Databricks Iceberg Support Has a Catch. It's Called Unity Catalog.

The Iceberg Interoperability Promise
Apache Iceberg was built around one architectural principle: no single vendor owns your data. The spec is open, the catalog protocol is open, and any engine that implements the reader/writer spec can interoperate with any other without translation layers, without data copies, without routing through a control plane you don't control.
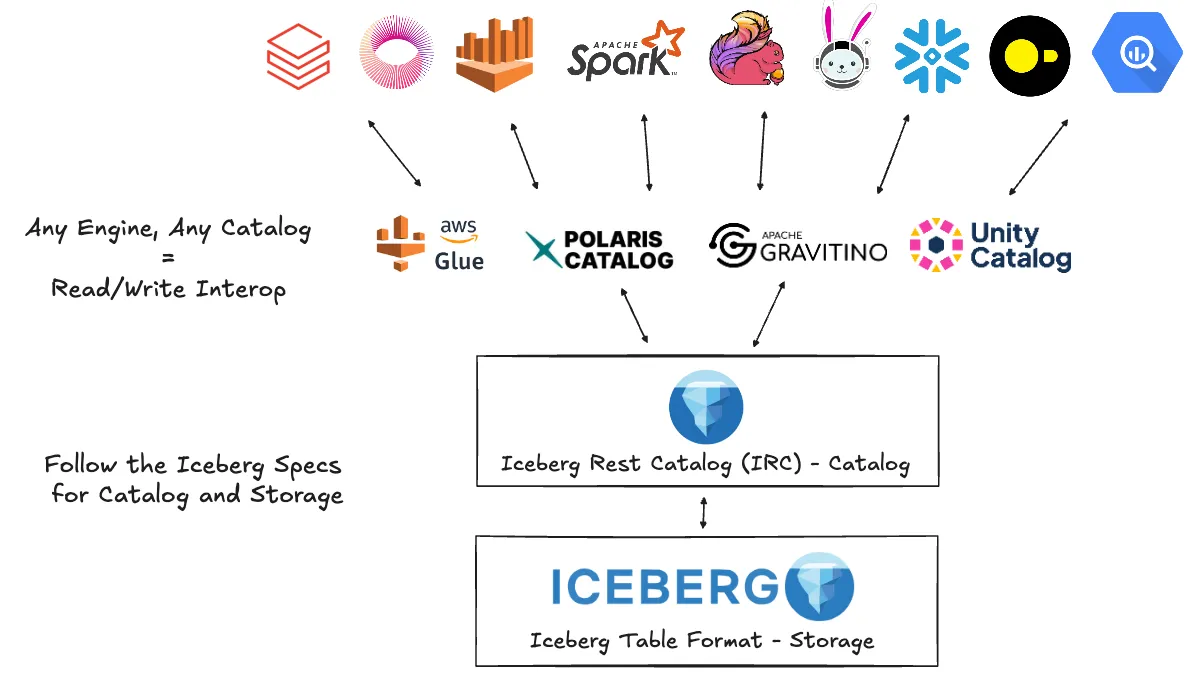
That last part is what matters architecturally. The Iceberg REST Catalog (IRC)exists precisely so that catalog governance is decoupled from compute. Apache Polaris, Project Nessie, AWS Glue, Snowflake Horizon: any vendor that implements the IRC spec becomes a first-class governing catalog for Iceberg tables. The compute engine (Spark, Flink, Trino, DuckDB, Athena, BigQuery) doesn't need to know or care who's governing. It speaks IRC. The data sits in your object store. You own it. That separation of compute from catalog is not an implementation detail; it is the entire value proposition of the format.
The breadth of native engine support today reflects how seriously the ecosystem has taken this promise. Spark, Flink, Trino, DuckDB, Snowflake, Athena, BigQuery are all reading and writing the same underlying files, governed by whichever catalog your team chooses, with no single point of control. This is in production at companies running serious multi-engine lakehouse stacks, and the interoperability story is exactly why teams have been migrating to Iceberg from proprietary formats.
What’s below the surface of the Databricks Iceberg?

"Full performance. Full interoperability. No tradeoffs."
That is Databricks' own headline for its Iceberg support as written by the original Iceberg creators. Databricks certainly has earned purchased the right to be taken seriously on a claim like this. This is the vendor that paid over $1 billion to merge a competing table format into their own. Despite taking 2yrs to reach “Public Preview”, if the headline claim here held, Databricks could be one of the strongest platforms anywhere for running a multi-engine Iceberg stack: write from Flink, query from Trino, govern from the catalog of your choice, with Databricks as one engine among equals.
