Apache Hudi™ - The Open Data Lakehouse Platform We Need

It would be an understatement to say that this week was interesting. I happened to be in a medical procedure all morning Tuesday and was confused to see about 50 pings across all messenger apps when I came out. The Databricks + Tabular news had broken. Over the following days, I received various inquiries from friends, ex-colleagues, users, analysts and the press about Apache Hudi’s future and the overall landscape. So, it felt like a good time to share some candid thoughts.
In this blog, I focus on Apache Hudi with perspectives on the three Cs—Community, Competition and Cloud Vendors. This also feels like an excellent checkpoint to share some honest reflection and feedback, having seen the good/bad/ugly of the table format wars over the last few years. As a result, parts of the blog may not be to everyone’s liking, but I want to share some hard facts to help users understand how everything operates.
TL;DR: For the impatient, here are the takeaways
- Hudi is a grass-roots, open-source project, and the community is stronger than ever. The Hudi community has a proven track record of industry innovations, supporting some of the largest data lakes and cloud vendors for many years.
- Hudi is an open data lakehouse platform. Open table formats are essential, but we need open compute services for a no-lock-in data architecture. Minimizing Hudi to just a table format is an inaccurate and unfair characterization.
- Format standardization is essential but does not prevent the need to solve complex computer science problems related to data processing. Hudi is still better suited for the incremental workloads it is designed for.
- History often repeats itself. Hudi introduced the world’s first production data lakehouse with a new “headless” compute model that we have all grown to love. Users wanting to get behind innovative technologies early should recognize where innovation has come from historically.
- You don’t pay for open-source choices until you “pay” for them. If we genuinely desire openness, users must look past what vendors write or market and make educated decisions based on technical facts and business needs.
