Onehouse LakeBase is now Lakegres™
Over the past few months, a lot of people have noticed that both Databricks and Onehouse were shipping something called "Lakebase." Databricks announced Lakebase Postgres last summer, pairing Postgres with lakehouse capabilities. We'd independently been building toward a similar vision for years — adding database-grade primitives like indexing, caching, query serving, and context serving directly onto open lakehouse tables — and earlier this year we announced Onehouse LakeBase: a distributed SQL engine with Postgres protocol compatibility, purpose-built for AI and analytical serving workloads on the lakehouse. Consistent with our practices as a smaller startup, we had filed an intent-to-use trademark application before our announcement. There are even some good community blogs out there, comparing the approaches.
Both the companies came together 4 years ago to broadly define what the lakehouse architecture means, and now the data lakehouse is the industry standard for cloud data management. Both the companies now employ a good number of core contributors to the three major lakehouse open table formats. Over the last few months, we’ve been working with Databricks towards a reasonable proposal: treat "lakebase" as a category — just as they intend to, not a product name. We would drop our trademark application as well. The broad idea of bringing database workloads directly onto lakehouse architecture will be an exciting new industry category — rather than limiting it to a product name any single vendor owns. No one should be able to trademark a category, any more than someone should own a "data warehouse" or "database" or “data lakehouse”.
We spent the last two months trying to reach that outcome together. We couldn't converge on it. And more recently, another category term has been folded into a product name — as well with "Lakehouse//RT" — which only adds to the confusion for everyone trying to make sense of this space. So rather than spend the next few years litigating a word (which is not an easy undertaking for a company of our size), we're going to do the more useful thing and ship. We're renaming.
Meet Lakegres
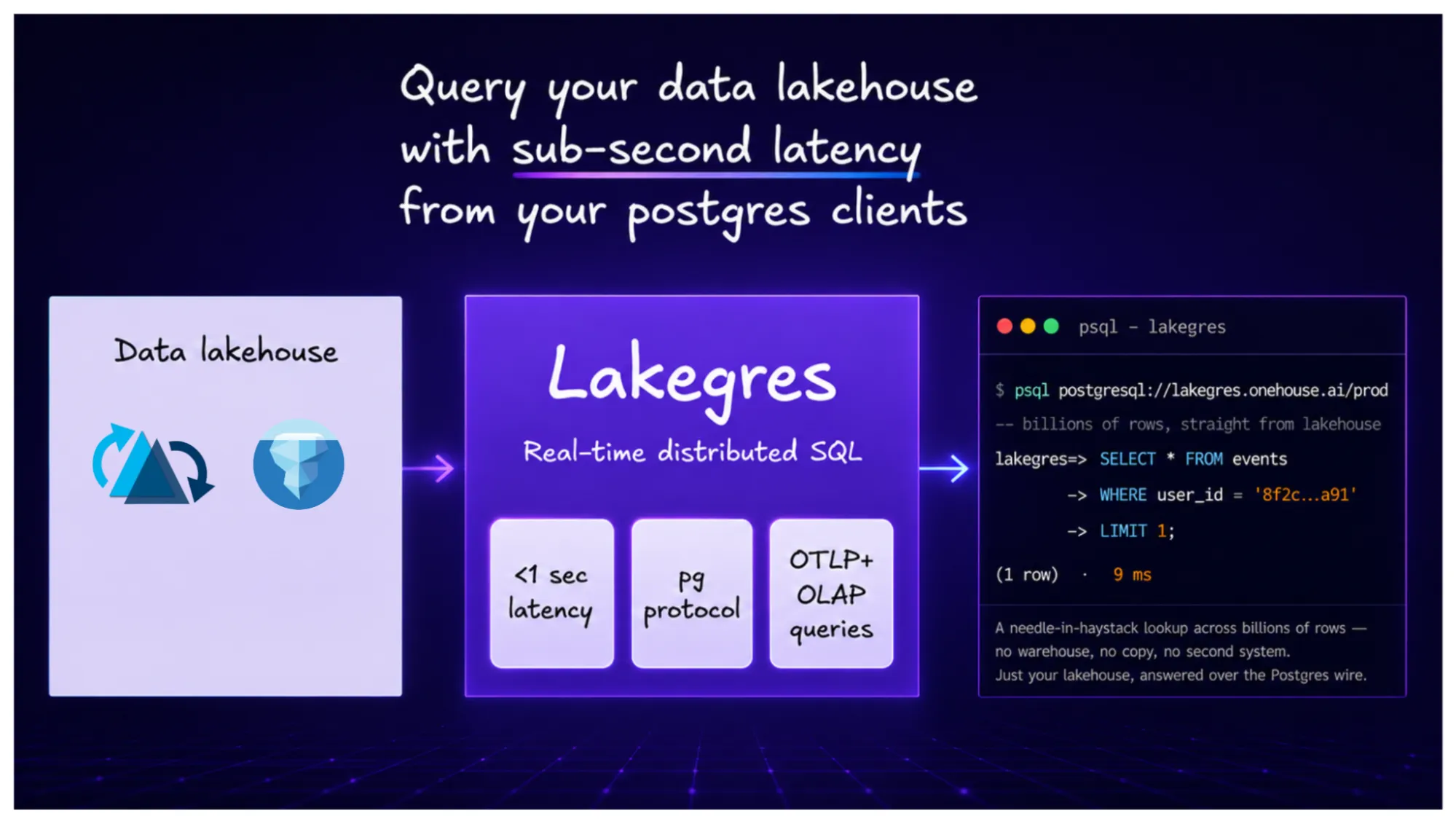
Lakegres is a Postgres-wire compatible serving layer that makes your open Apache Hudi™ and Apache Iceberg™ tables queryable at database speed — millisecond lookups, not minute-long scans — without copying data anywhere.
To be clear about what it is and isn't: Lakegres is not a database, and it's not a Postgres RDBMS you migrate to. Postgres is the wire protocol your tools already speak; your lakehouse data stays the single source of truth.
Name aside, here's what actually matters: we have gotten faster and faster since launch.
- 6× faster data exploration with columnar caching and joins on open tables
- Millisecond point lookups — needle-in-a-haystack queries across billions of rows, straight on Iceberg and Hudi
- High-QPS, low-latency serving built for agent-scale concurrency, behind one Postgres endpoint
- p99 latency down 50% since launch
Here’s what our early users are seeing on their production workloads compared to Trino or AWS Athena.

Point psql at it and query your data lakehouse in real time.
See for yourself. Try Lakegres free → or talk to our engineers →.

Read More:






Subscribe to the Blog
Be the first to read new posts