Introducing the Quanton Kubernetes Operator for Apache Spark™

TL;DR
Where the market stands
Apache Spark remains as the de-facto open data processing framework across the industry, with over $15B spent annually towards Spark platforms by over 20-30K+ companies. Over the last 2 years, something subtle but important has happened in the Spark ecosystem: Kubernetes has quietly become the default way to run open-source Spark.
To understand this more deeply, we analyzed public job postings over the last year to map out which Spark platforms companies are actively hiring for.
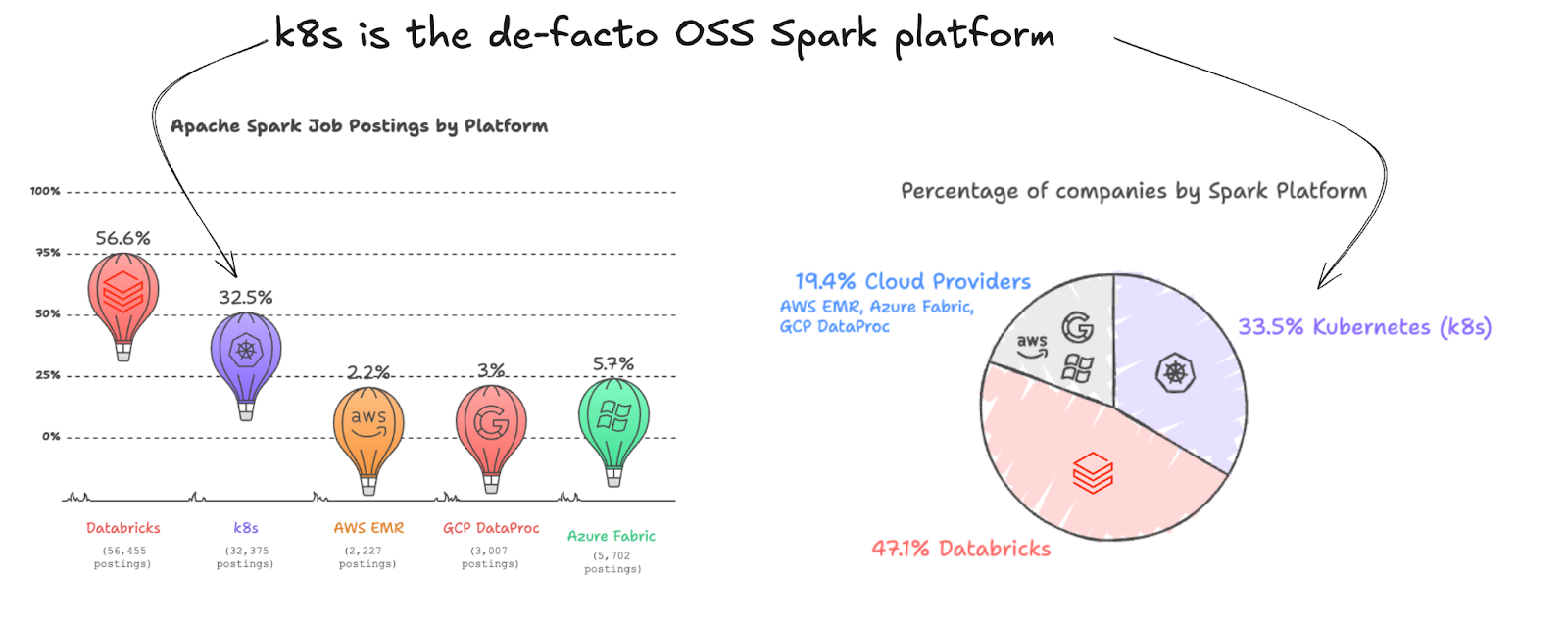
A few things stood out immediately:
- Databricks leads at ~47% — no surprise; Close to 10K orgs use Databricks, tracking Databricks' own reporting and telling us that this data is a credible proxy for Apache Spark usage.
- But Spark on Kubernetes is already at ~33%, making it the second most prevalent Spark platform by a wide margin against all the cloud provider platforms combined.