- Recognizing Hudi’s rightful place in the data ecosystem requires an understanding of both top-down vendor technology pushes and bottom-up open-source developer adoption. We continue to be constructive and collaborative, like how we kick-started the industry interoperability conversation by creating Onetable, now Apache XTable (Incubating).
- Next, we are hard at work bringing an open-source data lake database with radically improved storage and compute capabilities to market in the coming months.
Community
It goes without saying that Hudi is a very successful and impactful open-source project that has served many companies well for 7+ years now, managing multiple exabytes on the cloud. But given where we are and the artificial duopoly narrative created in the market, it’s good to see some data to gain perspectives.

Rest assured, Hudi is not resting on its laurels. It continues to thrive as an independent OSS community under the proven governance structure of the ASF. The next question to address is the mindshare for Hudi amongst practitioners. If we look beyond a 80/20 rule of how 80% of the market narrative is shaped by 20% influencers, we see that the quiet data practitioners continue to engage with the project for the value it offers. This is a clear indication of Hudi's relevance and future potential.
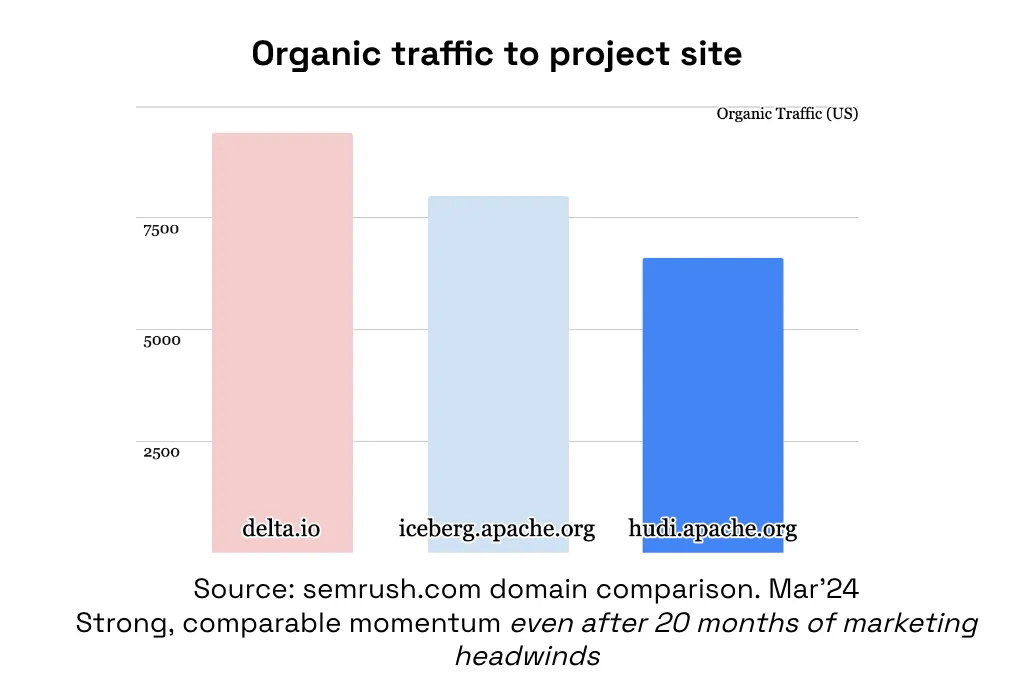
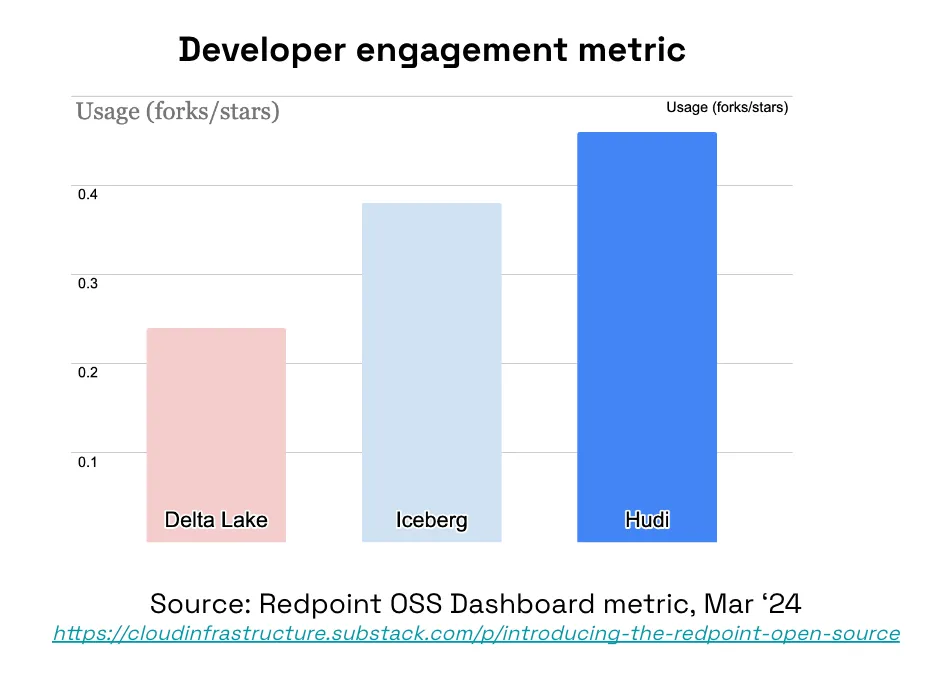
The community should take pride in Hudi's strength despite marketing dollars spent in other directions. A prevalent narrative spread by a few “pundits” and even vendors equates the lack of comparable “buzz” around Hudi within their world views to the extreme of a non-existent Hudi community. The historical data below paints a very different picture. In summary, the Hudi community is stronger than ever and will continue to innovate as long as the community wants it to be.
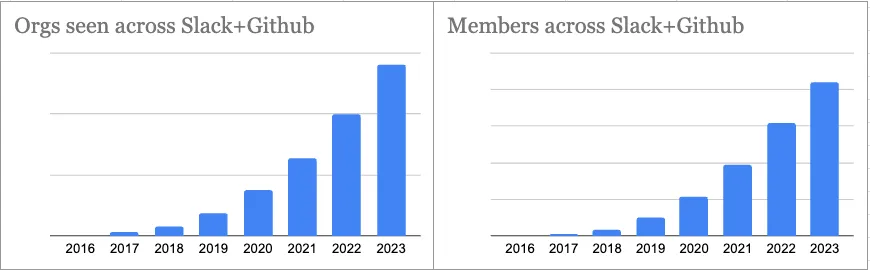
As I shared here, these narratives knowingly or unknowingly undermine the hard work of 450+ developers who have contributed over 1.5M lines of code to the project for just some cool fly-by comments. Not cool! I’ll stop here for now since this is not our primary focus, but unfortunately, this seems to be the stark reality of trying to build something independent in a large, noisy market.