But the test of that claim isn't just reading the announcement. It's the limitations section of Databricks' own documentation, and reading the two side by side is disorienting, because they describe different products. The announcement describes the open lakehouse Iceberg was designed for. The documentation describes an implementation where Iceberg exists only inside Unity Catalog, every external catalog becomes read-only, and a substantial list of Iceberg-native features are simply absent.
The information that follows walks through documentation in detail, what's mandatory, what's read-only, and what's missing. While the majority of this blog will stick to public docs and community references, if anyone is interested we also have a pile of receipts from our experience supporting Iceberg users in production who face regular frictions when integrating with the Databricks platform.
Unity Catalog Is Not Optional

To use Iceberg on Databricks, Unity Catalog is mandatory. This is not a configuration default you can override; it is a hard architectural requirement stated plainly in the Iceberg documentation:
"You must meet the following requirements: A workspace with Unity Catalog enabled."
What this means concretely: you cannot use Apache Polaris, Project Nessie, AWS Glue, or any other Iceberg REST Catalog for Iceberg tables with Databricks. You cannot mix/match that part of the stack. To make sure this is locked down tight the LOCATION property (which would let you specify where table metadata lives) is not supported for Iceberg in Unity Catalog. Databricks controls the metadata path. The legacy Hive Metastore path is also closed entirely. Unity Catalog is Databricks' proprietary SaaS metadata layer; it is not an IRC implementation you can run elsewhere, substitute with an equivalent, or operate outside Databricks' control plane.
The whole point of the IRC standard is that any conforming catalog can govern any table. Unity Catalog's mandatory status is a direct contradiction of that principle, and the asymmetry this creates is worth stating precisely. External engines (Spark, Flink, Trino) can connect to Unity Catalog as an IRC server and read/write Databricks-managed Iceberg tables. That half of the interoperability story works. What doesn't work is Databricks compute acting as an IRC client connecting outward to Polaris, Nessie, or Glue. The IRC standard flows one direction on Databricks: inward to Unity Catalog.