- All cloud-native managed offerings (EMR, Dataproc, Fabric) combined trail behind. Roughly, every 1/3 Spark usage is outside of managed Spark platforms (Databricks, the three major clouds)
So why are teams increasingly moving toward Kubernetes? It’s not because it’s easier - understanding and operating Spark on K8s requires significant effort from data teams. It’s also not because it’s faster - since managed Spark platforms often deliver better runtime performance (including Onehouse with Quanton, our homegrown fast Spark engine).
The k8s move preserves infrastructure ownership
Running Spark on Kubernetes gives organizations full ownership of their compute stack, allowing them to operate Spark like any other service on EC2/GCE-backed Kubernetes. This aligns with how mature infrastructure teams already manage shared compute across applications.
- Standardization of infrastructure: Spark becomes just another Kubernetes workload, benefiting from existing tooling for deployment, observability, cost attribution and chargebacks. This avoids introducing parallel infrastructure stacks and brings all compute usage under a unified control plane on k8s.
- Cost optimization: Teams can fully leverage cloud discount programs (reserved instances, savings plans, spot), often achieving 50–70% savings. These efficiencies accrue directly to the organization instead of being captured by managed platforms (e.g., Databricks Serverless, EMR Serverless).
- Security and compliance: Running within private VPCs or on-prem environments provides full control over data movement, networking, and access policies. This reduces exfiltration risk and simplifies compliance with data sovereignty and regulatory requirements.
- Portability and vendor independence: Workloads remain portable across clouds and on-prem environments, avoiding lock-in to a specific managed Spark provider and giving teams long-term architectural flexibility.
But sacrifices performance and increases complexity
Rolling your own Spark-on-Kubernetes often involves running vanilla open-source Spark, which can be both slow and tedious to work with, to say the least.
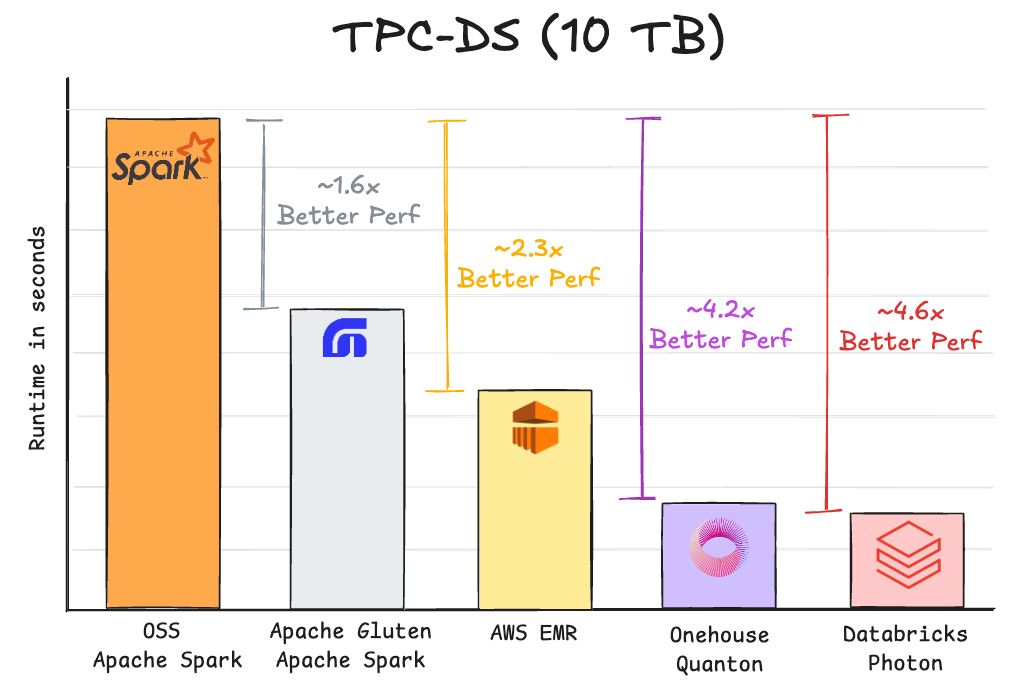
Fast Spark is tied to managed platforms: Across the industry, various communities and companies are hard at work pushing the performance boundaries for Apache Spark. Below is a summary of various projects, where they stand in benchmarks. Moving away from managed Spark platforms, also means walking away from these performance gains.