How Hudi Fits into the Open Data Lakehouse
The recent move towards more interoperability and compatibility simply underscores a “format fallacy” that all we need in life is to simply agree on some data formats. We live in a time when openwashing has reached an editorial in the NY Times. This is where Hudi has philosophically differed, arguing as early as 2021 that the true power of openness is unlocked by an open platform that provides open options for all components of the data stack, including table optimization, ingest/ETL tools and catalog sync mechanisms. Open formats can help easily import/export/migrate your data in storage between vendors. But, without open services you are forced to pay vendors or build everything from scratch in-house. Sometimes, I am surprised to hear opinions like “Why is Hudi self-managing these tables. Shouldn’t a vendor do it?”. The honest answer is that I did not want our engineers to hand-tune 4000+ tables when we first went live at Uber. But, over the years, Hudi users have appreciated that they can submit a job, and it will write data and then manage the table in a self-contained fashion without mandating more scheduled background jobs. Open services bring real value to users out there, lower compute bills through proper data management as the “default” mode of operation.
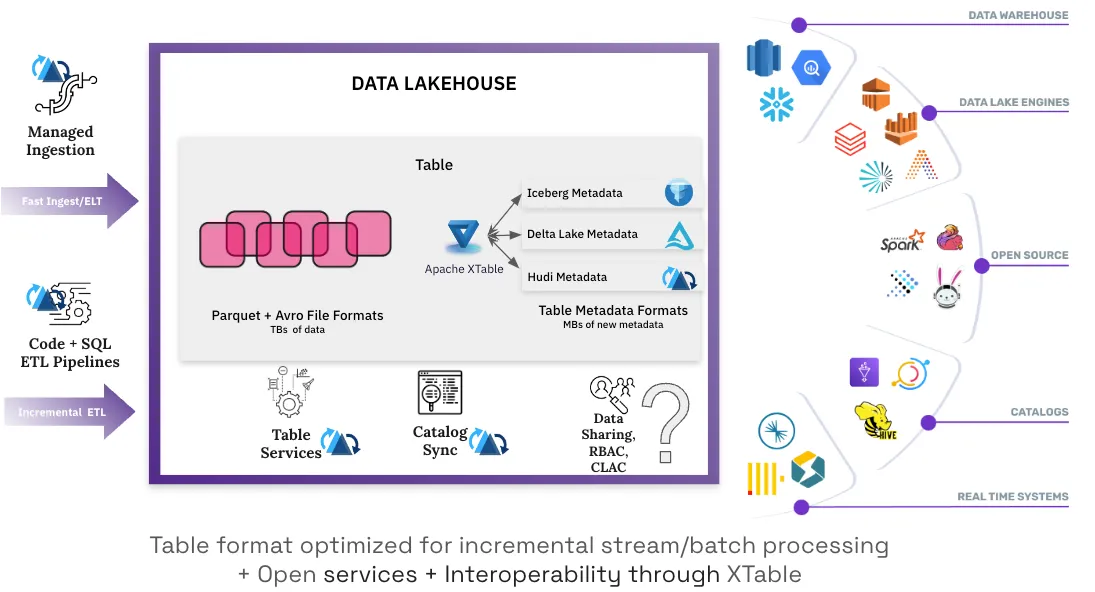
Such “open” compute services do eat into vendors’ potential commercial opportunities (including ours), but this is a better model for everyone to compete on creating the most value at the platform layer by making these automatic/intelligent/adaptive. The figure above illustrates how various parts of Hudi provide such a combination of open data/table formats and open data services. XTable provides critical interoperability to ensure the ecosystem does not fracture over table formats. As you can see, the big question in the stack and the lock-in hiding in plain sight is the catalog. We would love to collaborate with ours and other communities to bring to life a genuinely open, multi-format data catalog that is reimagined for this new world order.
