View our lakehouse webinar on YouTube


This blog post is a brief summary of the Hudi Live Event titled Notion's Journey Through Different Stages of Data Scale, delivered by Thomas Chow and Nathan Louie, software engineers on the Notion Data Platform team, on December 13th, 2023. The video clip below gives a brief summary of Notion's presentation. You can also check out the talk slides or view the full talk.
Thomas Chow and Nathan Louie, software engineers on Notion’s Data Platform team, described how they have upgraded their data infrastructure as data scale and demands on data have rapidly escalated. Data under management has grown by 10x in just three years; a data snapshot today is tens of terabytes, compressed, and active data is hundreds of terabytes in size. Their new and improved data architecture is yielding significant cost savings and unlocking critical product and analytics use cases, including Notion’s latest, game-changing generative AI-based features.
Chow, whose focus is on batch processing and data lake ecosystems at Notion, kicked off the talk by explaining the complexity of Notion’s data model. As a collaborative documents product, Notion has a data model where “everything…is a Block.” All these Blocks have a similar data model and schema on the backend, where the metadata about the Block fits into the same structure across different Block types. However, these similar-seeming Blocks can render into wildly different user interface components, giving Notion the flexibility and extensibility that it is known and loved for by its end users. See Figure 1 for an example.

The challenge with Blocks is the scale of the data they represent: Notion has a data doubling rate of six months to a year. This is staggering, especially considering the starting point, a few tens of billions of blocks. Not only has the scale of data increased rapidly - the demands on data have increased as well. As a result, Notion had to innovate and evolve their data infrastructure, and they managed to do so over a relatively short period, beginning just three years ago.
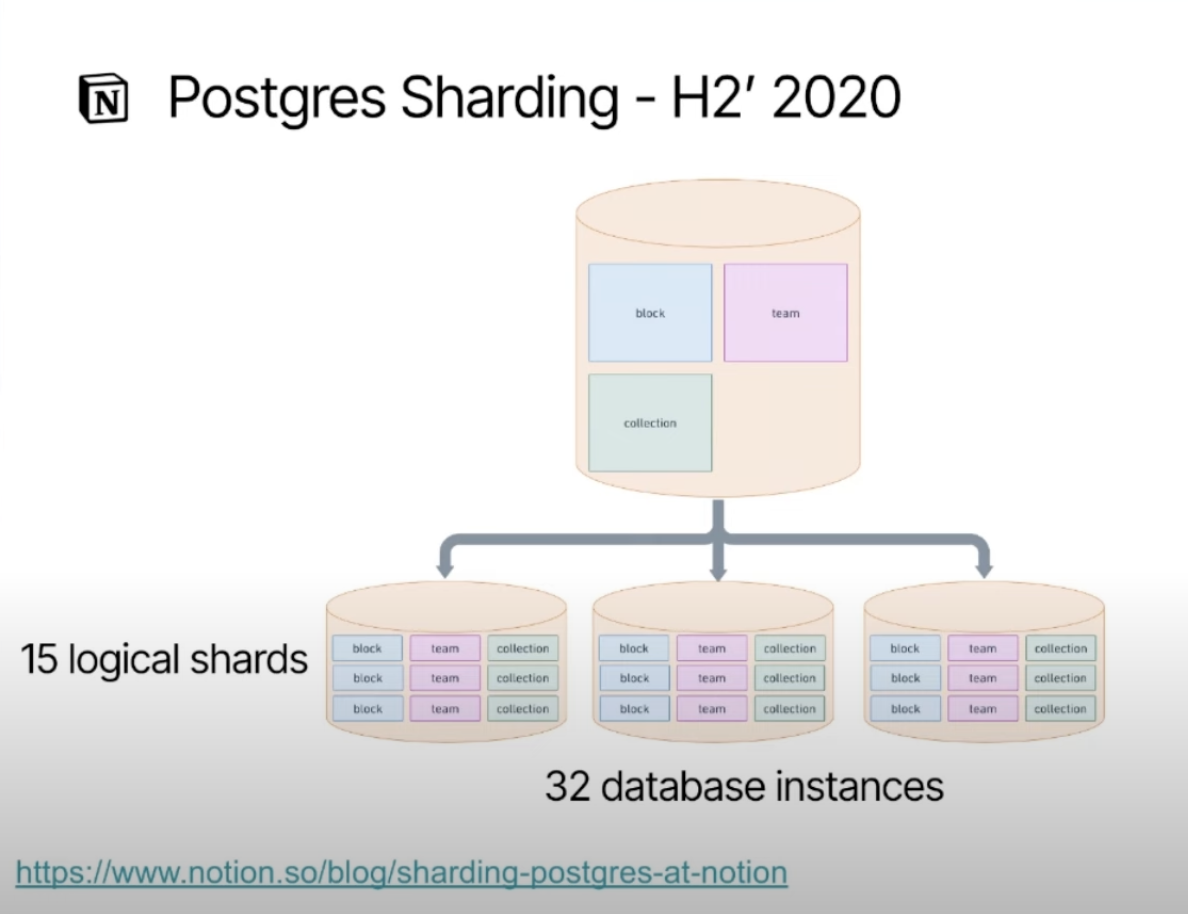
Before 2022, the entirety of Notion’s data infrastructure relied on a single PostgreSQL database system, as shown in Figure 2. It was core to everything at the company, from support for the live product to analytics. And it was an efficient solution for the early days. But as the company grew (and data size, transaction volumes, and related metrics continued to double), the team started to reach the limits of this configuration.

