Choosing the Right Data Ingestion Method: Batch, Streaming, and Hybrid Approaches

Modern, data-driven organizations collect data from multiple systems and applications to generate insights, make informed decisions, support AI use cases like predictive analytics or natural language processing, and gain a competitive advantage. This process of collecting and copying data from these diverse systems (internal and external) to the central data platform is known as data ingestion. The data is ingested and stored as is without transformations or manipulations, preserving its original raw form, as shown in the diagram below:
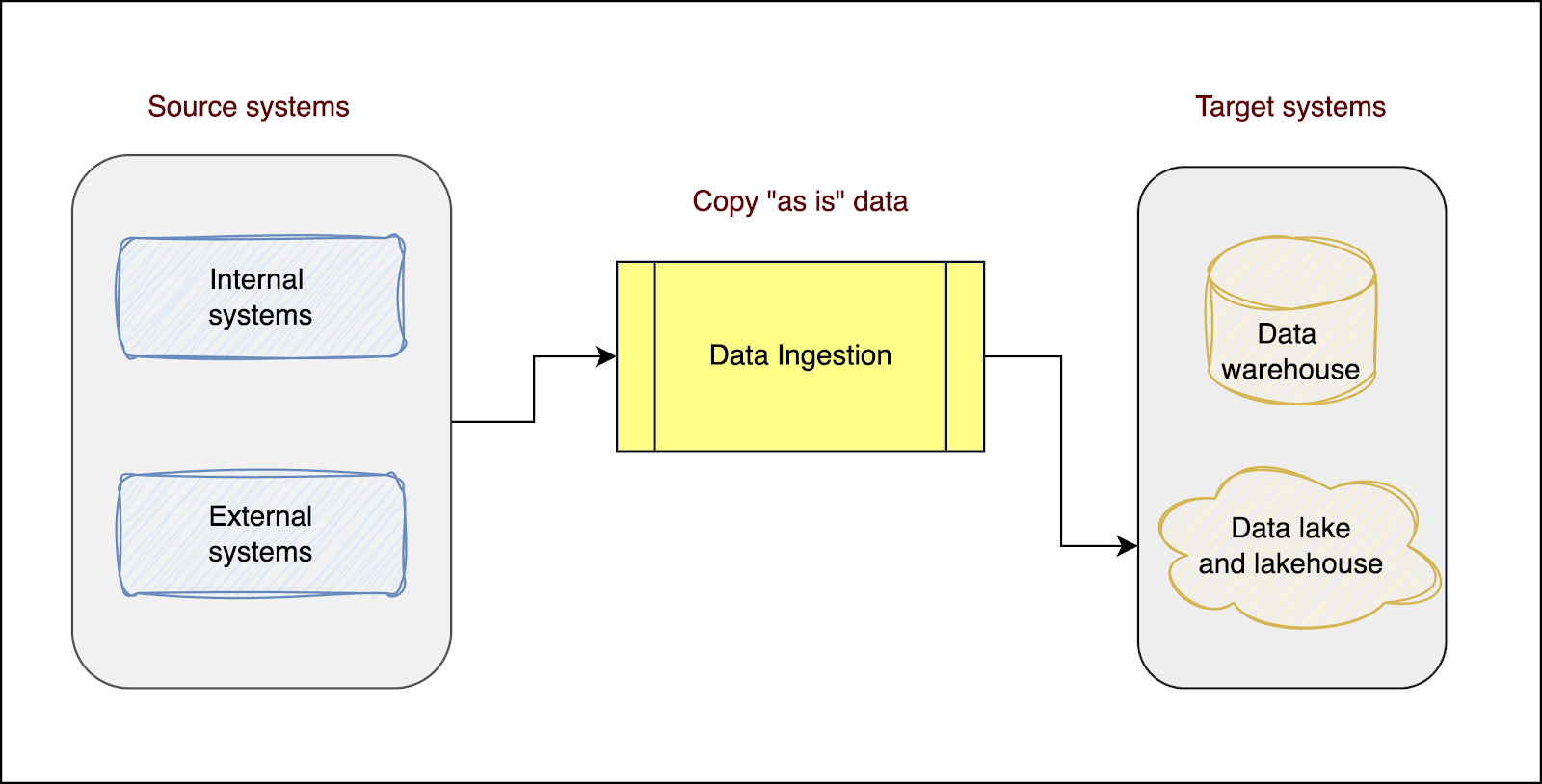
There are three approaches to ingesting data into your data platform:
- Batch data ingestion: Ingesting data in periodic intervals
- Streaming data ingestion: Ingesting data continuously in real time
- Hybrid data ingestion: A combination of batch and streaming approaches
Each approach has advantages and limitations that can impact the data processing efficiency, latency, and overall cost. In this article, you’ll learn the differences between these approaches, their pros and cons, and key considerations for selecting the right approach for your use case.