Spark infrastructure is complex: For any production grade Spark deployment, companies need to optimize shuffle storage, scale EBS/nvme volumes based on load, keep Spark Streaming jobs up & running without downtime, optimize memory management, instance selection and implement resource management across jobs. The know-hows required to successfully navigate these challenges are often split across infra and data teams.
These factors make it difficult for companies to realize the full potential of their Spark + k8s platforms, in terms of performance or reliability. Using the same data job postings data, we find that 36% of companies leveraging Spark + k8s, are also using one of the managed spark platforms.
Introducing Quanton Kubernetes Operator
Today, we are ending this weird friction Spark users have to endure, stuck between the convenience of Spark on k8s and the performance/reliability of a managed Spark platform.
We are excited to announce the Quanton Kubernetes Operator for Spark, packed with the power of Quanton, our execution engine purpose-built for lakehouse ETL/Spark workloads. The Quanton Kubernetes Operator (QKO) extends the open source Kubernetes Operator for Spark to deploy Quanton accelerated pods in your own Kubernetes infrastructure. Installation takes only minutes and it seamlessly integrates into your existing setup without any need to reconfigure k8s clusters or Spark jobs.
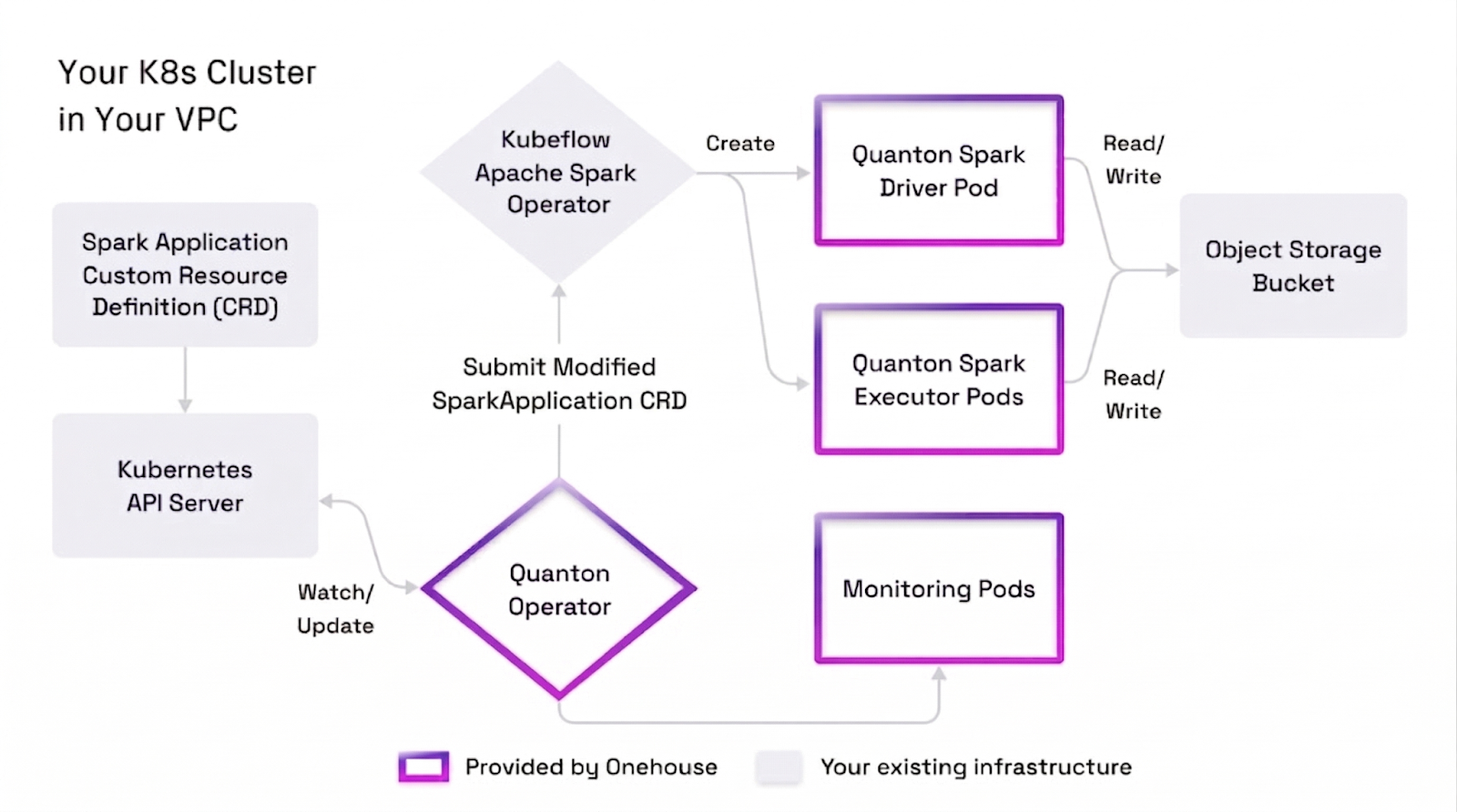
Deploying the Operator
The Quanton Operator works very similar to your existing Spark Operator installation, except it replaces the default OSS Spark image with our Quanton optimized Spark image. Please refer to the Quanton Operator on Github for pre-requisites, limitations, a simple local quickstart and benchmark tools. If you have Claude Code, you can easily vibe all those steps with the included skills.
In general, getting started takes 3 simple steps:
[1] Download the YAML and install Quanton Operator helm chart
Download the onehouse-values.yaml from Onehouse console that gives you credentials to install the operator. You would need an Onehouse account, discussed below in the blog. Then, proceed to install the Quanton operator on your k8s cluster.