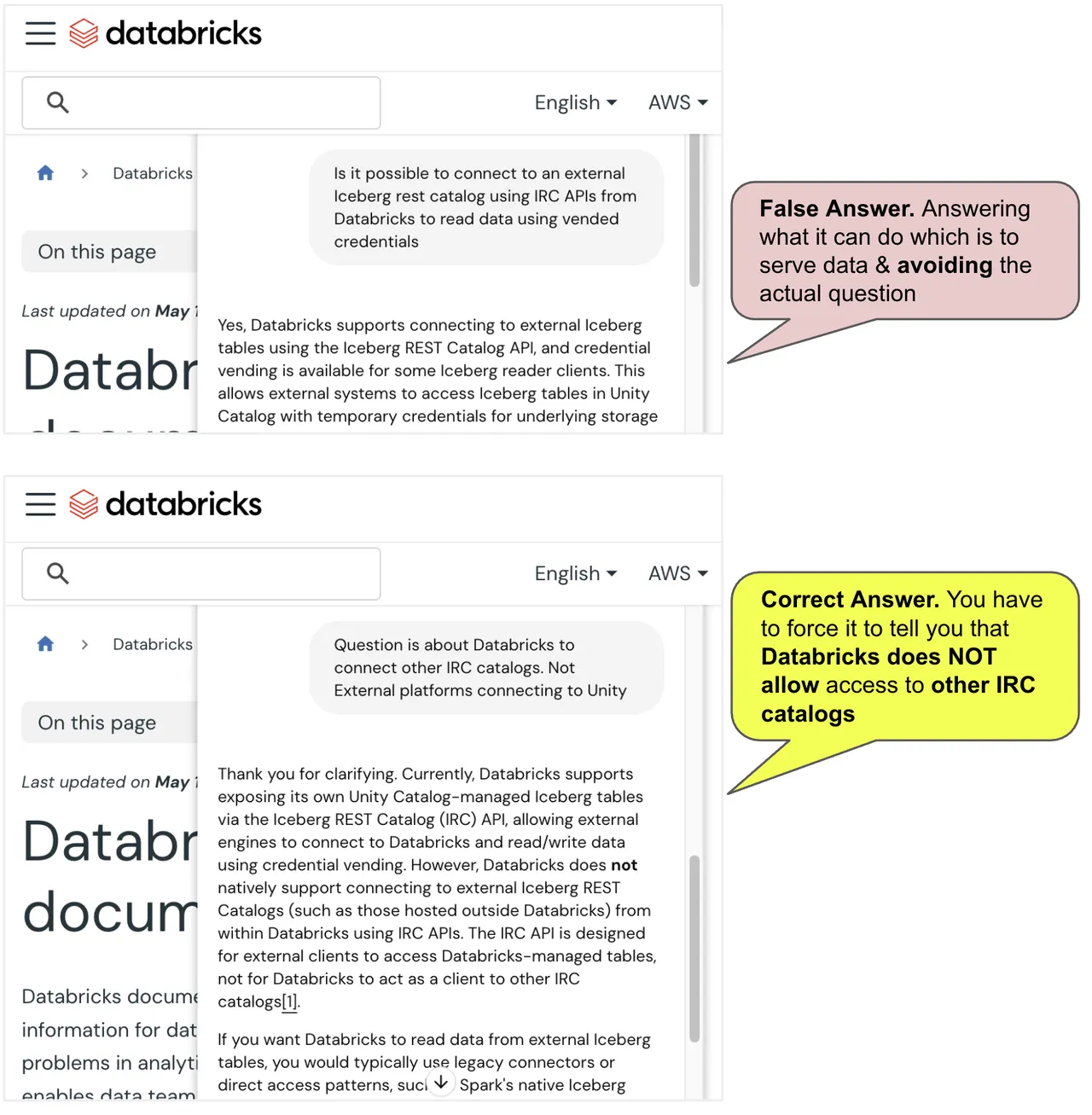
The asymmetry is confusing enough that a community member even pointed out how Databricks' own AI assistant gets it wrong. Ask Genie whether Databricks can connect to an external Iceberg REST Catalog using IRC APIs with vended credentials:
What about Foreign Catalogs and Foreign Tables?
In an open standard, "foreign" shouldn't be a meaningful category. That's the point of a spec: a table is a table. The same metadata layout, same file formats, same commit protocol no matter which catalog governs it. An engine that fully implements the Iceberg specification shouldn't care whether the catalog on the other end is Glue, Polaris, or Horizon, any more than a browser cares which server is hosting a web page.

Databricks' own vocabulary describes the sticky situation. Any Iceberg table governed by a catalog other than Unity Catalog (anything outside Databricks' control plane), is classified in the documentation as a "Foreign Iceberg table." Understand what that label is actually marking: these are spec-compliant Iceberg tables, byte-for-byte identical on disk to the ones Unity Catalog manages. The only foreign thing about them is who governs them. And "foreign" is not just a name, it's a separate, sharply reduced feature tier, and the first thing it costs you is writes:
"Foreign Iceberg tables are read-only in Databricks and have limited platform support."
Your Flink pipeline writes to an Iceberg table in Glue. Databricks can read it, but cannot write to it. Your Trino cluster materializes query results back to a Nessie-governed table. Same answer. Any part of your multi-engine stack that writes to a non-Unity Iceberg table has created a read-only surface from Databricks' perspective. What looks like a data mesh functions as a read-only archive for half your compute layer.
The limitations on foreign tables extend beyond writes. From the official docs, partition evolution is not supported, the partition spec on foreign tables cannot be changed from Databricks at all. Branching and tagging are inaccessible; only the main branch is readable, which means write-audit-publish patterns cannot be run against foreign tables. Time travel is broken in a specific and frustrating way: it only works for snapshots that have already been read through Databricks, not the full snapshot history. And new snapshots written by external engines are not automatically surfaced; you must call REFRESH FOREIGN TABLE manually each time.
