Introducing Onehouse OneFlow: Ingest once, query anywhere
Intro
In the hot data conference season this year, two topics captured the minds of the data world: AI (of course) and the perennial issue everyone thinks they’ve solved, but continues to plague us year after year—data ingestion. While AI & LLMs grab the spotlight, data ingestion is the critical first step in everything from AI to analytics workflows.
Last month, Snowflake introduced their new data ingestion solution, OpenFlow. Confluent and Databricks also announced general availability of their ingestion solutions, TableFlow and LakeFlow, over the past months. After all these announcements, the data must certainly be flowing!
While these products aim to make ingestion easy, most vendors are solving ingestion specifically for their own ecosystems. Snowflake’s OpenFlow and Databricks’s LakeFlow can bring data into their own platforms, but require that you use their storage, catalog, and query engine. Confluent’s TableFlow only works if you’re using their flavor of Kafka to capture every data source.
These gated approaches might work at first, but they quickly become a bottleneck as your architecture evolves. For the ~45% of teams using both Snowflake and Databricks—will you really manage duplicate ingestion pipelines in both OpenFlow and LakeFlow? And when your team wants to migrate to open engines like Trino or ClickHouse, do you want to re-ingest all your data just to switch platforms?
We’ve seen this firsthand with customers like Conductor, who cut costs by moving off their warehouse to an open architecture, enabling them to query data with StarRocks, Trino, and any engine they choose to bring in the future.
When ingestion ties you to a single storage layer and engine, every pipeline becomes technical debt.
Introducing OneFlow: The universal ingestion platform for open lakehouses
Turns out, we had already built the solution long before these summer announcements. Given these gaps in the market, we are excited to reintroduce our managed ingestion solution as OneFlow, the one-stop ingestion platform purpose-built for open lakehouse architectures.
OneFlow ingests data directly into your cloud storage buckets, stores data in your format(s) of choice, and syncs to all your catalogs, so you can ingest once and query anywhere.
Built for modern lakehouse ingestion, OneFlow delivers:
- Accelerated pipelines at lower cost with record-level indexing and incremental processing that minimize write costs and compute waste
- Low-latency, high-scale database CDC by ingesting updates and late-arriving data with industry-leading efficiency for the data lakehouse through indexes and merge on read
- Fast, elastic ingestion under high-volume pressure using dynamic autoscaling and lag-aware execution to meet tight freshness SLAs from our compute runtime
- Smarter cost control and observability with per-table usage tracking, throttling, and performance profiles for tuning speed vs. spend
- High-performing tables with automated compaction, clustering, and cleaning — all running asynchronously, without bottlenecking ingestion
- Universal query flexibility by writing to all open table/file formats and syncing to any catalog — no re-ingest, no vendor lock-in
With OneFlow, you ingest once and query anywhere — across open engines (e.g. Trino, Spark, Ray), or any commercial engines (e.g. Snowflake, Databricks, BigQuery) of your choice.

OneFlow wasn’t built in a vacuum — we’ve seen what breaks in real-world ingestion pipelines from years of experience operating data lakehouses at scale. The rest of this post breaks down the most common ingestion pain points and shows how OneFlow addresses them head-on.
Monitoring Data Quality & Schema Evolution
Source schemas change, sometimes without warning. A new column appears, a type is modified, or a team silently changes their export process. Suddenly, dashboards are broken, ML models drift, and nobody knows if the underlying data is still reliable.
The problem is exacerbated if you don’t catch data quality issues early, allowing bad data to propagate across data layers and downstream systems.