helm install quanton-operator oci://registry-1.docker.io/onehouseai/quanton-operator \
-f onehouse-values.yaml \
--namespace quanton-operator \
--create-namespace
[2] Run your Spark application
To run any Spark application, create a custom resource definition (CRD) that is similar to what you use with the standard KubeFlow Spark Operator. The manifest mirrors the standard Kubeflow SparkApplication spec — just nest your existing spec under spec.sparkApplicationSpec and the migration effort is minimal. The Github repo includes a migration tool that can help you convert 100s of existing Spark jobs at once.
Below is an example CRD with the Quanton Operator:
apiVersion: "quantonsparkoperator.onehouse.ai/v1beta2"
kind: QuantonSparkApplication
metadata:
name: spark-java-minimal
namespace: default
spec:
sparkApplicationSpec:
## nest the `spec` block from your existing SparkApplication CRD here
type: Java
mode: cluster
image: "gcr.io/spark-operator/spark:v3.1.1" ## Operator will replace this
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: "local:///opt/spark/examples/jars/spark-examples_2.12-3.1.1.jar"
sparkVersion: "3.1.1"
driver:
cores: 1
memory: "512m"
serviceAccount: spark-operator-spark
executor:
cores: 1
instances: 1
memory: "512m"
[3] Apply the manifest and verify your job is running
The commands below submit the Java/Scala job to the operator. For PySpark, The Quanton image ships with Python 3.9, 3.11 (default), and 3.12. Select a version by setting the PYSPARK_PYTHON and PYSPARK_DRIVER_PYTHON environment variables on both the driver and executor specs. Mount your application code via a ConfigMap or a persistent volume. See Github again for examples.
kubectl apply -f your-quanton-spark-app.yaml
kubectl get pods -n default -w
The Quanton Operator is designed for teams that demand production-grade reliability, security, and observability from day one. This includes mTLS encryption, JWT-based authentication with automatic refresh, least-privilege RBAC, Spark parameter masking, kubernetes namespace isolation and comprehensive observability using rich metrics via OpenTelemetry. We have also included a seamless integration with Apache Airflow using a first-class Airflow provider package, for scheduling Spark workflows on the Quanton operator.