But what’s technically different?
Openness is a first principle, but our technical vision has always been to “incrementalize data processing” for mainstream data warehouses and data lakes (now converging into a data lakehouse) with a powerful new storage layer and built-in data management. Users can then bring their own query engines/catalogs on top of Hudi to complete the stack. I have seen many users and even vendors confuse this with stream processing. No, we are not talking about processing streams stored in Kafka and emitting results back to Kafka! This is a fundamental rethinking of data warehouse/data lake ETL that can ease your cost or data latency problems. Even if you are not “concerned” about cost now, why do more when “less is more”? If some social proof helps, see this.
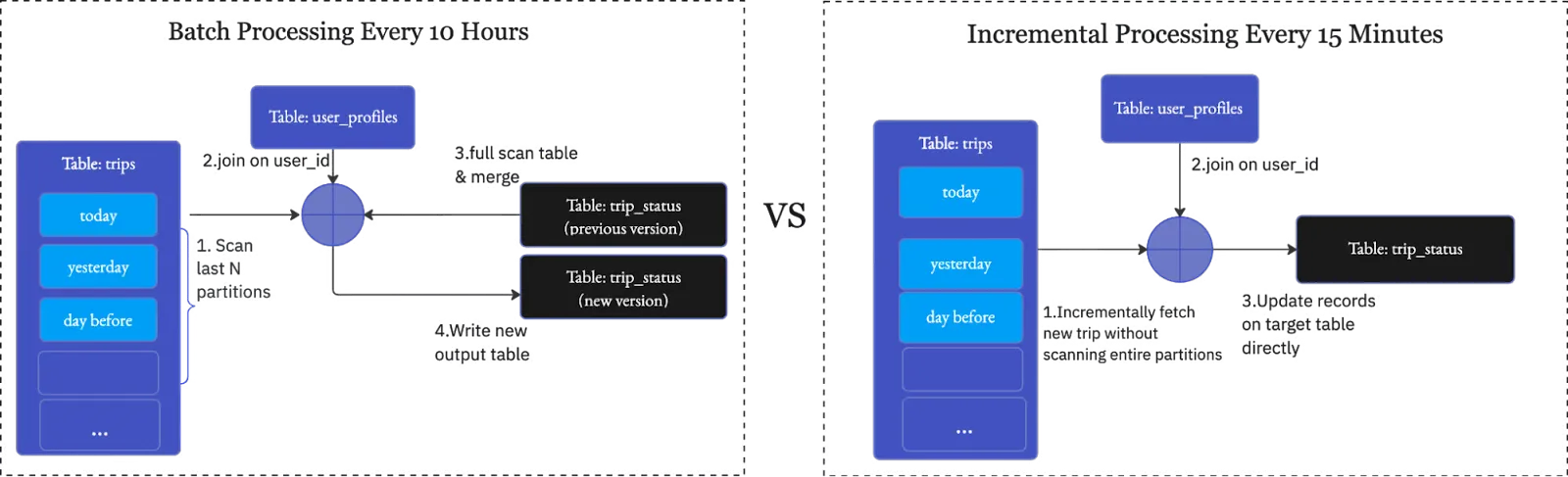
Let's revisit the concept of incremental data processing. It's a strategy that optimizes your regular ETL jobs by reducing the data processed in each run. This is achieved by scanning less input through record change tracking and writing less output by updating records. This AWS lab provides a comprehensive example of this transition from batch to incremental model. Our unique features and design choices, which have stood the test of time, are a testament to the effectiveness of this approach.
- Record-level metadata that preserves change history efficiently extracts records that changed after a point in time without having to retain all historical table metadata.
- Tracking table metadata as a change log instead of a snapshot to limit active metadata to a fixed size, even for enormous table sizes.
- Support about half a dozen indexes under a pluggable indexing module to facilitate efficient/fast mutations to the table.