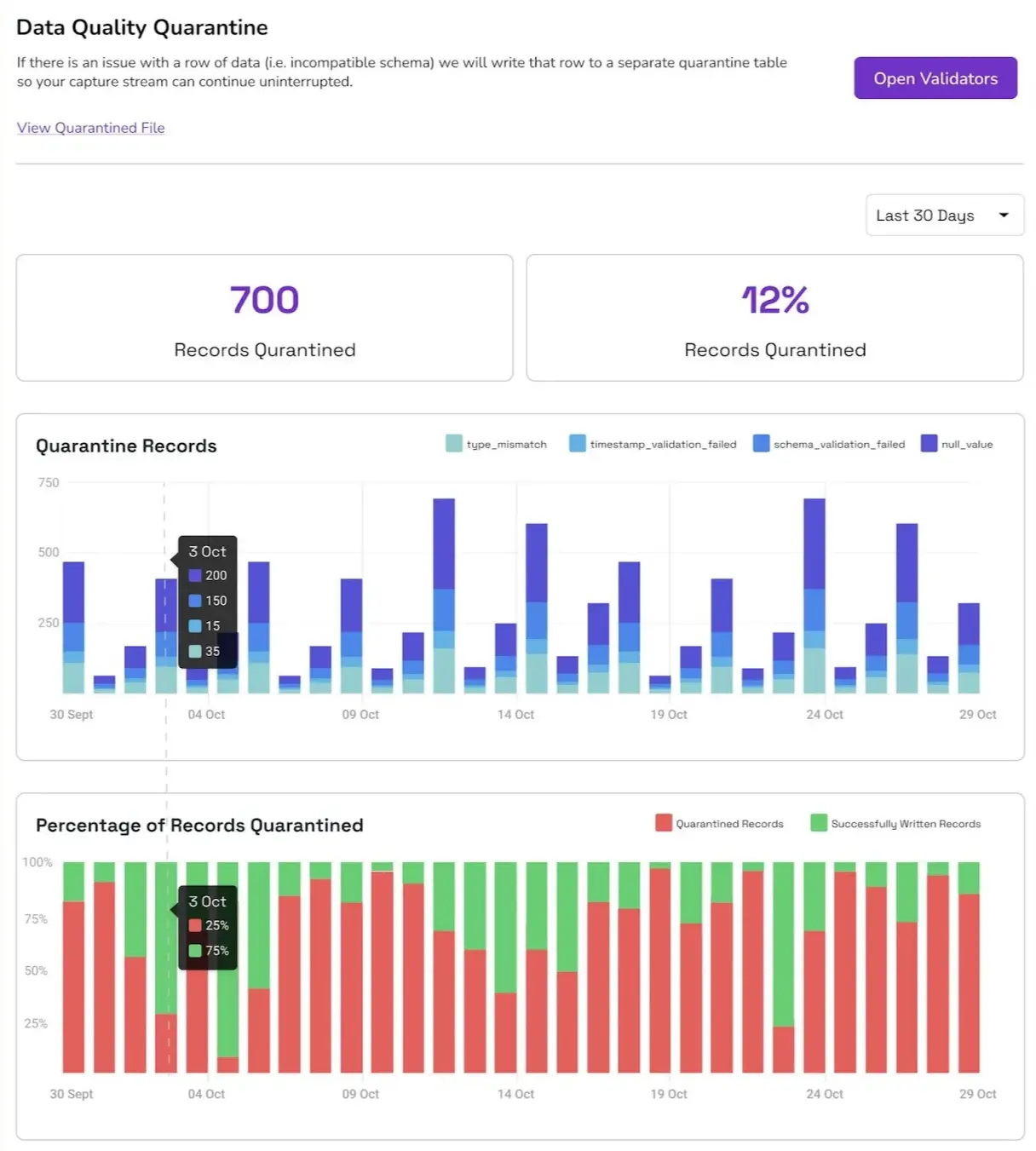
OneFlow solves the challenge of bad data. You can apply data quality validations directly in your pipelines to quarantine bad records into separate tables without disrupting ingestion. These capabilities come with rich observability dashboards to help you monitor quarantined records in real time.
OneFlow also supports backward-compatible schema evolution to handle changes gracefully without corrupting tables or failing pipelines. Read more on this in our data quality blog.
Optimizing Speed and Handling Lag
Ingesting from streaming sources like Kafka comes with real-time pressure. If your pipelines fall behind, the source might evict data, and now it’s gone forever. Even small lags can result in stale dashboards, broken SLAs, and teams making decisions on outdated data.
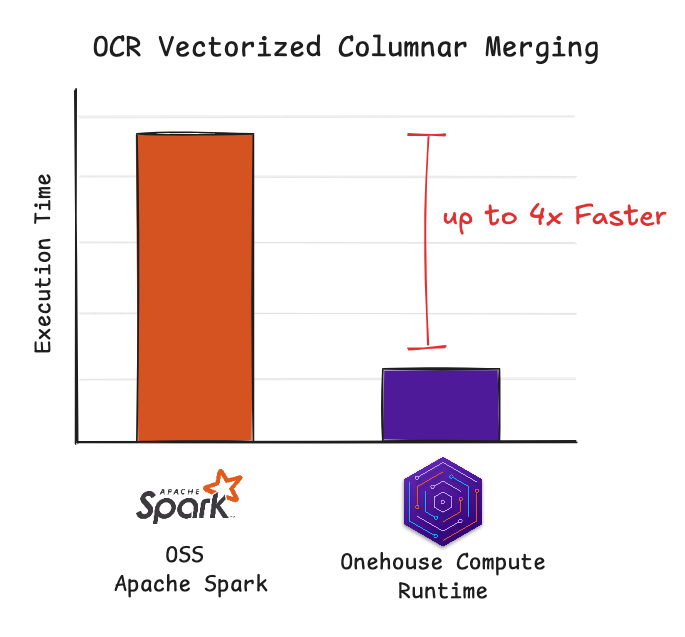
OneFlow accelerates your ingestion pipeline to ease that backpressure from building up in the first place. Under the hood, OneFlow is powered by our Quanton engine, which leverages techniques like advanced indexes and vectorized columnar merging to greatly speed up your pipelines.
Furthermore, OneFlow gives you the tools you need to prevent lag through performance profiles and lag-aware execution. Performance profiles let you optimize ingestion for speed or efficiency, depending on the needs of downstream consumers. Lag-aware execution adapts how jobs are scheduled and resourced to help you stay within latency SLAs, even as workloads spike.