Premium Performance for Spark on k8s
Last year, we announced Quanton - our lightning fast execution engine for Spark workloads. In comprehensive benchmarks against industry-standard workloads (TPC-DS, TPCx-BB, TPC-DI, LakeLoader), Quanton delivers 3-4x better performance than open-source Spark, without requiring any code changes. Since launch, Fortune 500 companies and high-growth startups alike have been running production Spark workloads on Quanton through Onehouse Cloud - cutting compute costs by 40-60% while improving job performance.
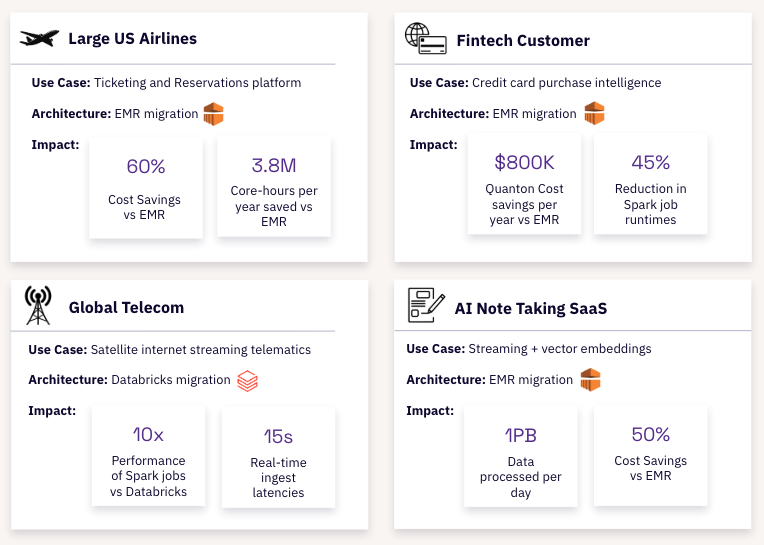
Quanton represents a purposeful evolution in lakehouse execution engines, designed to accelerate ETL workloads across open table formats like Apache Hudi™ and Apache Iceberg™. By innovating where it matters, Quanton matches (and often exceeds) the performance of the top proprietary Spark runtimes, at lower cost. For the first time in the industry, we’re bringing this powerful industry-leading performance directly to your k8s clusters, so you can further speed up your big spark batch jobs as well as achieve far superior cost/performance compared to managed Spark platforms out there. For a comprehensive technical analysis and performance benchmarks, check out this blog.
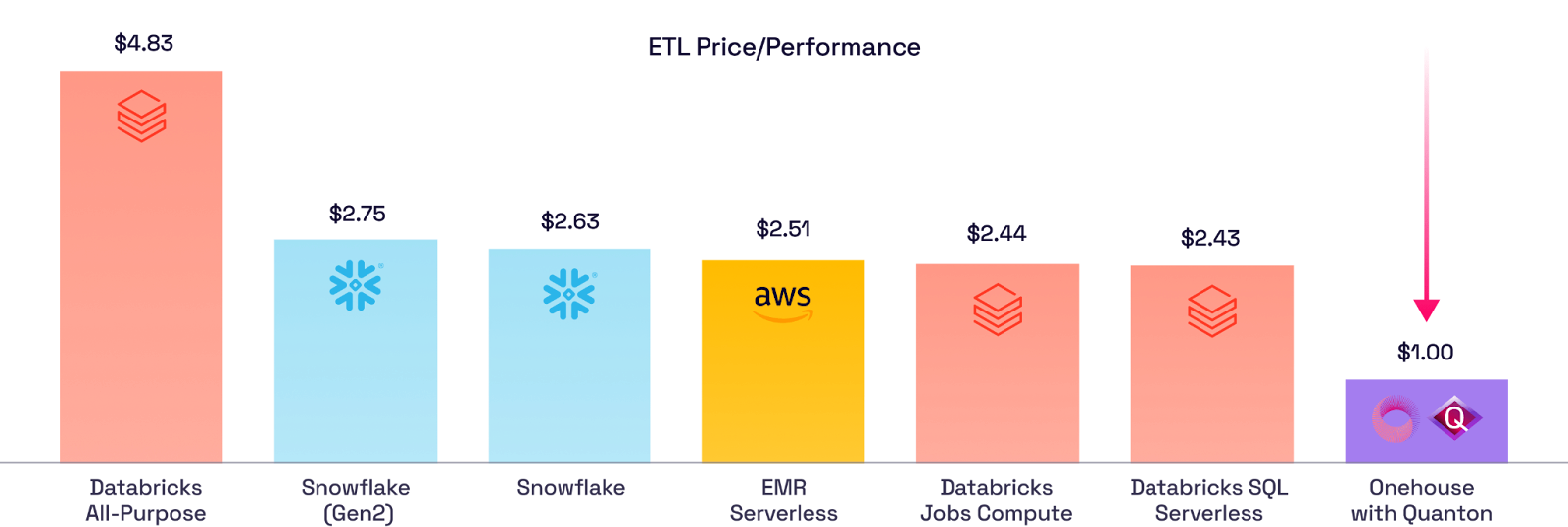
Do you want high confidence estimates of what Quanton can do for your specific workloads? Our free Spark Cost Analyzer tool analyzes your existing Spark history logs to identify bottlenecks and estimate performance gains.