The credential vending gap deserves its own treatment because it has downstream security consequences. When Databricks exposes Unity Catalog-managed tables to external engines as an IRC server, it vends scoped temporary credentials: time-limited, permission-scoped access tied to the requesting Databricks principal. That's the secure model you'd expect from an enterprise governance layer. For foreign Iceberg tables, the official docs make the contrast explicit:
"Credential vending on Foreign Iceberg tables is not supported." (Databricks docs)
The practical consequence follows directly: "For foreign Iceberg tables without credential vending support, you must independently configure your Iceberg client with cloud storage credentials to access the files and metadata directly from the storage location." The governed, scoped access model that Unity Catalog applies to its own tables simply does not extend to tables governed elsewhere. Storage credentials have to be configured manually, outside Unity Catalog's governance layer, by each team managing their own access path. The same governance posture that makes Unity Catalog attractive for internal table management is absent the moment you reach outside it, just when you'd want it most. Databricks' own documentation signals why: "Reading and writing to external tables from multiple systems can lead to consistency issues and data corruption because no transactional guarantees are provided for formats other than Delta Lake." The system guards against certain concurrent writes at the platform level because the risk is real enough to require it.
One more thing worth calling out: Databricks will likely counter this with their Federated Catalog offering. Don't mistake it for a solution to the interoperability gap. Federated Catalog works by routing metadata SQL queries through Databricks' own host. It does not implement IRC client capabilities, it requires granting Databricks access to your storage buckets, and it keeps the data path flowing through Databricks' control plane. The buzzword obscures what's actually happening: you are paying Databricks' compute to query your own data, through their engine, managed on their terms. That is not cross-catalog interoperability. That is Databricks-mediated access to tables you already own.
Even the Happy Path Is Missing Iceberg Features
Databricks pleads its case by calling out how Foreign Tables should be considered a temporary solution or workaround until you can make enough time to migrate everything over into Unity Catalog.

Once you migrate everything into managed Iceberg tables in Unity Catalog, the compromises end right? Full commitment, full feature set. All good now, right?
That assumes a principle worth making explicit: Iceberg isn't just a file layout, it's a feature contract. Partition transforms, partition evolution, branching and tagging, standard delete semantics, streaming. These are capabilities the spec defines and the reasons teams choose Iceberg in the first place. An implementation that stores data in Iceberg's format but doesn't deliver Iceberg's features hasn't implemented the standard, it has implemented shallow read/write compatibility with it. On Databricks' happy path, managed Iceberg in Unity Catalog with no foreign tables and no external catalogs anywhere, substantial parts of that contract are missing.
Start with partitioning. Iceberg's powerful expression-based partition transforms (years(), months(), days(), hours(), bucket()) are not natively supported in Databricks SQL. Partition evolution from Databricks SQL is similarly unavailable on managed tables and requires an external engine for what should be a routine schema operation. Databricks' response to this is usually Liquid Clustering, their proprietary alternative to partitioning. Any external engine connecting to your table via IRC sees none of it, which means you've structured your table for single-engine optimization while operating under the assumption of multi-engine access.
Branching and tagging are entirely missing. Databricks has no support for Iceberg's branching semantics: the Git-like branching model that underpins write-audit-publish patterns, data pipeline CI/CD, environment-isolated staging, and canary data deployments. This is not a feature in preview or behind a flag. It is simply absent for Iceberg tables on Databricks. Streaming has the same structural problem from a different direction: managed Iceberg tables don't support streaming reads or writes via DLT or LakeFlow because Change Data Feed support (required for streaming semantics) is Delta-only on Databricks. Real-time ingestion pipelines must either stay on Delta or build separate infrastructure around the managed Iceberg path entirely.
Delete file compatibility adds another layer of friction for multi-engine teams. Databricks implements deletion vectors (an Iceberg v3 construct) as its exclusive delete mechanism. Standard Iceberg v2 position deletes and equality-based deletes, the current write pattern across the majority of Iceberg engines in production today, are not supported. Tables written by Flink, Trino, or other engines using v2 delete semantics may not read correctly in Databricks. If any part of your pipeline writes v2 delete files, you now have an active compatibility surface to track and manage across every engine in your stack. Beyond deletes, views are not accessible from external Iceberg engines connecting via IRC, and Delta Sharing of managed Iceberg tables to external Iceberg clients is not supported.
Databricks' Own Products Don't Write Iceberg
There's a faster test than auditing limitation docs: look at what a vendor's own products do when nobody is framing the answer. A platform that considers a format first-class builds its hero products on it. Walk the documentation for the products Databricks actually puts on keynote slides, and Iceberg is missing from many of them:
- Zerobus Ingest, the sub-second ingestion service headlining Lakeflow Connect, supports writing only to managed Delta tables. There is no Iceberg target.
- Lakeflow Declarative Pipelines (formerly Delta Live Tables) produce streaming tables and materialized views that are Delta-backed. You cannot point a pipeline at a managed Iceberg table as its output, and you cannot even enable Iceberg reads on what it produces.