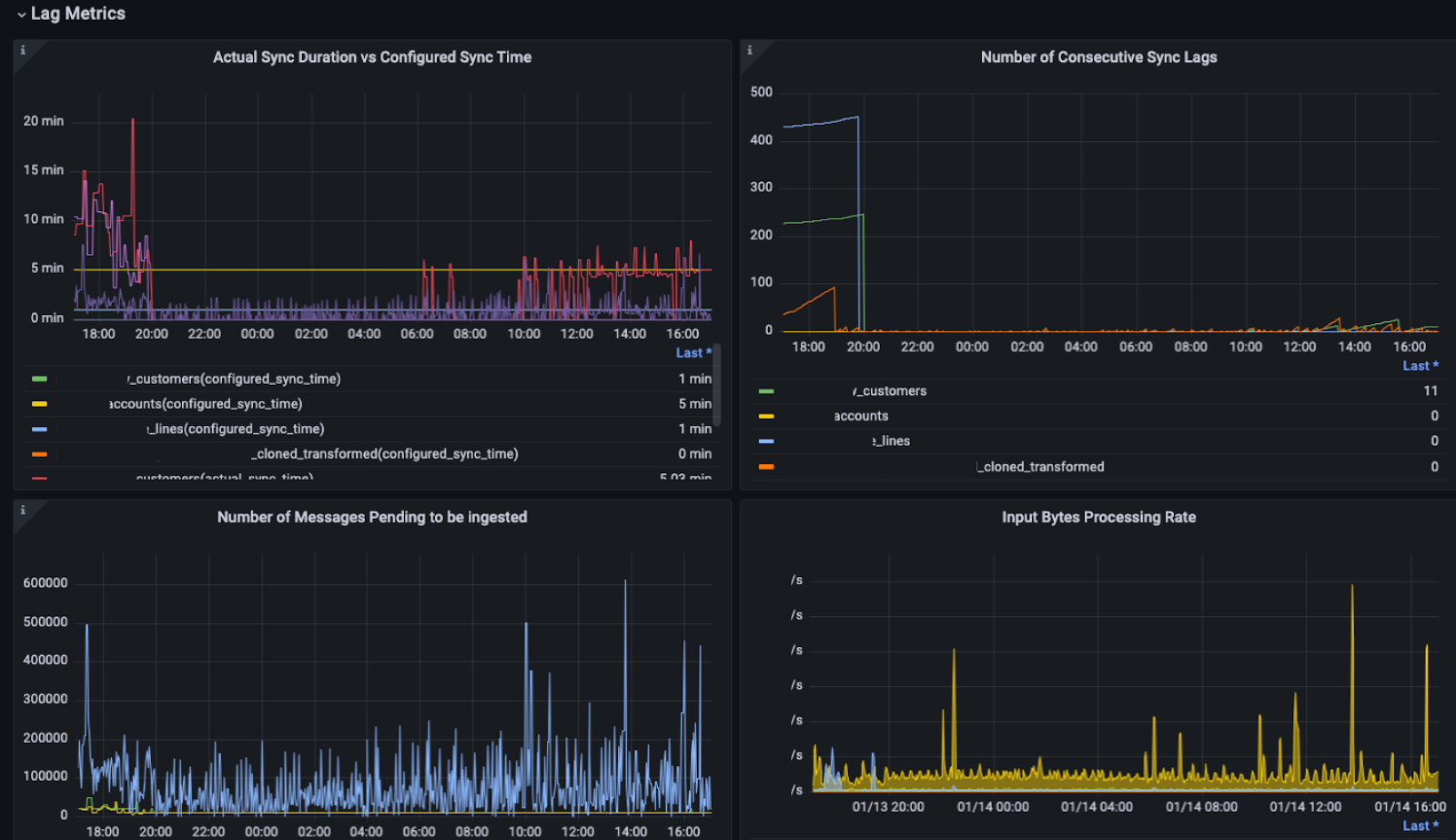
Lastly, you get a birds-eye view into your pipelines with detailed metrics and monitoring dashboards that surface the information you need to get your pipelines running at the target latency.
Controlling Costs
Ingestion is often more expensive than it looks. Spark-based ingestion jobs tend to over-provision drivers and executors, even when processing just a few records. At the same time, SaaS ingestion vendors charge you for every row and every replication — even across the same dataset.