- Intelligently mixing row and column-oriented data formats to balance write vs. read amplification and scans vs point lookups.
- Table metadata and other indexes are implemented as another Hudi table to scale proportionally to the table’s scale.
- Grouping records into file groups to control the amount of data read during merge-on-read queries.
- Logging updates instead of turning them into deletes and inserts can affect the temporal locality of data and degrade query performance.
- Built-in table & metadata management such that frequent updates to data/metadata do not degrade query performance.
- Careful coordination between writers and table services to maximize concurrent non-blocking operations, where writers need not be taken “offline” for table maintenance.
- Platform tools for ingestion and incremental ETL that package writers, table services, catalog interactions, etc., to ease the path to production.
Okay, so is Hudi just for this niche incremental processing use case? No again! While Hudi’s storage and concurrency models are specialized to uniquely support incremental reads/writes, Hudi supports all regular batch processing primitives needs for “slow-moving data” as well. Strictly speaking, Hudi offers a superset of functionality across regular batch and incremental processing, with an ambitious technical vision to make all processing incremental one day. In the medallion architecture terms, we routinely see users move ultimately towards the incremental model for bronze/silver layer data pipelines. At the same time, engines like Apache Flink™ can unlock end-end incremental processing for the Gold layer. So, this is not some far-away pipe dream but a reality unfolding now and driving Hudi’s growth through these times.
Results (1, 2) from the community have been very impressive, and there is no good reason not to consider lakehouse storage supporting the incremental model, even if you are just batch processing today. This deserves more elaboration, but I hope you appreciate that it is orthogonal to designing a standard table file listing and statistics representation. Again, XTable brings such interoperability for Hudi with batch table formats (if that helps internalize it more) to leverage work on those fronts.
Understanding Hudi in the Cloud Ecosystem
I often hear from the scores of engineers I interact with, "Data space is confusing,” or “There are so many terms.” It’s beyond my mortal abilities to fully explain all this, but here, I will try to shed some light on why/how the Cloud ecosystem supports/does not support, talks/does not talk about Hudi. As noted here, all major warehouses and lake query engines support reading Hudi tables “natively” except for Snowflake and Azure Synapse. For writing tables, the Hudi community heavily invests in Apache Spark™, Apache Flink, and Apache Kafka™ Connect, given that they represent the lion’s share of ETL pipelines written on the data lakehouse. Also, the technical capabilities of these frameworks help us implement a highly performant and feature-rich write path, e.g., shuffling/repartitioning to help implement indexing or running some maintenance inline. Although very feasible, it is relatively little more involved for engine vendors/maintainers to implement such a write path by themselves.
The community can add support on open-source query engines like Apache Spark, Apache Flink, Presto, Starrocks, Doris, Trino and Apache Hive by directly contributing pull requests to maintain these integrations. Cloud warehouses are a different story since they all (at least as of this writing) default to their proprietary data formats while parallelly adopting open data formats. Cloud warehouse engines themselves are still closed, and there is no way for an OSS community to contribute support. This creates a situation where warehouses typically make concentrated bets on one of the formats for practical resource constraints. However, broader support for XTable helps by leveraging the support for just one format (e.g., Iceberg in Snowflake) to bring open data in other formats to the warehouse engine without sacrificing the Hudi/Delta Lake writer side capabilities.
Now that we understand the technical considerations let me share how it all comes together on your phone and computer screens. When marketing teams go about their routine business, the narrative of “we support x” is interpreted by the market broadly as “we don’t support y and z,” or even “y and z aren’t good since x is supported.” In the case of Hudi, this is further amplified by the sheer magnitude of vendors present and the market size to a point where the voice of innovation from a much smaller open-source community gets trampled on. If you want Hudi supported on an engine, just ask your vendor if they can do so. As the founder of Onehouse, we collaborate with all query engine vendors equally in the space to bring truly open data lakehouses to users. But, in technical terms, the ability to use Hudi is not necessarily gated on any vendor’s support, thanks to open columnar file formats, open table formats and XTable.