Batch Data Ingestion
Batch ingestion involves ingesting data at regular intervals. Data is extracted from the source system in batches triggered at a prescheduled time. The following diagram shows a batch ingestion process, where data is collected in fixed batches before being stored in target systems:

Traditionally, organizations used ETL (Extract, Transform, Load) tools to ingest data from source systems at the end of each day and load it into a central data warehouse.. Business intelligence (BI) applications would then use this data to generate dashboards and reports for business users the following morning. As business demand for quick decision-making increased, organizations started ingesting data multiple times a day by executing periodic micro-batches scheduled in intervals of a few minutes to a few hours. Many organizations now leverage the micro-batch approach to support batch workloads, enabling them to get quick reports and make agile decisions.
Use Cases
Batch data ingestion is best suited for workloads that need large volumes of data at periodic intervals and are fine with a data freshness latency of a few minutes or even hours. The batch ingestion approach is widely adopted in:
- Migration projects that need large volumes of historical data from existing systems
- Decision support systems (DSSs) to load data using overnight ETL batches
- A management information system (MIS) to generate BI reports to analyze sales and forecast demand
- Performance management systems based on KPIs, such as agent performance
- Periodic reporting use cases, such as regulatory reporting for banking and financial institutions
Pros
Batch data ingestion is one of the simplest methods for ingesting data and provides the following advantages:
- Simple and efficient approach for bulk-loading data
- Lesser execution cost than streaming data ingestion (discussed in detail in a later section)
- Can easily accommodate late-arriving data from source systems by either reprocessing or waiting enough time in between runs for late arriving data to reconcile.
- Less complication with orchestrating and monitoring periodic batches than streaming ingestion
- Enough time to debug any failures or data issues before the next scheduled run starts
Cons
The batch approach simplifies the data ingestion process but has multiple limitations, such as:
- Increased latency in copying data from source systems to target applications
- Real-time insights are not available for quick decision-making
- Not well-suited for systems that need time-sensitive data or applications that contain small, frequent updates
Streaming Data Ingestion
Ingesting data continuously as soon as it’s generated is known as streaming (or real-time) data ingestion. Streaming data ingestion is required for applications that perform streaming analytics (analytics on real-time data) and are time-sensitive. As shown in the diagram below, data is continuously copied from the source systems to your data platform to support real-time use cases:

Continuous data ingestion can be categorized based on latency requirements:
- Real-time ingestion, where data is processed as it arrives, often within milliseconds or seconds
- Near-real-time ingestion, where there is a small delay—typically seconds to a few minutes—between data generation and ingestion
Streaming systems can support both real-time and near-real-time use cases depending on how they’re configured and the application’s latency tolerance. While most organizations might be okay with near-real-time ingestion with a few seconds of lag, use cases such as fraud detection require streaming data ingestion for performing real-time analytics.
Use Cases
Streaming data ingestion is best suited for low-latency and real-time data applications. Some common use cases include:
- Credit card transaction monitoring for real-time fraud detection
- Recommendation engines, such as personalized product suggestions for e-commerce websites
- Real-time analytics such as ad performance tracking, IoT analytics, clickstream analytics, etc.
Pros
Streaming data ingestion offers multiple benefits over traditional batch data ingestion:
- Offers low-latency ingestion and reduces the data transfer lag between source systems and target systems
- Helps generate reports and dashboards in real time for business users for agile decision-making
Cons
While streaming data ingestion offers numerous benefits, it also presents significant challenges. Since it requires low-latency infrastructure to orchestrate, track, and control real-time flows, it often introduces increased cost and complexity:
- Technically demanding and requires complex code to manage updates, deduplication, fault tolerance, and idempotency on top of challenges such as data loss and late-arriving data
- These systems often generate many small files that increase compute load and I/O overhead, directly affecting query performance and requiring the table to be stored in an optimized way, all of which adds to the technical demands.