- Streaming from managed Iceberg is intentionally disabled, because Change Data Feed, the mechanism every Databricks streaming feature depends on, is a Delta-only construct. Databricks' own community answer: if you need streaming today, Delta plus CDF is the supported path.
- Lakegres accepts managed Iceberg sources for synced tables only in snapshot mode; triggered and continuous sync require CDF, so they're Delta-only too.
- AI Search doesn't support managed Iceberg at all.
- Feature Store can't use Iceberg. Feature tables in Unity Catalog are Delta tables by definition, requiring a primary key constraint, and constraints aren't supported on managed Iceberg. An Iceberg table cannot be a feature table, full stop.
The pattern isn't subtle. The core SQL engine reads and writes Iceberg; nearly everything built on top of it assumes Delta. "Full Apache Iceberg support" describes one layer of the platform, while the products Databricks is actually betting its roadmap on quietly require the format the announcement implied you could move beyond.
The Lock-In Is Invisible at Adoption Time
The structural problem with Databricks' Iceberg story is not that the limitations are hidden (they're in the official docs) but that none of them surface at the moment you adopt. The blog announcement says full interoperability, no trade-offs. The sales motion says open format. The first tables work exactly as described. The gaps emerge later, when your Flink team tries to write to a table already committed to Unity Catalog, when you discover streaming is broken for managed Iceberg with no timeline for resolution, when you try to partition-evolve a table from Databricks SQL and hit the wall. Teams that chose Iceberg over Delta specifically to escape format lock-in have, in some cases, traded Delta lock-in for Unity Catalog lock-in, with a shorter feature list in either direction.
The migration cost is front-loaded but invisible, which makes it dangerous. Databricks acknowledges directly that "rewriting petabytes of data is impractical." Managed Iceberg tables in Unity Catalog have no LOCATION clause; Databricks controls the metadata path. Once your tables are in Unity Catalog managed Iceberg, moving them to a different catalog means rewriting at scale. The exit cost compounds with every table you commit, every pipeline you build against Unity Catalog's Iceberg API, and every team that standardizes on Databricks as their write path. The lock-in is invisible at entry and expensive at exit, exactly the kind of architecture decision that looks fine for eighteen months and becomes painful in month nineteen.

The open format bet, taken in full, doesn't pay off on Databricks. The implicit promise was engine-agnosticism: query with Snowflake, process with Flink, serve with Trino, manage with Spark, all on the same table, governed by whoever you choose, without routing everything through one vendor's control plane. On Databricks, you get Iceberg's file format with Unity Catalog's governance constraints imposed on top. You don't get the portability that justified choosing Iceberg over Delta. You don't get Delta's full feature set either. You land in the middle: a proprietary-governed Iceberg table that most Iceberg-native tooling can't fully interact with, and that you can't easily move when the constraints become visible.
Due Diligence for the Open Lakehouse
I hope you know as a reader that none of this adds up to a black and white "don't use Databricks" claim. It's a capable platform, and for a team already standardized on Databricks compute, managed Iceberg in Unity Catalog may be a rational choice. The problem isn't the product. The problem is the divergence between the Apache Iceberg vision and the direction of the current Databricks implementation. The danger is that architecture decisions get made on the strength of the former and then live with the consequences of the latter.
The lesson here generalizes beyond Databricks. In a lakehouse, the format is no longer the lynchpin; The critical decision that needs deep inspection is the catalog. Whoever governs your metadata controls which engines can write, which features work, and what it costs to leave. So stress-test the catalog with the same rigor the industry spent a decade applying to formats:
- Can a non-vendor engine both read and write to your tables? Read-only interoperability is an archive, not an architecture.
- Can the catalog be replaced without rewriting data?
- Which Iceberg features does your roadmap assume? Streaming, branching, partition evolution, standard delete semantics. Verify each one against the limitations page, not the announcement. They are different documents, sometimes published the same week.
- Where does governance stop? If credential vending and access policy only apply to tables the vendor manages, your security model has a boundary exactly where your multi-engine architecture begins.
The interoperability promise that made Iceberg worth adopting is real, and the ecosystem delivering it is stronger than ever. Just please don't let hollow marketing claims of ""Full performance. Full interoperability. No tradeoffs." drive your architecture decisions.

Read More:






Subscribe to the Blog
Be the first to read new posts