This prompted a shift from a single Postgres table to 15 logical shards, as shown in Figure 3—a significant leap for Notion’s data infrastructure. So significant, in fact, that it merited a blog post from the infrastructure team.
Sharding helped distribute the data load but also complicated the data architecture, requiring more sophisticated data management and querying strategies, particularly for moving data into a data warehouse.
At around this time, the Notion team adopted Snowflake as a data warehouse to support their analytics and reporting needs, as well as increasing needs around machine learning. They wanted to support these use cases at their data’s growing scale without overwhelming the Postgres databases serving the live product. To do so, they mirrored the sharded database’s format in their extract, transform, and load (ETL) pipeline. In the ETL pipeline, Postgres data would be ingested via Fivetran into Snowflake, which was used as the data warehouse. But as the data scale in this pipeline grew, so did the problems.
At the first stage of the ETL pipeline, the team found that they were running out of memory and were having issues handling bursts of volume. These bursts occurred frequently due to the way users interacted with Notion, which was anything but uniform throughout the day. And, explained Thomas, “Fivetran is a [closed source] third-party product, so there were few knobs we could actually tune” to deal with frequent changes in Block update volume.
Loading data into Snowflake was challenging too, both because of how long the loads took and how expensive they were. Given that the syncs were happening hourly, the fact that they sometimes took more than an hour, often bleeding into the next sync cycle, was painful.
As the team dug in to try and find a solution to these scaling pains, they saw a pattern that might offer a clue. They noticed that only about 1% of Blocks were being upserted (the operation to update a record, or insert it if the record does not yet exist). So, as is often the case, the total upsert volume was actually quite small compared to the size of the table, as shown in Figure 4. It was seeing this pattern that motivated the Notion team to move towards a universal data lakehouse architecture that would better support this observed update pattern.

The team had several architecture options at the time - Apache Hudi, Apache Iceberg, and Delta Lake, the open source version of the internal Delta lakehouse architecture used at Databricks. After careful analysis, they chose Hudi. Thomas cited a few of the reasons that the team made the call:
After making the decision to adopt Hudi, Notion overhauled their data lake infrastructure to make use of it. The new infrastructure ingests data from Postgres into Debezium CDC, which is piped through Kafka, where it is then fed to Hudi for batch incremental updates against Hudi datasets, and finally gets pushed downstream to Apache Spark pipelines to do ETL, as shown in Figure 5. And, alongside overhauling their infrastructure for large datasets, the Notion team also kept the previous Postgres, Fivetran, and Snowflake pipeline from before for smaller data sets and third-party data sources.

The payoff of implementing the new universal lakehouse architecture was significant. Right off the bat, the team garnered a savings of more than a million dollars a year, due to the massively increased performance of the entire system - in particular, replacing the previously slow and expensive data loads into Snowflake.
The team also netted serious performance improvements in the speed of historical Fivetran syncing, which went from taking one week to taking two hours, an 84x improvement. This enables historical Fivetran re-syncs without maxing out resources on live databases and impacting performance of the Notion product. They were also able to achieve incremental syncing every four hours using Hudi’s DeltaStreamer. (They even clarified that they could increase the cadence if they wanted to, given the headroom still available in DeltaStreamer, but every four hours meets their needs.) Perhaps the most exciting of the improvements is that the new architecture enables large language model (LLM)-based features that would have been extremely difficult, if not impossible, to implement before the switch.
Nathan, who focuses on data lake ecosystem and AI infrastructure at Notion (particularly AI embeddings), explained how the universal data lake architecture unlocked new innovation: the Q&A AI. Notion’s Q&A AI is a feature that enables users to ask Notion AI questions via chat interface, and get responses based on the entire content of their (or their team’s) Notion pages and databases.
To reference the right documents in a team or user’s Notion workspace when answering with the AI, the team needed to have a vector database to store the embeddings (representations of chunks of text in a high-dimensional vector space). Then, they could look up relevant text to feed into the large language model’s context to answer the user. There were two ways that data needed to be generated:
However, as Thomas had touched on several times already, Notion had a lot of documents and Blocks, and thus, a lot of data. Luckily, with the adoption of Hudi, this data scale became manageable, as shown in Figure 6.

Hudi made things manageable, Nathan explained, by enabling the team to define large, flexible processing jobs, which had been much more challenging with Fivetran and Snowflake. Additionally, the four-hour sync cadence Hudi enabled served the team well here, because once the offline batch processing was done, the online “catchup period” to sync any newer live data was within a day. This ensures that the data lakehouse can never become too far out of sync with the production database. In short, it became now possible to quickly and cost-effectively process nearly all the data in Notion’s data lake — a must-have to enable Notion AI.
In their discussion of the journey of Notion’s data infrastructure scaling, growing 10x in just three years and needing to meet new demands, Thomas and Nathan touched on a wide range of insights and experiences. This included everything from scaling their database systems and inventing (and then re-inventing) their data lake architecture, to enabling new and previously infeasible product features based on those innovations. They also identified the benefits of Hudi’s lakehouse architecture for their data infrastructure, noting the cost savings of over a million dollars, and performance improvements Hudi garnered for Notion. If you’re curious and want to dig into the details of their implementation or their insights, please check out the full talk.
Be the first to read new posts