- More expensive than batch ingestion because it requires always-on infrastructure with autoscaling to handle data spikes, leading to higher complexity and operational costs
Hybrid Data Ingestion
The hybrid approach combines batch and streaming data ingestion methods. As shown in the diagram below, the workloads that need data at periodic intervals can use batch data ingestion, while time-sensitive workloads can leverage streaming data ingestion:
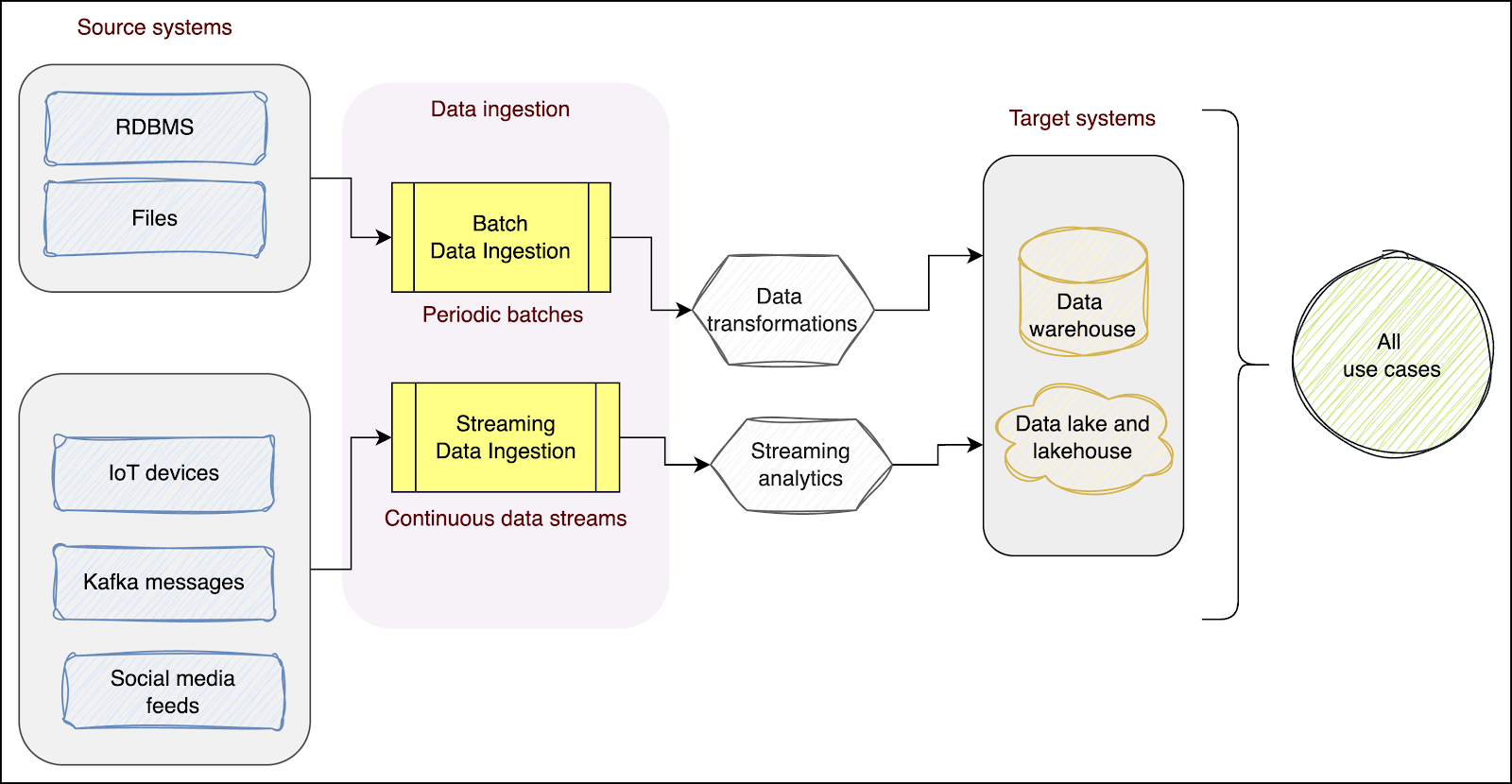
This combination of batch and real-time ingestion has been widely adopted by data-driven organizations that ingest data from diverse source systems and have batch as well as streaming requirements. It also enables architects to design a single codebase for batch and streaming data ingestion, which helps reduce implementation efforts.
It’s worth noting that hybrid data ingestion shares similarities with a Lambda architecture, especially when both batch and streaming pipelines operate on the same data source. In such cases, organizations often implement Lambda-like designs, where a streaming layer provides low-latency views while a batch layer ensures completeness and accuracy.
Use Cases
The hybrid approach best suits applications that need batch and real-time data. Some of its use cases are listed below:
- Organizations with a diverse set of source systems that can send batch (OLTP databases, files) and real-time (social media feeds, IoT sensors) data
- Businesses needing real-time insights as well as historical data for analytics
- Applications with future requirements for converting batch ingestion into real-time ingestion for agile decision-making or converting real-time ingestion into batch to save costs
Pros
The hybrid approach provides the best features from both worlds (batch and streaming):
- Can handle a diverse set of workloads that need periodic as well as real-time data
- Cost-effective and better utilization of resources
- Flexibility to switch between batch and streaming ingestion according to demand
Cons
Though the hybrid approach has the advantages of both batch and streaming, there are still some limitations:
- Implementing and managing a hybrid solution is more complex than separate batch or real-time approaches
- Any changes in source systems can impact both batch and streaming data pipelines (if they use a single codebase)
- When batch and streaming pipelines are built separately on the same data source, maintaining two different codebases can increase the risk of data mismatches, logic drift, and operational overhead which then requires frequent reconciliation. This challenge often emerges in Lambda-style architectures.