How can this be easier? Spark-based platforms like Databricks, EMR, DataProc and Fabric have unlocked a much more open model that lets us innovate at speed without users having to wait 1-2 years for format support from a proprietary vendor. Open data formats are the default on such platforms, and users can extend the platform easily to read/write a new source if they possess the engineering resources to do so. It would be a fantastic world to live in where cloud warehouses can also be extended by users, after all, it is your data.
Why you can rely on Hudi
An important consideration for users has been ensuring their technology choices come with the required support structure. It’s important to internalize what “support” means, given the actual technology advancements in data lakehouse space come from 3 open-source communities and are not spread uniformly across the industry. Hudi has been supported and well-integrated into about five public cloud providers for many years. If support means “getting help,” the community has helped resolve over 2500+ support tickets for its users during the project’s existence, and the Slack community has ~20 minutes of median response time over the last six months. Over the years, Hudi committers have also helped solve many production issues for cloud vendor customer escalations for free in the spirit of community. I believe a self-sustaining open-source community is the best long-term solution here.
Second. Hudi adopts a community-first, user-centric approach to open source under the watchful eyes of the Apache Software Foundation. Sometimes, the value of having something is only apparent when you don’t have it. Go here if you are curious about how fast self-proclaimed OSS foundations outside the likes of ASF or Linux Foundation can evaporate. If you are using open-source technology in a business-critical way without good neutral governance, you should think very hard.
Finally, Hudi is already relied on by some of the largest data lakes in the world. Your team can also have an outsized impact on the industry by contributing and being a valuable community member. Relying on open-source software does require more effort than paying a vendor for all your troubles. But embracing open source and aligning closer to cutting-edge innovation is the inevitable future ahead of us.
Our Vision for Hudi.
Late last year, we put together a bold vision for the future of Hudi 1.x, with exciting changes across the stack, the introduction of new capabilities and the addition of new components to package Hudi more as a database, in addition to (not instead of) being a library that is embedded into data processing frameworks and query engines. The community is taking the time needed to get this right while supporting the 0.X release line with more features. This is not a new notion, but what we believed users needed from the get-go. However, the ecosystem support required more, and the user expectations around data lakes insisted only on support within jobs and existing catalogs. With the convergence into the data lakehouse now unanimously agreed upon, we think its a better time to revive this vision and bring it to life with even more value given all the new developments since - more mature SQL lake engines, broad consensus around data interoperability, warehouses supporting open data formats, the increased need for unstructured data, faster cloud storage and more.

Figure: Slide from Spark Summit 2017 “Incremental Processing on Large Analytical Datasets”
This longer-term vision for Hudi would diverge from other projects, bringing Hudi closer to an open version of a cloud warehouse/lakehouse. Using this architecture from Snowflake as a reference, we would have a similar model where Hudi maintains its open metadata/data optimized for features supported natively within Hudi while ensuring portability to Iceberg/Delta for interoperability. Regarding what may be in store for future interoperability and unifying table formats, we have been willing to consistently work across the aisle (e.g., we helped with Delta Uniform support for Hudi while driving XTable). To the extent technically possible and community willing, we will try to align with Databricks’ lead towards unifying the 2/3 of the open table formats by exploring a mode in Hudi where it writes iceberg/delta storage compatible files/metadata at potential loss of functionality and performance for incremental workloads. The shared goal is to have more power and choices for the users.
Conclusion
I hope this blog provides a more balanced view of Hudi for open-source users, which is more critical than what vendors think (including Onehouse). Data lakehouses are still a very “spicy” topic. You will continue to see data enthusiasts entertain themselves with posts like “R.I.P Hudi” or speculating what Snowflake/Databricks will do next. You will see a few expert op-eds playing out doomsday scenarios, completely ignoring that the open-source user influences what happens next. My earnest suggestion is to take things at face value and do what will help your projects and meet your company’s data goals. The Hudi community is here to work together with you!
We will be at the Databricks Summit next week. If you want to explore the thoughts expressed in this blog further, catch our talks on XTable or the Universal Data Lakehouse or swing by our booth.
Read More:






Subscribe to the Blog
Be the first to read new posts