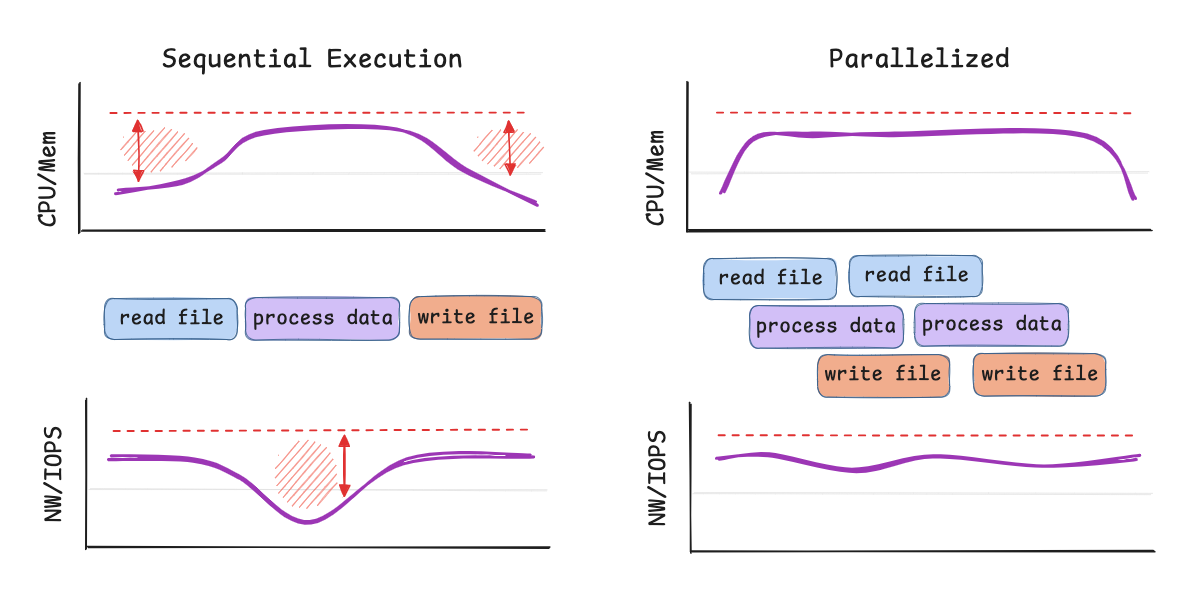
OneFlow helps keep your compute footprint and costs low through parallel pipelined execution, which maximizes throughput across many concurrent pipelines, and dynamic compute scaling that adjusts resources in real time based on workload needs.
We saw this in action with a customer ingesting large volumes of update-heavy blockchain data. They needed to meet a strict 10-minute SLA for data freshness, even as their workload spiked 100x throughout the day. Spark’s default autoscaler couldn’t keep up — it scaled too slowly during spikes and failed to downscale effectively, leading to inflated costs. With OneFlow’s dynamic scaling, the customer was able to react quickly to workload surges, maintain consistent latencies, and significantly reduce costs.
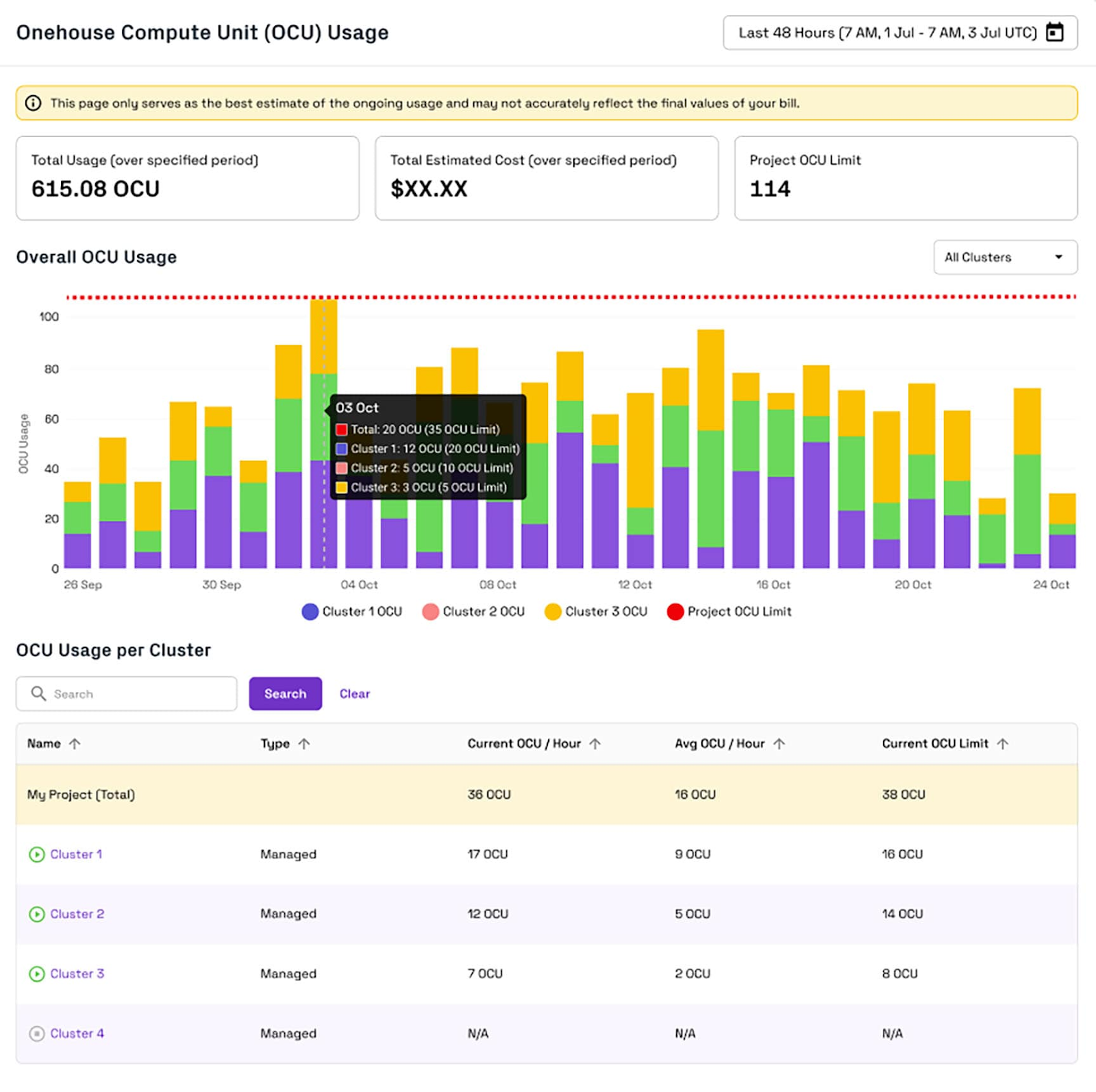