Key Considerations for Choosing the Right Approach
Cost is always a critical factor in selecting the right data ingestion approach for your use case, but other aspects such as data volume, velocity, business requirements, and scalability of your solution are equally important.
Cost Considerations
For many organizations, cost is the overarching factor that overrides all other constraints. As discussed earlier, streaming ingestion needs infrastructure that runs 24/7 as well as high-end configuration to reduce latency. It’s more costly than the infrastructure that supports batch ingestion.
Organizations needing real-time data but that have severe cost constraints can use batch ingestion with reduced intervals. They can execute batches every one to five minutes to ingest data as soon as possible. This will add a few minutes of latency, but you can avoid spinning up “always-on” high-end infrastructure, thus reducing the overall cost.
Organizations can optimize costs using a hybrid approach and implementing a unified batch and streaming code. The rule of thumb is to run ingestion in batch mode (micro-batches if required) and switch to real-time mode only for low latency requirements.
Data Velocity and Volume
Workloads with larger data volumes should use the batch approach. Applications that produce terabytes of data daily can ingest it into central data storage as multiple micro-batches. You should also consider using change data capture (CDC) logic to identify the incremental data changes (inserts or updates) that need to be ingested for every batch.
Streaming ingestion is a better approach for source systems that produce data at high velocities, such as social media feeds or IoT devices. It helps to quickly ingest the data as it gets generated at the source. An additional buffer, such as Apache KafkaTM, can be added between the source and ingestion process to ensure fault tolerance and replay capabilities.
The hybrid approach can leverage the batch and streaming techniques defined above to support high data volumes and high-velocity, low-latency use cases.
Business Requirements
Business requirements largely drive the decision to select a specific ingestion approach. For example, a batch approach is best suited for migrating historical data from your existing brownfield data warehouse to a new lakehouse, as you must run multiple migration cycles to copy the data. Ingesting such a large volume of data periodically also helps perform data reconciliation between batches and ensures data consistency before the next batch is executed.
Streaming ingestion is best suited for workloads that need time-sensitive streaming analytics. As data loses its value rapidly with time, such workloads need low-latency data ingestion pipelines that run continuously. Streaming ingestion can help you leverage data, generate insights quickly, and make agile decisions.
The hybrid approach combines batch and ingestion approaches and is ideal for businesses that have large volumes of historical data as well as time-sensitive data to be used for real-time decision-making.
Scalability
While selecting the ingestion approach, you should also consider the scalability of your solution. Data volumes can grow rapidly with time, and you should make provisions for future demands when designing the ingestion solution. You can build scalable batch and streaming ingestion solutions using an appropriate tech stack. Leveraging serverless/auto-scalable cloud services can help you handle spikes in data volumes.
A hybrid solution with a single codebase for batch and streaming ingestion is a good alternative for implementing highly scalable solutions. Depending on your requirements and data demands, you can run the same pipelines continuously or trigger them at scheduled intervals.
Data Ingestion Approach Overview
As you’ve seen, there are several factors that impact your decision to select the appropriate approach for your use case. Here’s a summary of the three different methods for quick reference:
Conclusion
You can use batch, streaming, or hybrid data ingestion approaches to copy data from multiple systems into your data platform. The batch approach helps you ingest data periodically, while streaming ingestion lets you ingest the data as soon as it’s generated by the source system with minimal lag.
As organizations continue to integrate and collect data from diverse source systems capable of sending batch and real-time data, it makes sense to adopt a hybrid approach consisting of batch and streaming ingestion. With open table formats becoming the preferred approach for building open lakehouse platforms, you can design a unified data ingestion framework for batch and streaming workloads by leveraging these technologies.
That’s where Onehouse comes in. Onehouse delivers a fully managed, open data lakehouse platform that unifies batch and streaming ingestion, including hybrid use cases, into a single framework. With OneFlow, connect to any source (including databases like Postgres, MySQL, and MongoDB; event streams like Kafka; and files in your cloud storage) and ingest data once into your own cloud buckets to query it anywhere (across Spark, Trino, Snowflake, Databricks, and beyond), with no re-ingestion or lock-in.
By combining incremental processing, intelligent autoscaling, and advanced table optimization, Onehouse helps organizations move data faster and reduce costs while maintaining the flexibility of open source formats.
Start your free test drive today and see how Onehouse and OneFlow make data ingestion faster, simpler, and more efficient.

Read More:




Subscribe to the Blog
Be the first to read new posts