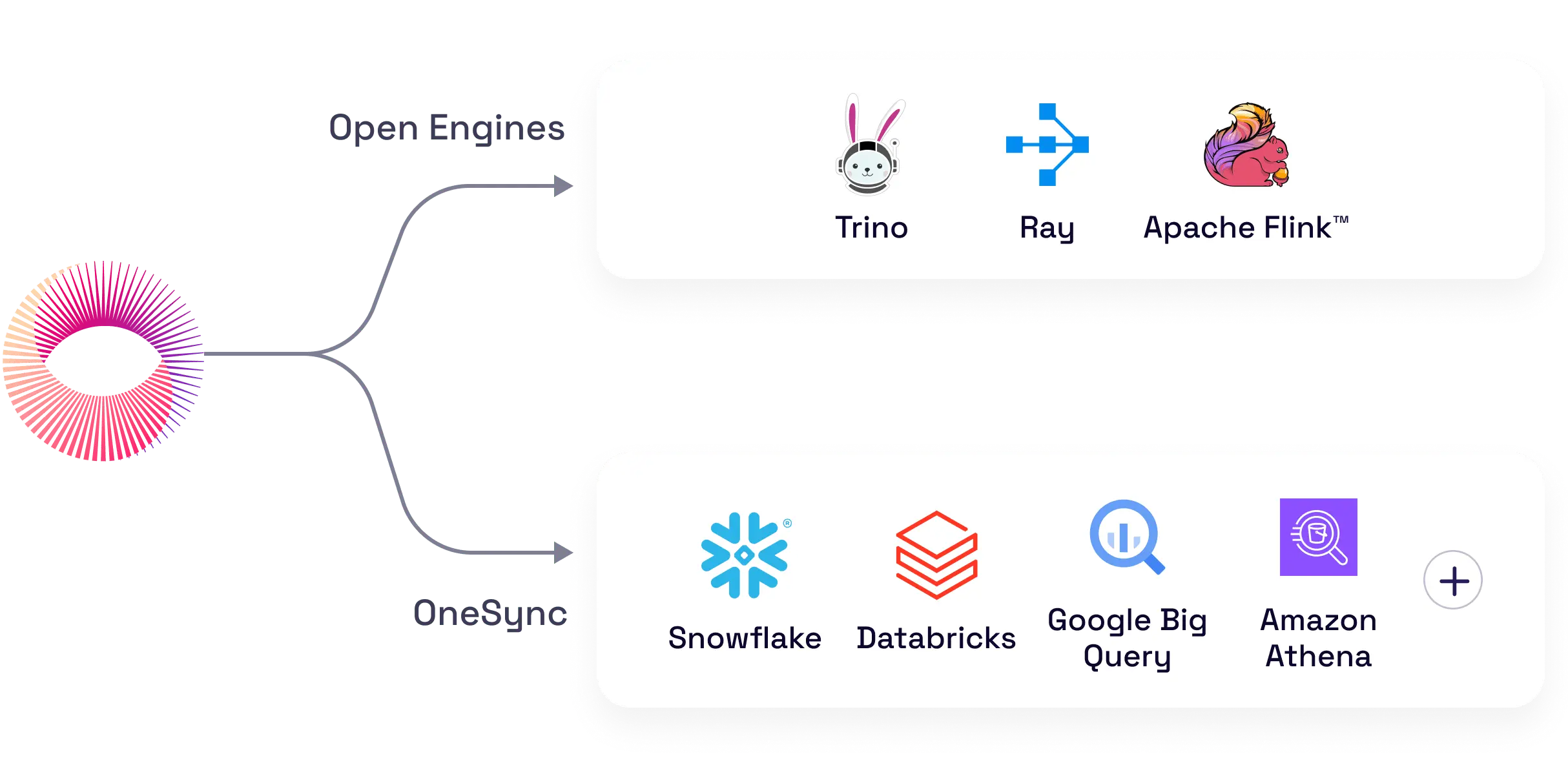
Keep your data open, query with any engine
Easily query your data with open engines such as Trino, Ray, or Apache Flink on Onehouse-managed clusters.
Prefer to use another query engine? Sync your tables to external catalogs to query with any engine, including Snowflake, Databricks, and Amazon Athena.

Data stays private in your VPC
Onehouse stores and processes data in your own cloud environment, ensuring maximum data privacy while delivering a fully-managed experience.
Explore Our Privacy-First Architecture
Prefer to run your own Kubernetes? Explore our Quanton K8s Operator.
Serving any stage in your data journey
Mix and match Onehouse features to build your ideal data stack, whether you're looking to accelerate existing Spark jobs, reduce warehouse costs, or build a net-new analytics platform

Faster, cheaper Apache Spark
Move existing workloads to our Spark-compatible Quanton engine for instant savings, without migration.

Free your data (and wallet) from the warehouse
Switch to open storage. Continue querying with your warehouse, or easily adopt open engines.

Build your data lakehouse from scratch in hours, not months
Use a managed platform for fast data ingestion, efficient transformations, and auto-optimized tables.
Modular lakehouse architecture
Deploy Onehouse in your VPC and choose the features you want. Only pay for what you use.
Deployment Options



.webp)
From Any Source
Cloud Storage

Database CDC
Streaming
Fast, Incremental Ingestion
- Fully managed operations to reduce engineering overhead
- Automated performance tuning and real-time monitoring
- Built-in tools for compliance and data integrity
- Single source of truth for all data operations
Universal Data Storage



Support for All Table Formats with Xtable
- Seamless data transformation across formats
- Universal query compatibility for analytics, ML, and GenAI
Multi-Catalog Synchronization






Multi-Catalog Synchronization
- Simultaneously sync data with Snowflake, Databricks, Big Query, and more
- Access data across multiple query engines from a single managed pipeline
Open Engines



Open Engines
- Deploy open source compute engines against a single copy of data in your lakehouse tables for stream processing, BI, and AI
- Eliminate the complexities of manual deployment and proprietary lock-in of traditional systems
Lakehouse Workloads

Streaming Ingestion

Incremental ETL

Table Optimizations

Low-Latency Queries
Lakehouse Workloads
- Real-time data streaming for instant insights
- Smart incremental ETL for efficient pipelines
- Automated table optimization for peak performance
- Fast, interactive SQL queries on the lakehouse
SQL and Spark Jobs

Quanton™ Engine
SQL and Spark Jobs
Deliver 2-3x price/performance gains on SQL and Spark-based ETL pipelines using your existing tools and libraries, with Quanton Engine on Onehouse Compute Runtime.
Onehouse Compute Runtime

Adaptive Workload Optimizer

Serverless Spark Compute

High-Performance Lakehouse I/O
Onehouse Compute Runtime
- Intelligent workload optimization with multiplexed scheduling and automated performance tuning
- Serverless Spark with elastic scaling and cost-optimized spot instances
- High-performance I/O with vectorized processing and optimized storage access
Deliver Data to Any Workload

Warehouse

Query Engines

AI/ML Platforms

Vector Database
Deliver Data to Any Workload
- Leverage open-source formats in your own cloud buckets for ultimate control and flexibility.
- Use any engine, integrate across catalogs, and access your data from multiple platforms & query engines seamlessly.
Explore Platform Details
Start Your Free Trial
Optimize cost-performance with a data lakehouse platform in your VPC on any cloud, delivering faster pipelines and queries with autoscaling compute, rapid ingestion, and auto-optimized open tables for analytics and AI.