For teams running diverse workloads, cluster isolation and resource limits give you precise control over ingestion throughput — whether you need to throttle or accelerate pipelines. OneFlow pairs this with cost observability dashboards, offering per-table usage tracking so you can set smart limits and quickly identify high-cost pipelines.
Late Arriving & Mutable Data
The lakehouse is built on immutable storage. That’s great for scale and cost, but it means handling updates and late-arriving records is harder than in traditional databases or warehouses.
While most lakehouse storage formats and platforms involve costly data rewrites when records are updated, OneFlow leverages a Merge on Read approach to minimize data rewrites and efficiently handle updates or late arriving events. Index-based incremental processing further reduces write amplification, ensuring you only write the data that’s changed.
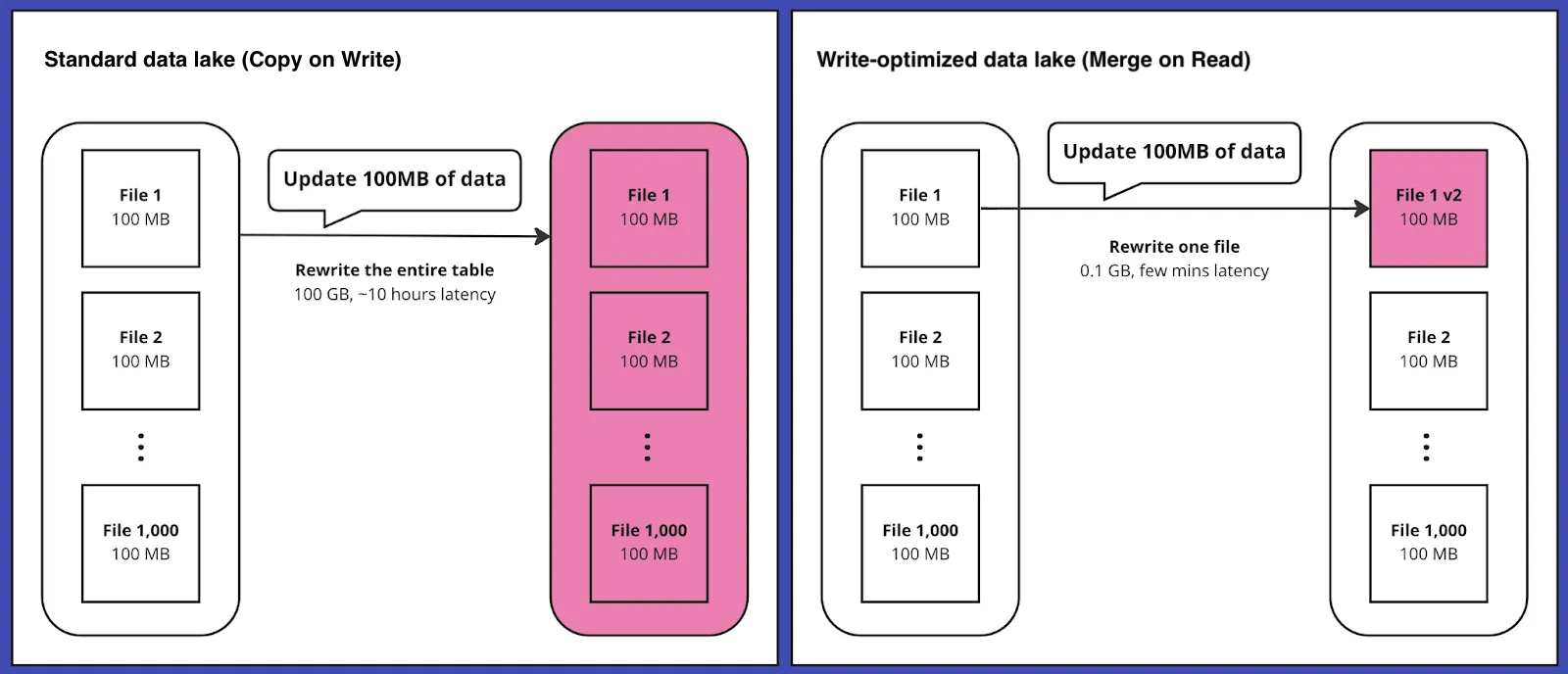
Merge on read and incremental processing minimize data rewrites and write amplification.