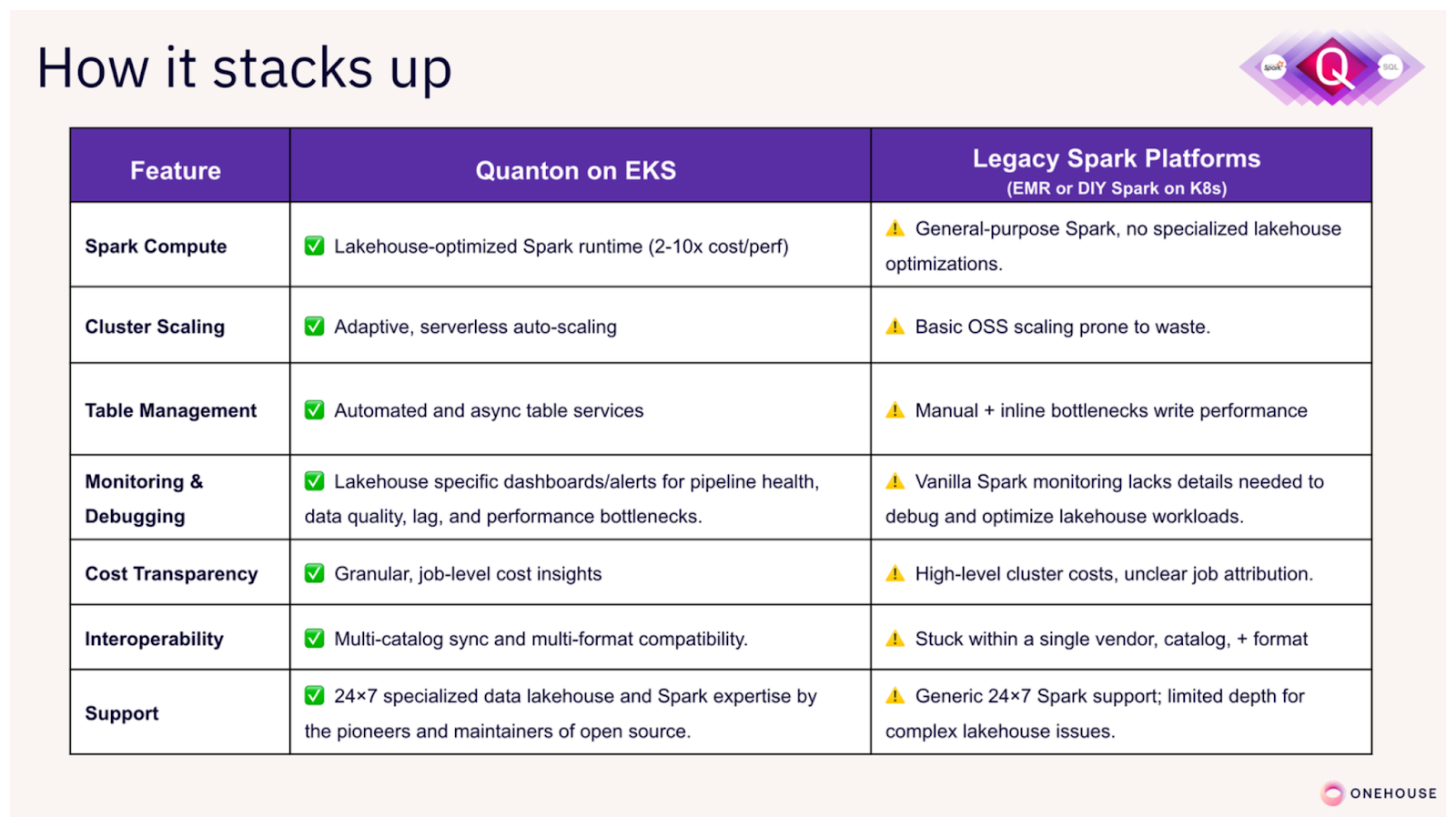
Smoother, Lakehouse Optimized Spark Runtime
The benefits of Quanton Operator does not stop with supercharging performance of your Spark jobs. It also delivers a seamless Spark experience by bundling components from the Onehouse Compute Runtime and integrating with the Onehouse control plane UI for easy access to all your Spark jobs through a single pane of glass.
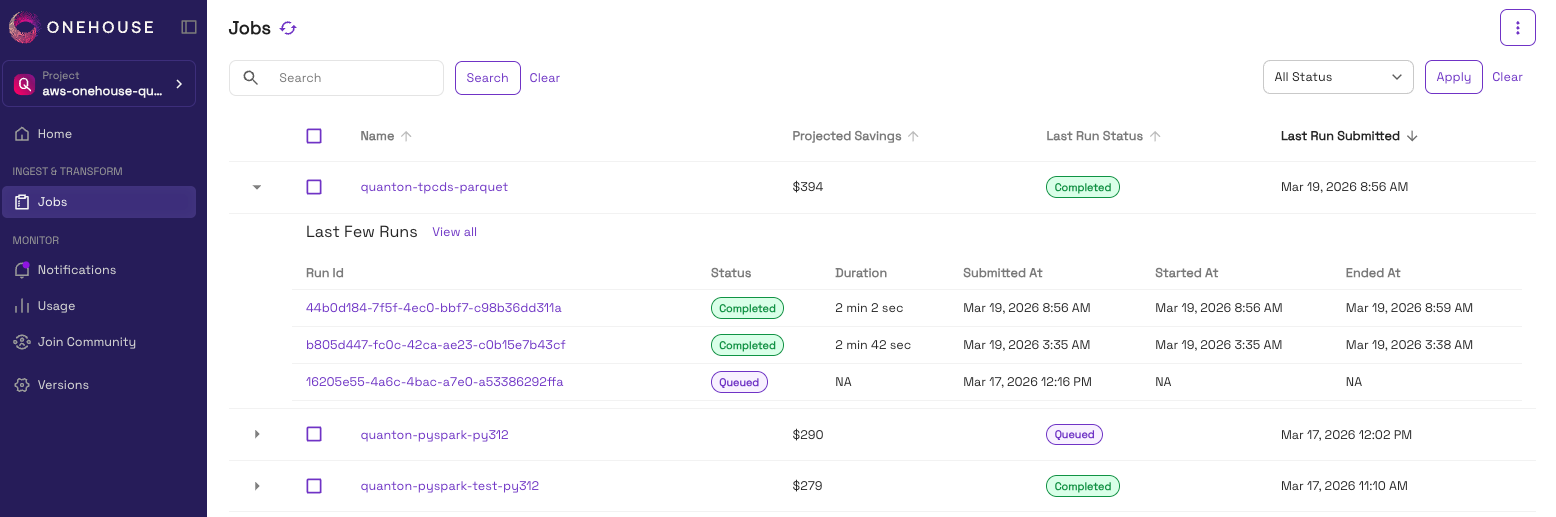
All Spark jobs you run through the Quanton Operator show up on the Onehouse UI. You can check the various runs for each Spark application and observe the savings you make across multiple runs for each Spark application you deploy with the Operator.