Raw Data Cleaning & Transformation
In many pipelines, raw data lands first, then gets transformed later. This pattern creates multiple copies of the same data, burns extra compute, and slows down time to insight. Writing transformation logic in code adds more friction, making it harder for teams to quickly land usable data.
With OneFlow, you can transform data in-flight — clean, model, and write directly to object storage in a single step. Define transformations using low-code configs or custom code, depending on your needs. Whether you’re flattening nested schemas, standardizing types, or applying business logic, OneFlow makes it easy to rapidly build out your medallion architecture.
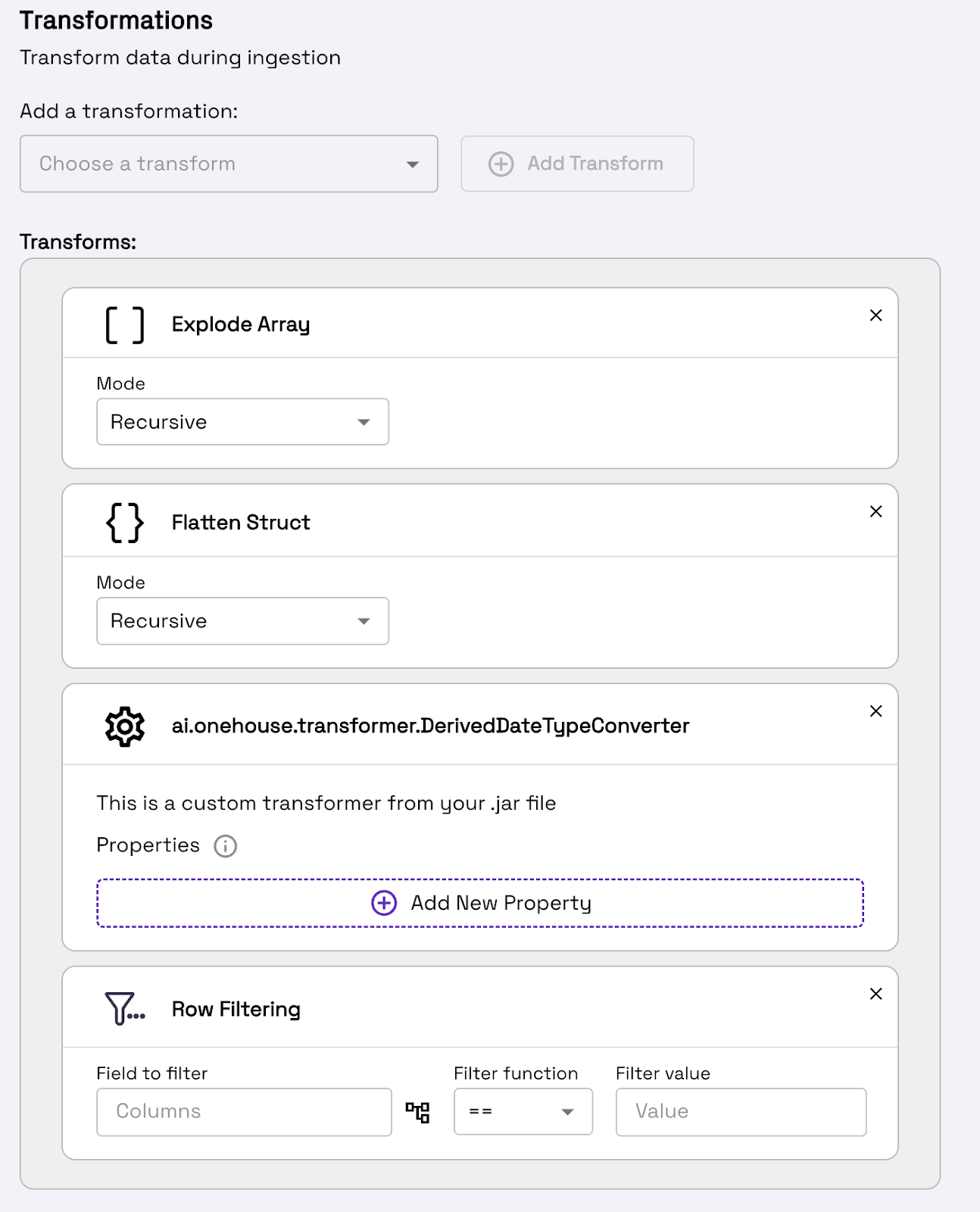
Table Maintenance & Optimization
Unlike data warehouses, lakehouse tables need to be explicitly optimized. Without active management of file sizes, compaction, and sorting, query performance quickly degrades as data grows.
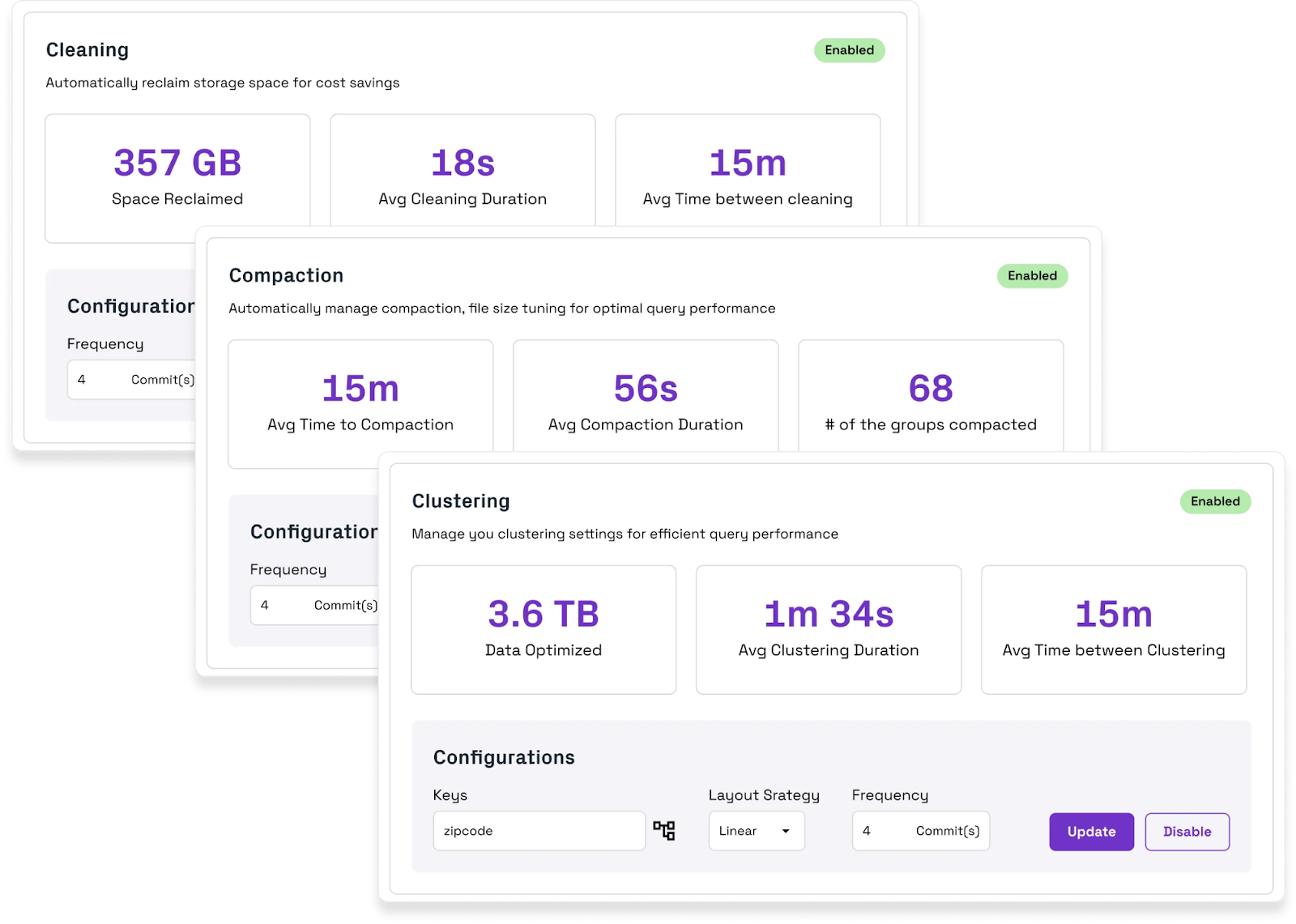
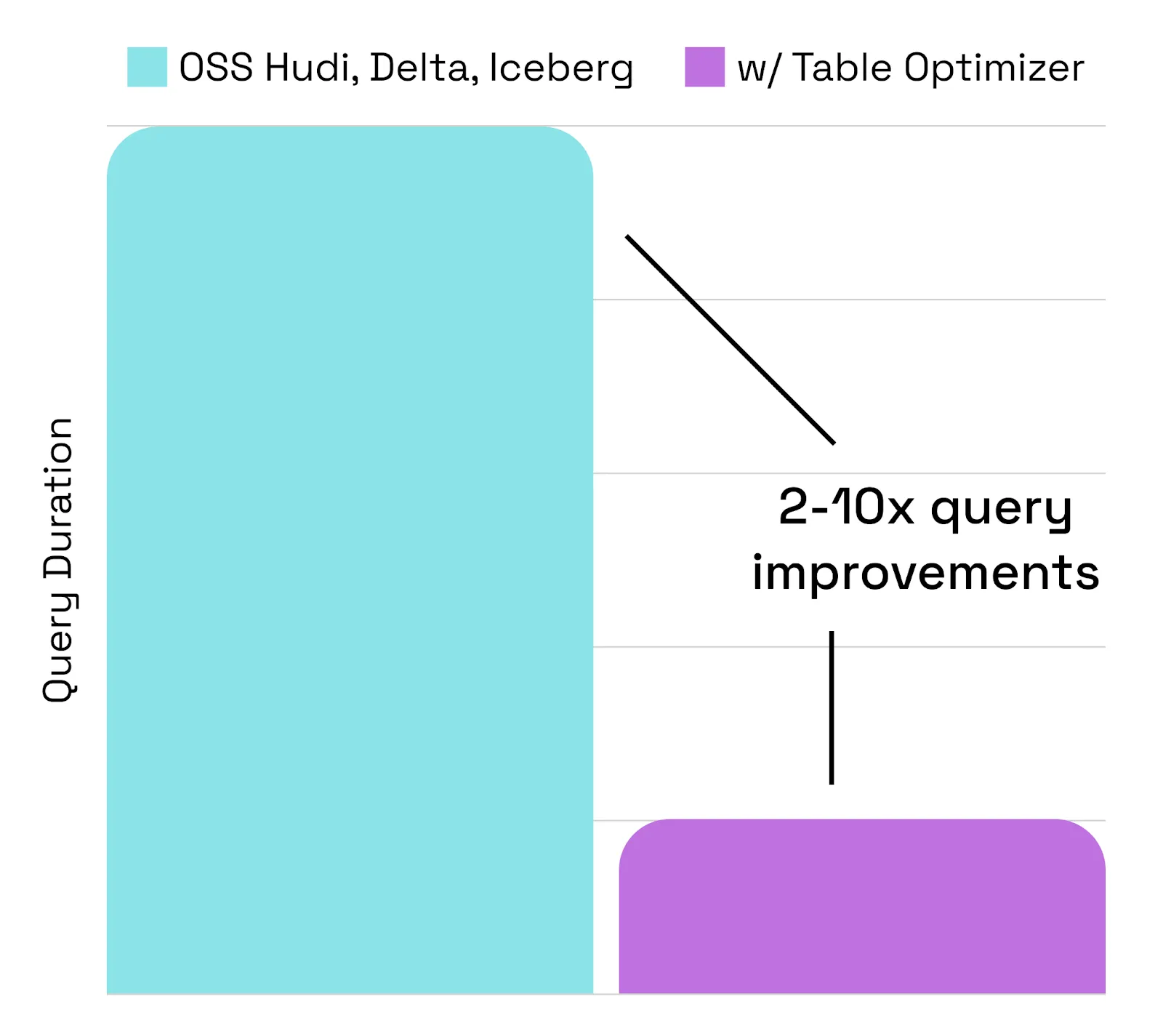
OneFlow automates these table services behind the scenes, so you get fast, optimized tables without the maintenance burden. The Onehouse Table Optimizer runs asynchronously, meaning it works in parallel with ingestion, avoiding the bottlenecks that often slow down lakehouse pipelines.
These automated services include:
- Small file compaction and advanced file sorting to boost query performance
- Cleanup of unused files to reclaim storage and reduce costs
- Advanced indexing, such as record-level indexes, to speed up pipelines and minimize write amplification
Vendor Lock-In
Most ingestion tools tie your data to a single destination. You ingest once, but now you’re stuck within that tool. Want to switch query engines or run AI workloads elsewhere? Time to re-ingest and rebuild.
OneFlow takes a fundamentally different approach, allowing you to store data in any open table format and sync to multiple catalogs, so you can query data across AWS Glue, Unity Catalog, Snowflake, Apache Polaris, and more.
OneFlow always processes and stores data in your VPC, so you stay in control. Data is never locked into the ingestion system itself, and you’ll never have to migrate it off a SaaS vendor’s cloud. With OneFlow, your data is always yours—from ingest to insight.

Conclusion
Ingestion should help you deliver data for all your use cases, not be a gatekeeper. But most solutions today lock you into a single ecosystem, forcing you to use their storage, their catalog, and their engine. The result: expensive rework, rigid architectures, and pipelines that break when your team wants to expand into new use cases.
OneFlow flips the script. It is ingestion built for the open lakehouse, where you stay in control. Your data lands in your cloud storage, in the formats you choose, registered to the catalogs you use — ready for analytics, AI, or warehousing in whatever engine you prefer.
Whether your goal is to solve data quality issues, hit latency SLAs, or maximize cost/performance, OneFlow helps you build fast, flexible pipelines that scale — all without getting boxed into a vendor’s stack.
If you’re building a data lakehouse, or looking to escape the high cost of warehouse-bound ingestion tools, get in touch. We’d love to see how we can help.


.webp)
Read More:






Subscribe to the Blog
Be the first to read new posts