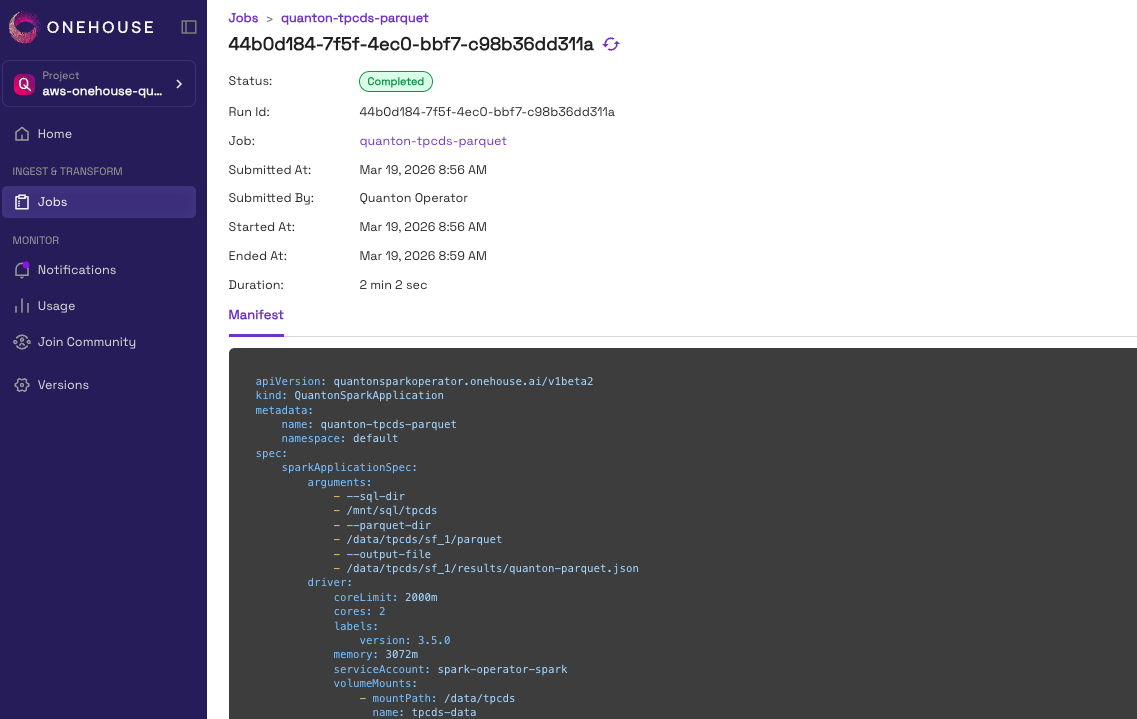
You could drill down further into individual runs for such Spark applications. For each run, we capture key metadata as well as the Spark Application Manifest YAML that was submitted at runtime.
Try it Today
Ready to accelerate your Spark + k8s workloads? Create an account here and our team will approve your request on a first-come, first-serve basis:
For years, teams running Spark on Kubernetes have had to choose between control and performance. Managed services offer speed but lock you in. Self-managed Spark gives you control but leaves performance gains on the table.
The Quanton Operator changes this equation. You get both: up to 4x faster Spark performance on infrastructure you control, with zero code changes and zero vendor lock-in. Read the documentation for details and join Slack to talk directly with our engineering team:
Whether you're processing petabytes in an air-gapped data center, or you want to maximize your existing K8s for advanced use cases, Quanton delivers the performance you need without compromising on your architectural decisions.
Create a Quanton Account | Try our Spark Cost Analyzer | Chat with a Onehouse Engineer | Read the Documentation | Register for Launch Webinar

Read More:






Subscribe to the Blog
Be the first to read new posts